Hints for Computer System Design
Table of Contents
- 1. Don’t generalize; generalizations are generally wrong.
- 2. Make it fast, rather than general or powerful.
- 3. Don’t hide power.
- 4. Split resources in a fixed way if in doubt, rather than sharing them.
- 5. Safety first.
- 6. Shed load to control demand, rather than allowing the system to become overloaded.
- 7. End-to-end.
Designing a computer system is very different from designing an algorithm: (设计计算机系统和设计算法有很大的差别)
- The external interface (that is, the requirement) is less precisely defined, more complex, and more subject to change.
- The system has much more internal structure, and hence many internal interfaces.
- The measure of success is much less clear.
所以作者之后很谦虚地说文章的内容都并不是形式化或者是可以被证明的。但是考虑到作者里面做了这么多项目以及拿了图灵奖,里面观点应该是经过验证的。
作者后面所有的观点按照两个维度做了划分:Why?和Where?以及每个交叉点配了几个slogan. Why?涉及到功能,速度和容错,Where?涉及到完整性,接口和实现。
- Why it helps in making a good system: with functionality (does it work?), speed (is it fast enough?), or fault-tolerance (does it keep working?).
- Where in the system design it helps: in ensuring completeness, in choosing interfaces, or in devising implementations.
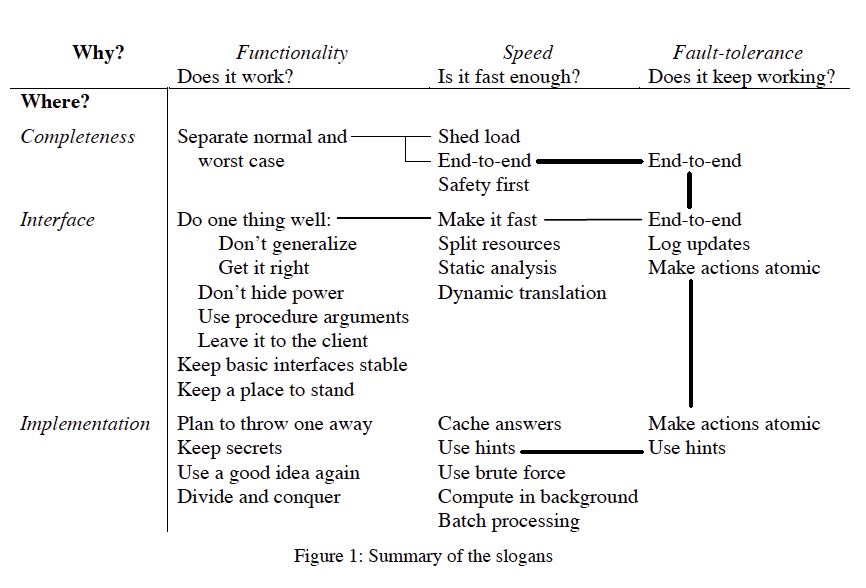
我没有特别多的精力来阅读这篇文章,而且是线性地阅读下来,所以没有像作者这样认真考虑每个slogan之间的相互关系。 我把作者里面写的bulletpoints列举在这里,在有些点的后面增加一些补充和说明。
