MapReduce: Simplified Data Processing on Large Clusters
Table of Contents
http://research.google.com/archive/mapreduce.html @ 2004
https://pdos.csail.mit.edu/6.824/notes/l01.txt
1. Abstract
2. Introduction
3. Programming Model
The computation takes a set of input key/value pairs, and produces a set of output key/value pairs. The user of the MapReduce library expresses the computation as two functions: Map and Reduce.
Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
对于reduce阶段处理的values是以iterator形式提供的,这样可以不用担心values过多放不进入内存
The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user's reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
Map/Reduce的输入输出类型是:
- Map (k1, v1) -> list(k2, v2)
- Reduce (k2, list(v2)) -> list(v3)
4. Implementation
Many different implementations of the MapReduce in-terface are possible. The right choice depends on the environment. For example, one implementation may be suitable for a small shared-memory machine, another for a large NUMA multi-processor, and yet another for an even larger collection of networked machines.(mapreduce可以有很多实现,这个取决于环境。)
This section describes an implementation targeted to the computing environment in wide use at Google: large clusters of commodity PCs connected together with switched Ethernet . In our environment:
- (1) Machines are typically dual-processor x86 processors running Linux, with 2-4 GB of memory per machine.(双核x86,2-4GB内存)
- (2) Commodity networking hardware is used – typically either 100 megabits/second or 1 gigabit/second at the machine level, but averaging considerably less in over-all bisection bandwidth.(单机上是1Gbps的网卡,但是外层的交换机上存在带宽限制,所以通常单机是跑不满的)
- (3) A cluster consists of hundreds or thousands of ma-chines, and therefore machine failures are common.(考虑机器故障)
- (4) Storage is provided by inexpensive IDE disks at-tached directly to individual machines. A distributed file system developed in-house is used to manage the data stored on these disks. The file system uses replication to provide availability and reliability on top of unreliable hardware.(使用廉价IDE磁盘,但是应该没有使用磁盘阵列,而是使用gfs做soft RAID)
- (5) Users submit jobs to a scheduling system. Each job consists of a set of tasks, and is mapped by the scheduler to a set of available machines within a cluster.(用户提交到scheduler system,scheduler来指定job在哪些机器运行,每个job包含很多task. Borg/Omega/k8s etc)
Execution Overview
The Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits. The input splits can be pro-cessed in parallel by different machines. (框架自动将输入数据拆分成为M份,每个mapper实例处理一份,分布在各个机器上面且可以同时运行。对于这个M没有办法指定)
Reduce invoca-tions are distributed by partitioning the intermediate key space into R pieces using a partitioning function (e.g.,hash(key) mod R). The number of partitions (R) and the partitioning function are specified by the user.(reducer的实例个数可以指定,分布在各个机器上面处理落到这个reducer上面所有的key/value pairs。其中partition函数用户可以指定)
整个工作逻辑是:
- The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (con-trollable by the user via an optional parameter). It then starts up many copies of the program on a clus-ter of machines.(根据输入文件大小,按照每个block 16-64M这个数值用户可以指定,来进行切分。这个数目就是mapper实例个数)
- One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.(所有的都是worker,其中一个worker比较特殊成为master,工作是将mapper/reducer指派到worker上面去,并且监控mapper/reducer的运行情况)
- A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The interme-diate key/value pairs produced by the Map function are buffered in memory.(分配到mapper工作的worker读取对应的数据并且进行解析,将解析的结果丢给map函数处理。输出结果会缓存起来而不是立刻输出)
- Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.(mapper缓存的结果周期性地写到本地磁盘,并且是根据partition函数写成R份。mapper将磁盘地址通知给master,一方面是通知完成,另外一方面master可以通知reducer拉数据)
- When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all in-termediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.(之后reducer会被master通知到mapper输出结果地址。reducer使用RPC将结果copy到本地。一旦reducer读取到所有的文件之后,就会进行排序。如果内存排序不行的话,那么就会使用外部排序)
- The reduce worker iterates over the sorted interme-diate data and for each unique intermediate key en-countered, it passes the key and the corresponding set of intermediate values to the user’s Reduce func-tion. The output of the Reduce function is appended to a final output file for this reduce partition.(reducer将同一个key对应的values传递给指定的reduce函数)
- When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user pro-gram returns back to the user code.(当所有的task完成之后,master就会返回到user code)
- After successful completion, the output of the mapre-duce execution is available in the R output files (one per reduce task, with file names as specified by the user). Typically, users do not need to combine these R output files into one file – they often pass these files as input to another MapReduce call, or use them from another dis-tributed application that is able to deal with input that is partitioned into multiple files.(输出结果有R份,我们并不需要进行merge,通常这些结果会作为下一轮mapreduce的输入)
Master Data Structures
master维护的数据结构之需要包括
- 每个task的状态(idle/in-progress/completed)
- 每个mapper的R份输出文件名称以及文件大小
- 对于一个mapper如果一旦有R份输出文件的话,那么就可以认为这个mapper运行完成。
- mapper的输出会被推送到reducer上(或许是piggyback到reducer上?)
