Large-Scale Deep Learning for Intelligent Computer Systems
用大规模的深度学习来构建智能计算机系统
DL在Google内部大行其道,遍布各个产品线。也说明了产品往后发展也会越来越更加智能。
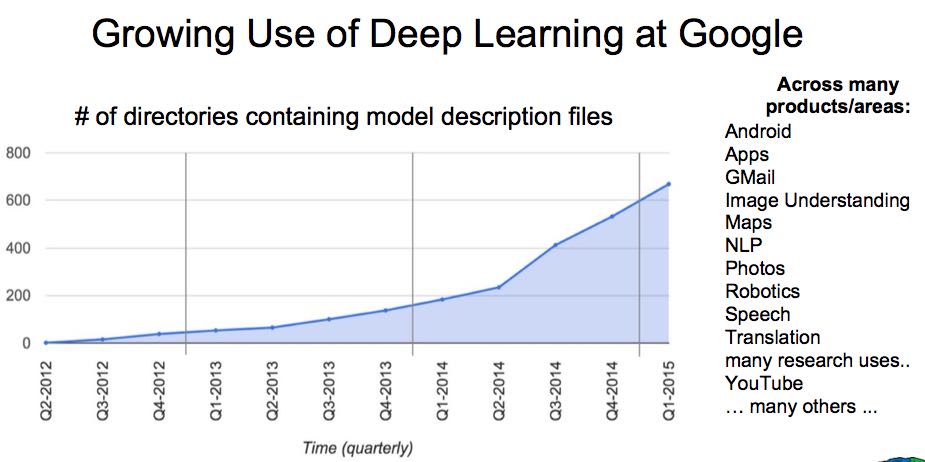
G内部有两代深度学习系统
Two generations of deep learning software systems:
- 1st generation: DistBelief [Dean et al., NIPS 2012].
- 2nd generation: TensorFlow (unpublished)
An overview of how we use these in research and products Plus, …a new approach for training (people, not models)
第二代系统相比第一代更加侧重: 1. 支持更大的计算量 2. 支持更大的数据量(文字,图片,声音,日志,知识图谱)
- Text: trillions of words of English + other languages
- Visual data: billions of images and videos
- Audio: tens of thousands of hours of speech per day
- User activity: queries, marking messages spam, etc.
- Knowledge graph: billions of labelled relation triples
Parallelism
Model Parallelism + Data Parallelism.
Model并行化和DL网络结构相关,比如CNN里面的Local Receptive Field就决定了Model Parallelism是可行的。
Data Parallelism可以通过类似Parameter Server的方案来解决
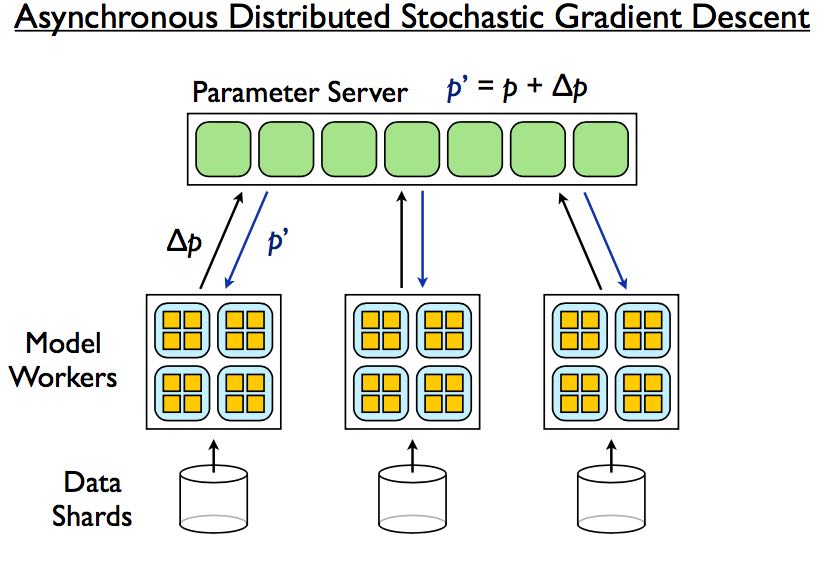
Can do this synchronously:
- N replicas eqivalent to an N times larger batch size
- Pro: No noise
- Con: Less fault tolerant (requires recovery if any single machine fails)
Can do this asynchronously:
- Con: Noise in gradients
- Pro: Relatively fault tolerant (failure in model replica doesn’t block other replicas)
(Or hybrid: M asynchronous groups of N synchronous replicas)
后面还有一些Google在DL方面取得的成果,以及Tensorflow的介绍