1. Don’t generalize; generalizations are generally wrong.
When an interface undertakes to do too much its implementation will probably be large, slow and complicated. An interface is a contract to deliver a certain amount of service; clients of the interface depend on the contract, which is usually documented in the interface specification. They also depend on incurring a reasonable cost (in time or other scarce resources) for using the interface; the definition of ‘reasonable’ is usually not documented anywhere. If there are six levels of abstraction, and each costs 50% more than is ‘reasonable’, the service delivered at the top will miss by more than a factor of 10.(泛化接口对应的实现很可能会更加复杂,或者是速度更慢。客户没有办法可以很容易地依赖你这个接口)
Thus, service must have a fairly predictable cost, and the interface must not promise more than the implementer knows how to deliver. Especially, it should not promise features needed by only a few clients, unless the implementer knows how to provide them without penalizing others. A better implementer, or one who comes along ten years later when the problem is better understood, might be able to deliver, but unless the one you have can do so, it is wise to reduce your aspirations.(你提供的接口需要有一定的性能保证,这点在设计接口的时候就要考虑进去)
Of course, these observations apply most strongly to interfaces that clients use heavily, such as virtual memory, files, display handling, or arithmetic. It is all right to sacrifice some performance for functionality in a seldom used interface such as password checking, interpreting user commands, or printing 72 point characters. (What this really means is that though the cost must still be predictable, it can be many times the minimum achievable cost.) And such cautious rules don’t apply to research whose object is learning how to make better implementations. But since research may well fail, others mustn’t depend on its success.(上面的观点仅仅是对客户重度依赖的接口适用。如果不是关键接口 或者说这个项目只是实验性质的话,那么不用考虑这个问题)
2. Make it fast, rather than general or powerful.
If it’s fast, the client can program the function it wants, and another client can program some other function. It is much better to have basic operations executed quickly than more powerful ones that are slower (of course, a fast, powerful operation is best, if you know how to get it). The trouble with slow, powerful operations is that the client who doesn’t want the power pays more for the basic function. Usually it turns out that the powerful operation is not the right one.(给用户提供快速且简单的接口,而不是强大但是低效的接口。这点也是CISC和RISC的设计哲学分歧, 虽然工业界CISC/intel获胜,但是RISC其实已经被学界和业界所接受了,以至于Intel芯片内部其实也是RISC化的)
For example, many studies (such as [23, 51, 52]) have shown that programs spend most of their time doing very simple things: loads, stores, tests for equality, adding one. Machines like the 801 [41] or the RISC [39] with instructions that do these simple operations quickly can run programs faster (for the same amount of hardware) than machines like the VAX with more general and powerful instructions that take longer in the simple cases. It is easy to lose a factor of two in the running time of a program, with the same amount of hardware in the implementation. Machines with still more grandiose ideas about what the client needs do even worse [18].
3. Don’t hide power.
This slogan is closely related to the last one. When a low level of abstraction allows something to be done quickly, higher levels should not bury this power inside something more general. The purpose of abstractions is to conceal undesirable properties; desirable ones should not be hidden. Sometimes, of course, an abstraction is multiplexing a resource, and this necessarily has some cost. But it should be possible to deliver all or nearly all of it to a single client with only slight loss of performance.(这点是从上面"make it fast"引申出来的。既然我们要给客户提供简单快速接口, 但是我们就要把高效能接口暴露给客户)
4. Split resources in a fixed way if in doubt, rather than sharing them.
It is usually faster to allocate dedicated resources, it is often faster to access them, and the behavior of the allocator is more predictable. The obvious disadvantage is that more total resources are needed, ignoring multiplexing overheads, than if all come from a common pool. In many cases, however, the cost of the extra resources is small, or the overhead is larger than the fragmentation, or both.(如果不确定如何分配资源的话, 那么就使用固定分配资源的方式而不是共享。虽然固定分配资源需要占用额外的内容,但是资源分配的cost下来了,并且减少了碎片带来的overhead)
For example, it is always faster to access information in the registers of a processor than to get it from memory, even if the machine has a high-performance cache. Registers have gotten a bad name because it can be tricky to allocate them intelligently, and because saving and restoring them across procedure calls may negate their speed advantages. But when programs are written in the approved modern style with lots of small procedures, 16 registers are nearly always enough for all the local variables and temporaries, so that allocation is not a problem. With n sets of registers arranged in a stack, saving is needed only when there are n successive calls without a return [14, 39].(对于通常大量的小函数而言,固定分配出来的16个寄存器完全可以存储下局部和临时变量)
Input/output channels, floating-point coprocessors, and similar specialized computing devices are other applications of this principle. When extra hardware is expensive these services are provided by multiplexing a single processor, but when it is cheap, static allocation of computing power for various purposes is worthwhile.(IO通道,浮点协处理器以及其他特殊计算设备。没太理解这句话的含义??)