Fault Tolerance
Worker Failure: 检测worker故障是通过周期性ping来完成的。如果检测到worker失败的话:
- 如果是mapper的话,那么无论如何都需要重新启动这个mapper任务(将状态修改为idle),因为mapper输出结果在本地文件
- 如果是reducer的话,如果completed的话那么不需要重新执行,因为输出文件在gfs。否则也需要重启(修改为idle状态)
- 如果是mapper重新计算的话,那么mapper也会同时reducer输出文件地址变化。如果reducer之前没有拉下数据的话,那么就在新的mapper机器上拉数据
Master Failure: 对于master来说可以定时地做chkp来记录自己的信息,如果挂掉的话那么可以重启来恢复之前执行情况。但是考虑到job只有一个master,挂掉几率非常小,因为可以简单地abort job,通知用户重新执行。
当mapper完成时候会一次将所有的R个输出文件通知给master。因为mapper是写本地文件,所以如果有两个相同mapper运行且同时完成,master只取其中一份即可。对于reducer来说的话,因为是将输出写到gfs上面,所以需要提供文件写原子操作。实现上可以让reducer写临时文件,然后使用提供的atomic rename操作重命名。但是如果mapper/reducer中包含不确定性操作的话,那么就会存在一定的不一致性。比如R1可能读取了M1的部分数据,而R2读取的是M1'(M1再次执行的)的部分数据。如果这里强调一致性的话,那么就必须确保mapper/reducer的操作是确定性的。
Semantics in the Presence of Failures.
- When the map and/or reduce operators are non-deterministic, we provide weaker but still reasonable se-mantics. In the presence of non-deterministic operators, the output of a particular reduce task R1 is equivalent to the output for R1 produced by a sequential execution of the non-deterministic program. However, the output for a different reduce task R2 may correspond to the output for R2 produced by a different sequential execution of the non-deterministic program.
- Consider map task M and reduce tasks R1 and R2. Let e(Ri) be the execution of Ri that committed (there is exactly one such execution). The weaker semantics arise because e(R1 ) may have read the output produced by one execution of M and e(R2) may have read the output produced by a different execution of M.
Locality
master在选择mapper启动位置的话,会优先考虑将mapper启动到离input data近的机器上面(如果是本地的话就可以节省网络带宽),这也是为了配合GFS才这么做的。
The MapReduce master takes the location information of the input files into account and attempts to schedule a map task on a machine that contains a replica of the corresponding input data. Failing that, it attempts to schedule a map task near a replica of that task's input data (e.g., on a worker machine that is on the same network switch as the machine containing the data). When running large MapReduce operations on a significant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth.
Task Granularity
任务粒度上要保证tasks数量比worker数量多,应该多一个数量级会比较合适。这样如果某个worker上的tasks失败的话,那么这些tasks也可以被平均地分布在其他worker上,对负载均衡很有帮助。但是这个数量不能无限大,因为master需要维护的数据结构大小是O(M*R)的,虽然每个pair大约只需要1个字节来存储状态(R是否接受到了来自M的输入,我觉得是这个信息吧)
We subdivide the map phase into M pieces and the reduce phase into R pieces, as described above. Ideally,M and R should be much larger than the number of worker machines. Having each worker perform many different tasks improves dynamic load balancing, and also speeds up recovery when a worker fails: the many map tasks it has completed can be spread out across all the other worker machines.
There are practical bounds on how largeM and R can be in our implementation, since the master must make O(M + R) scheduling decisions and keeps O(M*R) state in memory as described above. (The constant factors for memory usage are small however: the O(M*R) piece of the state consists of approximately one byte of data per map task/reduce task pair.)
