Kafka: a Distributed Messaging System for Log Processing
Table of Contents
- http://incubator.apache.org/kafka/
- http://research.microsoft.com/en-us/um/people/srikanth/netdb11/netdb11papers/netdb11-final12.pdf
1. ABSTRACT
2. Introduction
- Many early systems for processing this kind of data relied on physically scraping log files off production servers for analysis. In recent years, several specialized distributed log aggregators have been built, including Facebook’s Scribe , Yahoo’s Data Highway , and Cloudera’s Flume. Those systems are primarily designed for collecting and loading the log data into a data warehouse or Hadoop for offline consumption. (一些现有的日志系统都是非实时系统,将数据导入到数据仓库或是Hadoop做离线处理)
- At LinkedIn (a social network site), we found that in addition to traditional offline analytics, we needed to support most of the real-time applications mentioned above with delays of no more than a few seconds.(kafka主要用来针对日志做实时分析和在线处理的)
- On the one hand, Kafka is distributed and scalable, and offers high throughput. (分布式,可扩展,高吞吐的架构)
- On the other hand, Kafka provides an API similar to a messaging system and allows applications to consume log events in real time.(提供类似消息系统的API)
3. Related Work
- Traditional enterprise messaging systems have existed for a long time and often play a critical role as an event bus for processing asynchronous data flows. However, there are a few reasons why they tend not to be a good fit for log processing. (传统的消息系统不适合做日志处理)
- First, there is a mismatch in features offered by enterprise systems. Those systems often focus on offering a rich set of delivery guarantees. Such delivery guarantees are often overkill for collecting log data. For instance, losing a few pageview events occasionally is certainly not the end of the world. Those unneeded features tend to increase the complexity of both the API and the underlying implementation of those systems.(企业系统提供了一些无用的特性,并且这些特性复杂了API以及底层实现)
- Second, many systems do not focus as strongly on throughput as their primary design constraint.(不强调吞吐)
- Third, those systems are weak in distributed support. There is no easy way to partition and store messages on multiple machines.(分布式支持不太好)
- Finally, many messaging systems assume near immediate consumption of messages, so the queue of unconsumed messages is always fairly small. Their performance degrades significantly if messages are allowed to accumulate, as is the case for offline consumers such as data warehousing applications that do periodic large loads rather than continuous consumption. (不能够支持存储时间过长的历史数据)
- A number of specialized log aggregators have been built over the last few years.
- Facebook uses a system called Scribe. Each frontend machine can send log data to a set of Scribe machines over sockets. Each Scribe machine aggregates the log entries and periodically dumps them to HDFS or an NFS device.
- Yahoo’s data highway project has a similar dataflow. A set of machines aggregate events from the clients and roll out “minute” files, which are then added to HDFS.
- Flume is a relatively new log aggregator developed by Cloudera. It supports extensible “pipes” and “sinks”, and makes streaming log data very flexible. It also has more integrated distributed support
- However, most of those systems are built for consuming the log data offline, and often expose implementation details unnecessarily (e.g. “minute files”) to the consumer(只是比较适合离线处理)
- Additionally, most of them use a “push” model in which the broker forwards data to consumers.(并且使用的都是push模型)
- At LinkedIn, we find the “pull” model more suitable for our applications since each consumer can retrieve the messages at the maximum rate it can sustain and avoid being flooded by messages pushed faster than it can handle. The pull model also makes it easy to rewind a consumer(使用pull模型能够由client来控制速率,并且能够很容易地由client做rewind)
4. Kafka Architecture and Design Principles
- We first introduce the basic concepts in Kafka
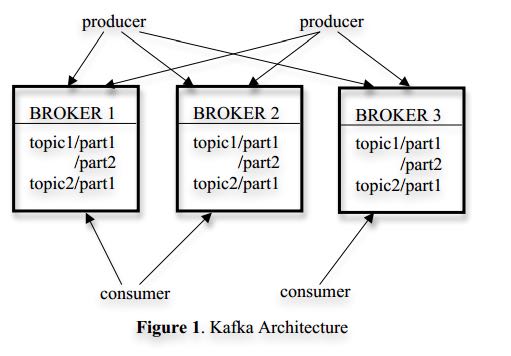
- A stream of messages of a particular type is defined by a topic.