5. Safety first.
In allocating resources, strive to avoid disaster rather than to attain an optimum. Many years of experience with virtual memory, networks, disk allocation, database layout, and other resource allocation problems has made it clear that a general-purpose system cannot optimize the use of resources. On the other hand, it is easy enough to overload a system and drastically degrade the service. A system cannot be expected to function well if the demand for any resource exceeds two-thirds of the capacity, unless the load can be characterized extremely well. Fortunately hardware is cheap and getting cheaper; we can afford to provide excess capacity. Memory is especially cheap, which is especially fortunate since to some extent plenty of memory can allow other resources like processor cycles or communication bandwidth to be utilized more fully.(确保系统不会在某些load情况下面崩溃,这些都是最基本的保障。所有的优化都必须建立在这个基础之上。)
6. Shed load to control demand, rather than allowing the system to become overloaded.
这里不太理解 "to control demand"的含义。这条是在上面一条扩展出来的,就是不要让系统出于过载的情况下。 一旦出现负载过高的话,那么需要让负载释放出去。
This is a corollary of the previous rule. There are many ways to shed load. An interactive system can refuse new users, or even deny service to existing ones. A memory manager can limit the jobs being served so that all their working sets fit in the available memory. A network can discard packets. If it comes to the worst, the system can crash and start over more prudently.
Bob Morris suggested that a shared interactive system should have a large red button on each terminal. The user pushes the button if he is dissatisfied with the service, and the system must either improve the service or throw the user off; it makes an equitable choice over a sufficiently long period. The idea is to keep people from wasting their time in front of terminals that are not delivering a useful amount of service.
The original specification for the Arpanet [32] was that a packet accepted by the net is guaranteed to be delivered unless the recipient machine is down or a network node fails while it is holding the packet. This turned out to be a bad idea. This rule makes it very hard to avoid deadlock in the worst case, and attempts to obey it lead to many complications and inefficiencies even in the normal case. Furthermore, the client does not benefit, since it still has to deal with packets lost by host or network failure (see section 4 on end-to-end). Eventually the rule was abandoned. The Pup internet [3], faced with a much more variable set of transport facilities, has always ruthlessly discarded packets at the first sign of congestion.(拥塞丢包就是一种load shedding技术)
7. End-to-end.
Error recovery at the application level is absolutely necessary for a reliable system, and any other error detection or recovery is not logically necessary but is strictly for performance.(只有端到端的错误检查和回复才是需要的。其他层面的错误恢复检查理论上都可以不需要,但是为了性能原因可以保留。)
For example, consider the operation of transferring a file from a file system on a disk attached to machine A, to another file system on another disk attached to machine B. To be confident that the right bits are really on B’s disk, you must read the file from B’s disk, compute a checksum of reasonable length (say 64 bits), and find that it is equal to a checksum of the bits on A’s disk. Checking the transfer from A’s disk to A’s memory, from A over the network to B, or from B’s memory to B’s disk is not sufficient, since there might be trouble at some other point, the bits might be clobbered while sitting in memory, or whatever. These other checks are not necessary either, since if the end-to-end check fails the entire transfer can be repeated. Of course this is a lot of work, and if errors are frequent, intermediate checks can reduce the amount of work that must be repeated. But this is strictly a question of performance, irrelevant to the reliability of the file transfer. Indeed, in the ring based system at Cambridge it is customary to copy an entire disk pack of 58 MBytes with only an end-to-end check; errors are so infrequent that the 20 minutes of work very seldom needs to be repeated [36].(如果只是端到端地进行错误检查也可以work)
There are two problems with the end-to-end strategy. First, it requires a cheap test for success. Second, it can lead to working systems with severe performance defects that may not appear until the system becomes operational and is placed under heavy load.(端到端检查存在两个问题,一个是要求检查是否成功的成本很低, 另外一个是正常情况下面系统不会出现性能问题,但是当处于高负载和维护状态的时候可能会出现很严重的性能问题)