Backup Tasks
straggler表示有某一个机器花去非常多的时间完成了最后一个mapper或者是reducer任务,使得整个任务运行时间延长。产生拖延的原因有很多包括硬件故障和资源不足。
One of the common causes that lengthens the total time taken for a MapReduce operation is a “straggler”: a ma-chine that takes an unusually long time to complete one of the last few map or reduce tasks in the computation. Stragglers can arise for a whole host of reasons. For ex-ample
- a machine with a bad disk may experience fre- quent correctable errors that slow its read performance from 30 MB/s to 1 MB/s. (磁盘故障)
- The cluster scheduling sys-tem may have scheduled other tasks on the machine, causing it to execute the MapReduce code more slowly due to competition for CPU, memory, local disk, or net-work bandwidth.(并且如果过多的任务在这个机器上的话,那么因为CPU,mem,network的竞争使用会变得更慢)
- A recent problem we experienced was a bug in machine initialization code that caused proces-sor caches to be disabled: computations on affected ma-chines slowed down by over a factor of one hundred.(最近遇到的鼓掌机器代码使得CPU cache失效,使得运行速度降低1/100)
解决这个问题就是当task快完成的时候,启动一个backup task同时运行,看哪个首先完成。事实证明这个机制并不会浪费太多计算资源,而如果不开启的话执行时间会延长44%.
When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks. The task is marked as completed whenever either the primary or the backup execution completes. We have tuned this mechanism so that it typically increases the computational resources used by the operation by no more than a few percent.(调节这个机制使得计算资源并不会浪费太多) As an exam-ple, the sort program described in Section 5.3 takes 44% longer to complete when the backup task mechanism is disabled.
5. Refinements
Partitioning Function
Ordering Guarantees
We guarantee that within a given partition, the intermediate key/value pairs are processed in increasing key order. This ordering guarantee makes it easy to generate a sorted output file per partition, which is useful when the output file format needs to support efficient random access lookups by key, or users of the output find it convenient to have the data sorted.
Combiner Function
combiner可以使得在mapper本地就进行一些reducer操作。通常这些操作可以使得输出减少很多,这样reducer可以节省带宽。
- The Combiner function is executed on each machine that performs a map task.
- Typically the same code is used to implement both the combiner and the reduce func-tions. (combiner和reducer使用相同的reduce代码)
- The only difference between a reduce function and a combiner function is how the MapReduce library han-dles the output of the function. The output of a reduce function is written to the final output file. The output of a combiner function is written to an intermediate file that will be sent to a reduce task.(唯一差别在于combiner写入本地文件,而reducer写入gfs)
Input and Output Types
Side-effects
MapReduce框架对side-effects没有任何支持,用户代码自己去保证外部一致性。
In some cases, users of MapReduce have found it convenient to produce auxiliary files as additional outputs from their map and/or reduce operators. We rely on the application writer to make such side-effects atomic and idempotent.
Typically the application writes to a temporary file and atomically renames this file once it has been fully generated. We do not provide support for atomic two-phase commits of multiple output files produced by a single task. Therefore, tasks that produce multiple output files with cross-file consistency requirements should be deterministic. This restriction has never been an issue in practice.
Skipping Bad Records
产生Bad Records的原因可能某些buggy的代码或者是协议不兼容。通常也没有办法删除它,所以只能忽略掉:
- 针对每条记录,都将记录的seqnum记录在一个全局变量里面
- Each worker process installs a signal handler that catches segmentation violations and bus errors.(安装segfault的sighandler)
- 如果出现错误的话,那么在sighandler里面将这个seqnum作为UDP packet发送给master
- 如果master连续收到两次相同seqnum的话,那么就会告诉worker忽略seqnum这条记录。
Local Execution 方便调试以及测试。
Status Information
提供http接口返回当前master状态,信息包括下面这些:
- The sta-tus pages show the progress of the computation, such as (计算进度)
- how many tasks have been completed, (当前多少个任务完成)
- how many are in progress, (多少任务正在运行)
- bytes of input, (输入多少个字节)
- bytes of intermediate data, (中间数据多少字节)
- bytes of output, (输出多少字节)
- processing rates, etc.(处理速率)
- The pages also contain links to the standard error and standard output files gen-erated by each task.(标准输出和错误)
- The user can use this data to pre-dict how long the computation will take, and whether or not more resources should be added to the computation.These pages can also be used to figure out when the com-putation is much slower than expected. (用户可以分析出计算大概需要多长时间完成,是否需要添加新的资源,以及找出计算慢的原因)
- In addition, the top-level status page shows
- which workers have failed, and (哪些worker失败)
- which map and reduce tasks they were processing when they failed. (为什么失败)
Counters
关于这些counter都是在ping response时候捎带回去给master的,counter应该是对应到每个mapper/reducer上的,然后聚合起来返回。如果mapper/reducer重启或者是有backup task的话,那么会进行去重。
The counter values from individual worker machines are periodically propagated to the master (piggybacked on the ping response). When aggre-gating counter values, the master eliminates the effects of duplicate executions of the same map or reduce task to avoid double counting. (Duplicate executions can arise from our use of backup tasks and from re-execution of tasks due to failures.