- A producer can publish messages to a topic.
- The published messages are then stored at a set of servers called brokers.
- A consumer can subscribe to one or more topics from the brokers, and consume the subscribed messages by pulling data from the brokers.
- Each message stream provides an iterator interface over the continual stream of messages being produced. The consumer then iterates over every message in the stream and processes the payload of the message.
- Unlike traditional iterators, the message stream iterator never terminates. If there are currently no more messages to consume, the iterator blocks until new messages are published to the topic.(以iterators方式提供消息)
- We support both the point-topoint delivery model in which multiple consumers jointly consume a single copy of all messages in a topic, as well as the publish/subscribe model in which multiple consumers each retrieve its own copy of a topic.(多个consumer可以共同消费一份,或者是各自消费一份)
- Since Kafka is distributed in nature, an Kafka cluster typically consists of multiple brokers. To balance load, a topic is divided into multiple partitions and each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.(一个topic被分割成多个partition, 每个broker上面可以host多个partition)
Producer Code
producer = new Producer(...); message = new Message(“test message str”.getBytes()); set = new MessageSet(message); producer.send(“topic1”, set);
Consumer Code
streams[] = Consumer.createMessageStreams(“topic1”, 1);
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
4.1. Efficiency on a Single Partition
- Simple storage
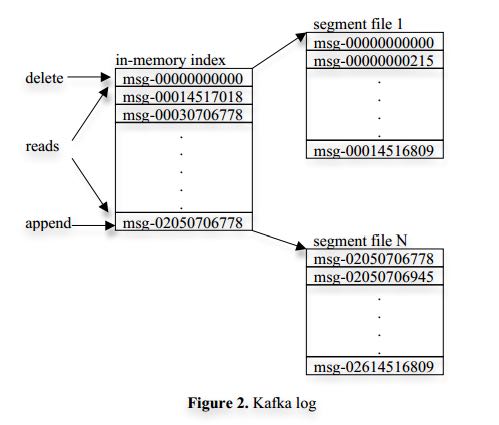
- Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of approximately the same size (e.g., 1GB).(每个partition对应一个logical log, 每个logical log对应多个segment file,这些文件都近似大小) Every time a producer publishes a message to a partition, the broker simply appends the message to the last segment file.(每个追加到最后一个segment file上)
- For better performance, we flush the segment files to disk only after a configurable number of messages have been published or a certain amount of time has elapsed. A message is only exposed to the consumers after it is flushed.(积累到一定的数据量才会进行刷新)
- Unlike typical messaging systems, a message stored in Kafka doesn’t have an explicit message id. Instead, each message is addressed by its logical offset in the log. This avoids the overhead of maintaining auxiliary, seek-intensive random-access index structures that map the message ids to the actual message locations. (没有messageid, 但是可以通过logical offset来定位log. 这样可以免去从message id对应到message这个过程,因为这个过程需要mapping需要random access index. 这样的message id自然不是连续的,但是却是递增的)
- A consumer always consumes messages from a particular partition sequentially. If the consumer acknowledges a particular message offset, it implies that the consumer has received all messages prior to that offset in the partition.(consumer只能通过偏移顺序读取内容) Under the covers, the consumer is issuing asynchronous pull requests to the broker to have a buffer of data ready for the application to consume. Each pull request contains the offset of the message from which the consumption begins and an acceptable number of bytes to fetch.
