How Yelp Runs Millions of Tests Every Day
https://engineeringblog.yelp.com/2017/04/how-yelp-runs-millions-of-tests-every-day.html
Seagull(海鸥)这个系统可以让许多test suites可以快速地并行完成,最终加快开发迭代和代码部署速度。
Seagull is built using the following:
- Apache Mesos (manages the resources of our Seagull cluster)
- AWS EC2 (provides the instances that make up the Seagull and Jenkins cluster)
- AWS DynamoDB (stores scheduler metadata)
- Docker (provides isolation for services required by the tests)
- Elasticsearch (tracks test run times and cluster usage data)
- Jenkins (builds code artifacts and runs the Seagull schedulers)
- Kibana and SignalFx (provide monitoring and alerting)
- AWS S3 (serves as the source-of-truth for test logs)
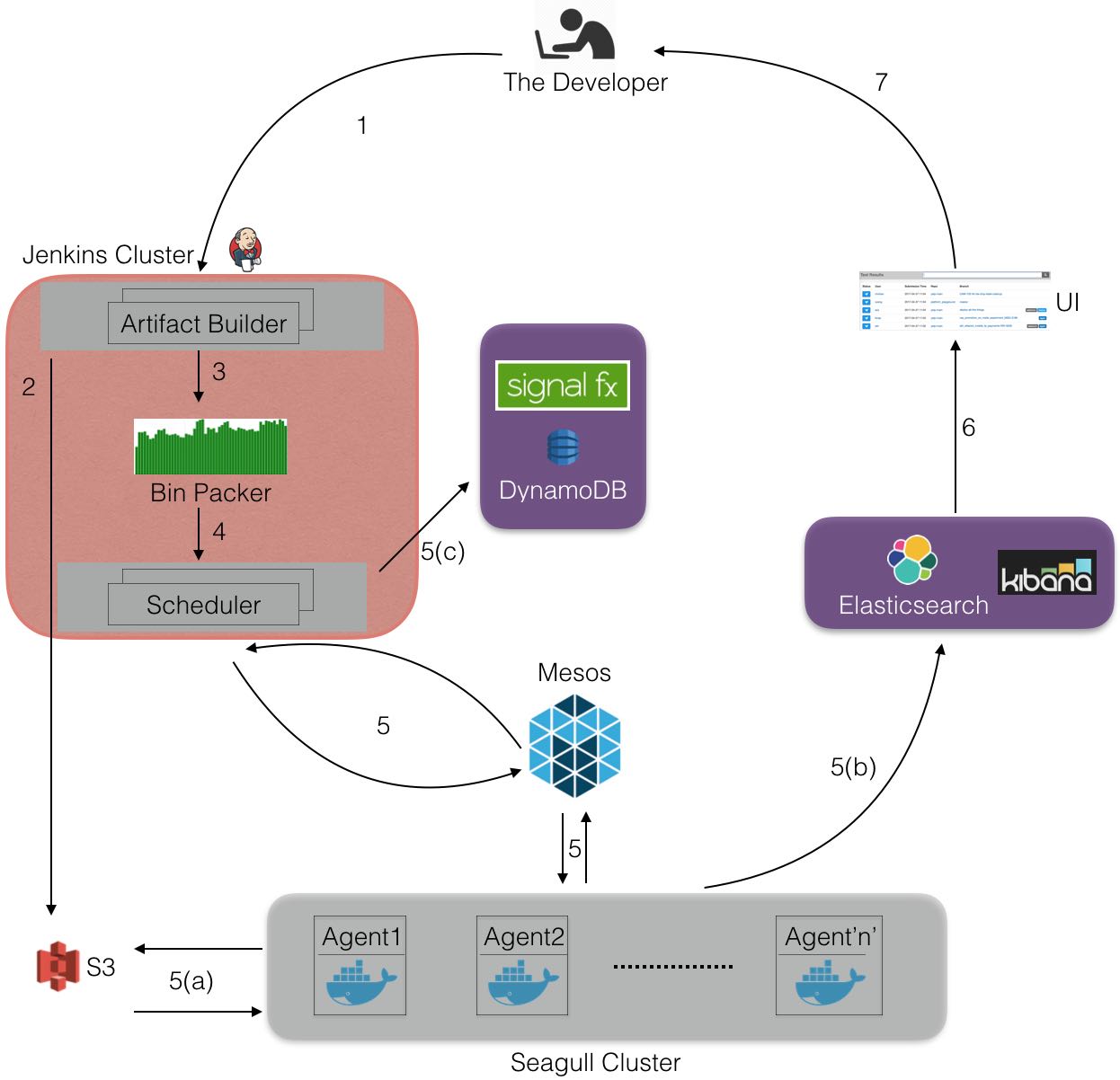
- bin packer 决定需要运行那些test suites
- scheduler 启动mesos, 之后mesos会启动多个executors来执行test suiets
- executor 会从S3上拉取code以及相应的docker运行环境(test bundles)
- 日志数据会写入到Elasticsearch/Kibana上用于分析
- 某些test bundle运行失败的话,会根据DynamoDB上的数据重新调度
There are around 300 seagull-runs every day with 30-40 per hour at peak time. They launch more than 2 million Docker containers in a day. To handle this, we need to have around 10,000 CPU cores in our seagull cluster during peak hours.(可以遇见到在EC2上花费会非常高)
To maintain the timeliness of our test suite, especially at peak hours, we need to have hundreds of instances always available in Seagull Cluster. For a while we were using AWS ASGs with AWS On-Demand Instances but fulfilling this capacity was very expensive for us. (即便使用了ASG + On Deman实例费用依然很高)
To reduce costs, we started using an internal tool, called FleetMiser, to maintain the Seagull Cluster. FleetMiser is an auto-scaling engine which we built to scale a cluster based on different signals such as current cluster utilization, number of runs in pipeline, etc. It has 2 main components:(自研FleeMiser系统根据多种信号来触发Auto Scaling,并且使用的是Spot-Instance)
- AWS Spot Fleet: AWS has Spot Instances which can be consumed at much lower prices than On-Demand instances and Spot Fleet provides an easier interface for using Spot Instances.
- Auto Scaling: Our cluster usage is volatile, with major utilization between 10:00 to 19:00 PST when developers do most of the work. To automatically scale up and down, FleetMiser uses the cluster’s current and historic utilization data with different priorities. Every day the seagull cluster scales up and down between approximately 1,500 cores to 10,000 cores.
FleerMiser saved us ~80% in cluster cost. Before FleetMiser, the cluster was completely on AWS On-Demand Instances with no auto scaling.