Users have found the counter facility useful for sanity checking the behavior of MapReduce operations. For example, in some MapReduce operations, the user code may want to ensure that the number of output pairs produced exactly equals the number of input pairs processed, or that the fraction of German documents processed is within some tolerable fraction of the total number of documents processed.
6. Performance
7. Experience
- We wrote the first version of the MapReduce library in February of 2003, and made significant enhancements to it in August of 2003, including the locality optimization, dynamic load balancing of task execution across worker machines, etc. (03年二月份完成,03年8月份将本地优化,动态负载均衡加入)
- It has been used across a wide range of domains within Google, including:
- large-scale machine learning problems,(机器学习)
- clustering problems for the Google News and Froogle products,
- extraction of data used to produce reports of popular queries (e.g. Google Zeitgeist),
- extraction of properties of web pages for new exper-iments and products (e.g. extraction of geographi-cal locations from a large corpus of web pages for localized search), and
- large-scale graph computations.(大规模图计算)
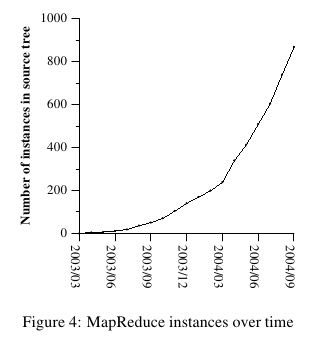
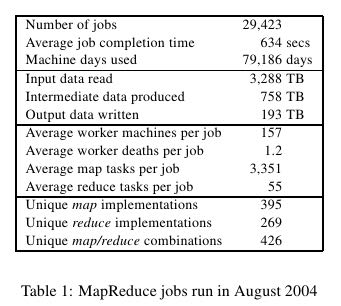
在2004.9月份达到了900个mapreduce程序。下面是2004.8里面部分mapreduce程序运行数据。
改写了线上索引程序,处理文档大小在20TB,大约使用了5~10个mapreduce程序。带来效果是这样的:
- 代码少了很多,比如很多错误恢复代码。(通信代码应该没有太大节省,因为google库本身就应该比较完善)。其中一个计算过程的代码从3800掉至700行。
- 可以更加注重逻辑,因为计算过程被分离出来了。原来改造index系统需要几个月的时间,现在几天就可以完成。
- 整个过程控制更加简单,因为错误恢复,slow machine带来的影响,以及网络抖动都被framework处理了而不需要人工操作。
8. Related Work
Our locality optimization draws its inspiration from techniques such as active disks [12, 15], where computation is pushed into processing elements that are close to local disks, to reduce the amount of data sent across I/O subsystems or the network. We run on commodity processors to which a small number of disks are directly connected instead of running directly on disk controller processors, but the general approach is similar.
The MapReduce implementation relies on an in-house cluster management system that is responsible for distributing and running user tasks on a large collection of shared machines. Though not the focus of this paper, the cluster management system is similar in spirit to other systems such as Condor [16].
9. Conclusions
We have learned several things from this work.(从中得到的经验):
- First, restricting the programming model makes it easy to par-allelize and distribute computations and to make such computations fault-tolerant. (限制编程模型能够使得并行化以及错误容忍处理更加简单)
- Second, network bandwidth is a scarce resource. A number of optimizations in our system are therefore targeted at reducing the amount of data sent across the network: the locality optimization al-lows us to read data from local disks, and writing a single copy of the intermediate data to local disk saves network bandwidth. (带宽是比较稀缺的资源,比如mapper考虑从local读取,并且写入本地磁盘,同时reduce也是拉到本地磁盘做排序)
- Third, redundant execution can be used to reduce the impact of slow machines, and to handle ma-chine failures and data loss.(冗余执行可以减少慢机器带来的影响,且能够用来处理机器故障和数据丢失)