- Each broker keeps in memory a sorted list of offsets, including the offset of the first message in every segment file. The broker locates the segment file where the requested message resides by searching the offset list, and sends the data back to the consumer. After a consumer receives a message, it computes the offset of the next message to consume and uses it in the next pull request.(每个broker在内存保存各个文件的起始的offset,这样就可以很容易地进行定位)
- Efficient transfer
- Although the end consumer API iterates one message at a time, under the covers, each pull request from a consumer also retrieves multiple messages up to a certain size, typically hundreds of kilobytes.(批量传输)
- Another unconventional choice that we made is to avoid explicitly caching messages in memory at the Kafka layer. Instead, we rely on the underlying file system page cache.(在kafka层面不进行cache,而由system完成page cache简化工作)This has the main benefit of avoiding double buffering—messages are only cached in the page cache. This has the additional benefit of retaining warm cache even when a broker process is restarted. Since Kafka doesn’t cache messages in process at all, it has very little overhead in garbage collecting its memory, making efficient implementation in a VM-based language feasible.(这样也避免了GC带来的额外开销)
- Finally, since both the producer and the consumer access the segment files sequentially, with the consumer often lagging the producer by a small amount, normal operating system caching heuristics are very effective (specifically write-through caching and read- ahead).
- On Linux and other Unix operating systems, there exists a sendfile API that can directly transfer bytes from a file channel to a socket channel.(通过sendfile这个API减少系统调用次数)
- Stateless broker
- However, this makes it tricky to delete a message, since a broker doesn’t know whether all subscribers have consumed the message. Kafka solves this problem by using a simple time-based SLA for the retention policy. A message is automatically deleted if it has been retained in the broker longer than a certain period, typically 7 days. This solution works well in practice.(可以通过保存最近7天的日志来显示删除)
- There is an important side benefit of this design. A consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but proves to be an essential feature for many consumers. (consumer可以指定某个offset然后从这个点开始重新消费数据)
4.2. Distributed Coordination
- Each producer can publish a message to either a randomly selected partition or a partition semantically determined by a partitioning key and a partitioning function.(procuder可以根据指定partition算法或者是随机选择发送到哪个partition. 就现在来说每个partition只能够在某一个broker上面)
- Kafka has the concept of consumer groups. Each consumer group consists of one or more consumers that jointly consume a set of subscribed topics, i.e., each message is delivered to only one of the consumers within the group. Different consumer groups each independently consume the full set of subscribed messages and no coordination is needed across consumer groups.(consumer group可能由多个consumer组成,每个consumer group只能够消费一个或者是多个topic, 而这个topic里面所有的内容会被里面的consumers处理,每个consumer处理部分。不同的group之间没有关系)
- Our first decision is to make a partition within a topic the smallest unit of parallelism. This means that at any given time, all messages from one partition are consumed only by a single consumer within each consumer group. Had we allowed multiple consumers to simultaneously consume a single partition, they would have to coordinate who consumes what messages, which necessitates locking and state maintenance overhead.(每个partition只能够被某一个consumer所消费,不然没有办法决定哪个consumer消费某个partition里面的具体信息)In contrast, in our design consuming processes only need co-ordinate when the consumers rebalance the load, an infrequent event. In order for the load to be truly balanced, we require many more partitions in a topic than the consumers in each group. We can easily achieve this by over partitioning a topic.(通常来说partition的数量要大于consumer数量这样consumer才不会空闲)
- The second decision that we made is to not have a central “master” node, but instead let consumers coordinate among themselves in a decentralized fashion. Adding a master can complicate the system since we have to further worry about master failures. (没有使用master节点来进行coordinate,不然需要考虑matser挂掉的情况) To facilitate the coordination, we employ a highly available consensus service Zookeeper
- Kafka uses Zookeeper for the following tasks:
- detecting the addition and the removal of brokers and consumers
- when each broker or consumer starts up, it stores its information in a broker or consumer registry in Zookeeper.(启动时候在上面进行注册)
- The broker registry contains the broker’s host name and port, and the set of topics and partitions stored on it.(broker注册hostname和port,管理的topics以及partitions)
The consumer registry includes the consumer group to which a consumer belongs and the set of topics that it subscribes to.(consumer注册consumer group,以及订阅的topics)
- Each consumer group is associated with an ownership registry and an offset registry in Zookeeper.
