Impala: A Modern, Open-Source SQL Engine for Hadoop
系统有这么几个特点:
- 为Hadoop生态设计的SQL引擎,用Java和C++编写
- 和Hadoop许多组件搭配使用:HDFS,HBase,Metastore, Yarn,Sentry
- 能读取许多文件格式:Parquet, Avro, RCFile.
- 数据来源可以是HDFS和HBase,但是主要场景还是HDFS
User View:
- 用户通过SQL进行查询,可以通过JDBC/ODBC连接,使用Kerberos或者是LDAP进行鉴权
- 在创建表的时候指定partition, file path以及file format. 也可以指定某个partition是其他的file format. 比较灵活
- 使用Java/C++来编写UDF,只能使用C++编写UDA(user-defined aggregate function). 性能考虑?
- 现阶段数据库不会自动分析数据分布情况,需要用户手动指定 'COMPUTE STATS <table>'来触发。
架构图如下, 可以分为3个组件:
- Impalad. 查询后台进进程并且负责去将具体的query做fanout. 内部其实有三个功能。部署在HDFS datanode节点上,为的是利用好data locality.
- Catalog. 定期从Hive metastore和HDFS Namenode上去Pull metadata, 并且变为自己的内部格式,然后通过statestore push到Impalad上。此外这上面还会存放数据分布信息,对于优化查询非常有帮助。
- Statestore. 这是一个pub-sub服务,impalad可以去上面订阅自己感兴趣的topic, 主要就是自己关心的metadata. 然后一旦catalog上有变化就会推送到impalad. 这里有个问题就是推送速度差别造成每个impalad上看到的metadata数据可能不同,但是这个没有关系,因为一次Query中使用的metadata只是由query planner(一个节点)决定,将下发的query plan会使用这个query planner看到的metadata, 而不会使用自己节点看到的metadata.
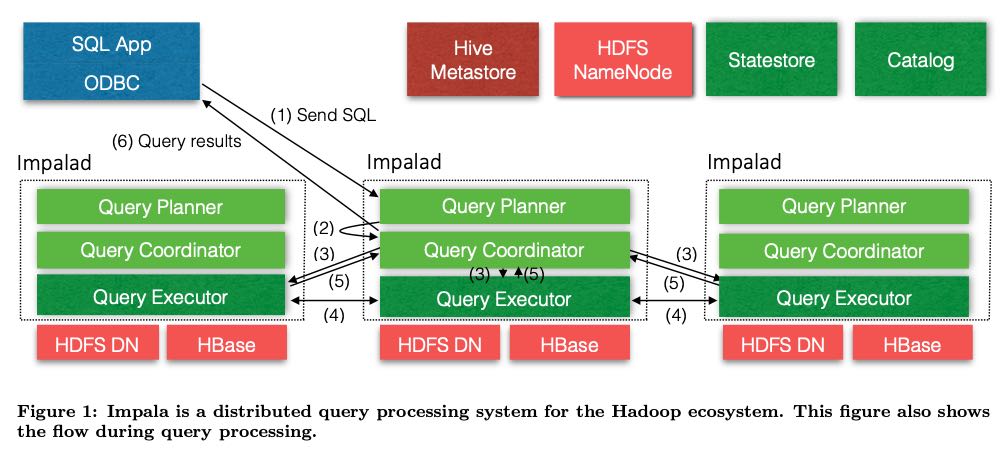
后面主要分析Impalad. 其中Query Planner以及Query Coordinator是算是FrontEnd,而Query Executor是Backend.
FrontEnd拿到SQL之后开始解析并且检查语义是否正确,然后生成Logical & Physical Plan. 这个过程分为两步: 1.生成单机上的执行计划 2. 基于单机上的执行计划拆分成为分布式执行计划。 其中每个分布式执行计划的叶子节点叫做plan fragment, 只能在一个Impalad上面执行,对应Query Executor/Backend部分。
Query Executor有几个特点:
- 使用LLVM动态生成处理代码,如果使用Java编写的话完全可以利用JIT功能
- IO/Management. 包括HDFS short-circuit local reads & caching. 另外有个IO/Manager线程池来负责异步读写,每个HDD分配1个线程,SSD分配8个线程,管理好吞吐
- 支持好几种Storage Formats, 但是性能好还要看Parquet. Parquet支持RLE, dictionary, delta, optimized string encodings, 并且可以内嵌统计数据帮助优化