Large-Scale Data and Computation: Challenges and Opportunities
Table of Contents
1. Replication
replication对于large-scale system的意义
- Data loss 数据备份
- replicate the data on multiple disks/machines (GFS/Colossus)
- Slow machines 慢速机器 – replicate the computation (MapReduce)
- Too much load 负载过高
- replicate for better throughput (nearly all of our services)
- Bad latency 高延迟
- utilize replicas to improve latency
- improved worldwide placement of data and services
这些问题都可以通过合理的replication来解决。
2. Shared Environment
large-scale system都采用共享环境,有利也有弊
- Huge benefit: greatly increased utilization 优点是带来了比较高的集群利用率
- … but hard to predict effects increase variability 但是变化比较大难以预测影响
- network congestion
- background activities
- bursts of foreground activity
- not just your jobs, but everyone else’s jobs, too
- not static: change happening constantly
- Exacerbated by large fanout systems

3. Tolerating Faults vs.Tolerating Variability
容忍错误和可变性的相似之处,都需要使用额外资源来解决。解决思路都是在unpredictable parts上面构建出predictable part. 两者的差别是时间范围,faults通常在10s/day. 而variability通常在1000s/sec.
- Tolerating faults:
- rely on extra resources
- RAIDed disks, ECC memory, dist. system components, etc. – make a reliable whole out of unreliable parts
- rely on extra resources
- Tolerating variability:
- use these same extra resources
- make a predictable whole out of unpredictable parts
- Times scales are very different:
- variability: 1000s of disruptions/sec, scale of milliseconds
- faults: 10s of failures per day, scale of tens of seconds
4. Latency Tolerating Techniques
延迟容忍技术主要有下面两种,单位是request.
- Cross request adaptation 一种方式是跨request的,检查最近request的行为,时间范围在10s到分钟级别
- examine recent behavior
- take action to improve latency of future requests
- typically relate to balancing load across set of servers
- time scale: 10s of seconds to minutes
- Within request adaptation 一种是在request内部的
- cope with slow subsystems in context of higher level request
- time scale: right now, while user is waiting
- Many such techniques
- [The Tail at Scale, Dean & Barroso, to appear in CACM Feb. 2013]
- Tied Requests 这种方式非常简单,就是同时发送request到多个replica上面,如果某个replica开始执行的话,那么这个replica直接取消其他replica上的请求。 note:实现上是否会复杂?由replica直接取消其他replica上的request感觉会复杂化设计
5. Cluster-Level Services
提供cross-cluster的服务,比如spanner系统
Our earliest systems made things easier within a cluster:
- GFS/Colossus: reliable cluster-level file system
- MapReduce: reliable large-scale computations
- Cluster scheduling system: abstracted individual machines
- BigTable: automatic scaling of higher-level structured storage
Solve many problems, but leave many cross-cluster issues to human-level operators
- different copies of same dataset have different names
- moving or deploying new service replicas is labor intensive
Spanner:Worldwide Storage
6. Higher Level Systems
有了这些"just works"的抽象组件(GFS, MapReduce, BigTable, Spanner, tied requests, etc.)后,我们就能开搞更加牛X的东西比如深度学习。
Parameter Server用于实现异步分布式随机梯度下降.
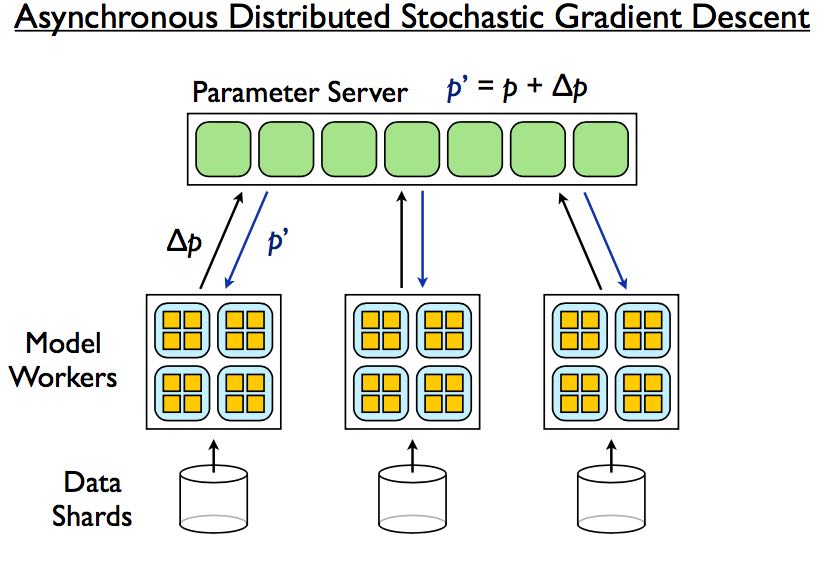
实现这种深度学习系统里面也有许多有意思的tradeoff
- Use lower precision arithmetic
- Send 1 or 2 bits instead of 32 bits across network
- Drop results from slow partitions