The ownership registry has one path for every subscribed partition and the path value is the id of the consumer currently consuming from this partition(每个订阅partition是一个path, path value是这个consumer id, 这个consumer来消费这个partition的)
- The offset registry stores for each subscribed partition, the offset of the last consumed message in the partition.(记录订阅partition的最后一个offset)
- triggering a rebalance process in each consumer when the above events happen,
- maintaining the consumption relationship and keeping track of the consumed offset of each partition.
- During the initial startup of a consumer or when the consumer is notified about a broker/consumer change through the watcher, the consumer initiates a rebalance process to determine the new subset of partitions that it should consume from.(consumer或者是broker发生变化的话,那么就会触发balance)
- When there are multiple consumers within a group, each of them will be notified of a broker or a consumer change. However, the notification may come at slightly different times at the consumers. So, it is possible that one consumer tries to take ownership of a partition still owned by another consumer. When this happens, the first consumer simply releases all the partitions that it currently owns, waits a bit and retries the rebalance process. In practice, the rebalance process often stabilizes after only a few retries.(可能会出现一些颠簸的情况,但是这个情况最终是会稳定下来的)
- When a new consumer group is created, no offsets are available in the offset registry. In this case, the consumers will begin with either the smallest or the largest offset (depending on a configuration) available on each subscribed partition, using an API that we provide on the brokers.(新增的consume group可以选择最老的点开始读取,也可以选择最新的点开始读取)

4.3. Delivery Guarantees
- In general, Kafka only guarantees at-least-once delivery. Exactly- once delivery typically requires two-phase commits and is not necessary for our applications.(至少保证一次投递)
- Most of the time, a message is delivered exactly once to each consumer group. However, in the case when a consumer process crashes without a clean shutdown, the consumer process that takes over those partitions owned by the failed consumer may get some duplicate messages that are after the last offset successfully committed to zookeeper.(consumer crash然后切换到其他consumer处理的时候,可能会处理相同的数据)
- Kafka guarantees that messages from a single partition are delivered to a consumer in order. However, there is no guarantee on the ordering of messages coming from different partitions.(单个partition里面的数据是确保有序的,而partition之间的数据顺序没有保证)
- To avoid log corruption, Kafka stores a CRC for each message in the log. If there is any I/O error on the broker, Kafka runs a recovery process to remove those messages with inconsistent CRCs. Having the CRC at the message level also allows us to check network errors after a message is produced or consumed.(使用CRC做读取和传输校验)
- If a broker goes down, any message stored on it not yet consumed becomes unavailable. If the storage system on a broker is permanently damaged, any unconsumed message is lost forever. In the future, we plan to add built-in replication in Kafka to redundantly store each message on multiple brokers.(现在broker没有做replication, 也就是说如果down的话那么上面数据读取不到,如果磁盘坏的话那么数据就发生丢失)
5. Kafka Usage at LinkedIn
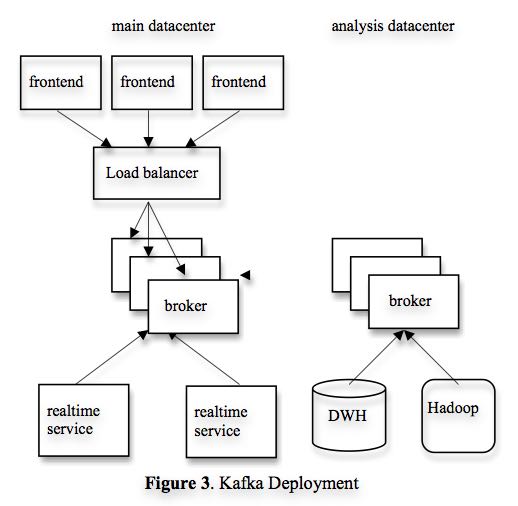
- We rely on a hardware load-balancer to distribute the publish requests to the set of Kafka brokers evenly. (硬件负载均衡)
- We also deploy a cluster of Kafka in a separate datacenter for offline analysis, located geographically close to our Hadoop cluster and other data warehouse infrastructure. Without too much tuning, the end-to-end latency for the complete pipeline is about 10 seconds on average, good enough for our requirements.(跨机房数据延迟在10s以内)
- Our tracking also includes an auditing system to verify that there is no data loss along the whole pipeline.(检验数据是否丢失)
- To facilitate that, each message carries the timestamp and the server name when they are generated. We instrument each producer such that it periodically generates a monitoring event, which records the number of messages published by that producer for each topic within a fixed time window.
- The producer publishes the monitoring events to Kafka in a separate topic. The consumers can then count the number of messages that they have received from a given topic and validate those counts with the monitoring events to validate the correctness of data.
- Loading into the Hadoop cluster is accomplished by implementing a special Kafka input format that allows MapReduce jobs to directly read data from Kafka.
6. Experimental Results
7. Conclusion and Future Works
There are a number of directions that we’d like to pursue in the future.
- First, we plan to add built-in replication of messages across multiple brokers to allow durability and data availability guarantees even in the case of unrecoverable machine failures.(broker replicaiton需要线上,这样可以确保durability以及availability) We’d like to support both asynchronous and synchronous replication models to allow some tradeoff between producer latency and the strength of the guarantees provided. An application can choose the right level of redundancy based on its requirement on durability, availability and throughput. (在replication上面可以选择同步还是异步方式)
- Second, we want to add some stream processing capability in Kafka.(提供一些流式处理方面的能力)
- After retrieving messages from Kafka, real time applications often perform similar operations such as window-based counting and joining each message with records in a secondary store or with messages in another stream.
- At the lowest level this is supported by semantically partitioning messages on the join key during publishing so that all messages sent with a particular key go to the same partition and hence arrive at a single consumer process. This provides the foundation for processing distributed streams across a cluster of consumer machines.
- On top of this we feel a library of helpful stream utilities, such as different windowing functions or join techniques will be beneficial to this kind of applications.
8. Replication Since 0.8
据说从0.8开始支持replication. 粗略地阅读了一下主页上的 documentation , 把一些比较关键东西记录下来。
除了replication之外,提供了两个高级功能:a. Consumer Offset Tracking(记录consumer当前消费位置) b. Log Compaction.(将日志文件中相同key的message进行合并压缩)
replication实现方式大致是这样的:
- 在0.8之前一个topic/partition是由一个broker来进行管理的。这个broker就是master, 它没有任何followers
- 在0.8之后每个topic/partition除了master之外还有followers. 生产者提交数据给主broker, 主broker写入数据后会将数据交给followers. 消费者也是从主brokers来拿数据的。所以这些slaves实际上都是inactive的。
- producers写入数据时候可以指定说,是否写入master就返回,还是必须等待写入k个followers才返回,还是不需要等待master的ack就返回。策略牵扯到latency和durabilityz之间的tradeoff.
- 常见quorum要求,如果集群节点数量为2f+1的话,那么必须得到f+1个节点的相同认定(容忍f个节点失效)。但是kafka quorum不是这样做的,kafka会在保存一个ISR(in-sync replicas)到可能是zookeeper上,这个集合代表当前有哪些节点是处于in-sync状态的。在进行quorum时候只允许ISR里面节点进行投票。和微软 PacificA 一致性协议比较类似,和常见quorum协议差别就在于在更新状态时候保存了ISR。如果节点数量为2f+1的话,那么可以容忍2f个节点失效。
- 如果一个broker挂掉的话,迁移决策过程是由另外一个broker来代理完成的,这个broker称为controller.