HBase: The Definitive Guide
Table of Contents
1. Preface
2. Chapter 1. Introduction
Dimensions
- Data model(数据模型). There are many variations of how the data is stored, which include key/value stores (compare to a HashMap), semi-structured, column-oriented stores, and document-oriented stores. How is your application accessing the data? Can the schema evolve over time?
- Storage model(存储模型). In-memory or persistent? This is fairly easy to decide on since we are comparing with RDBMSs, which usually persist their data to permanent storage, such as physical disks. But you may explicitly need a purely in-memory solution, and there are choices for that too. As far as persistent storage is concerned, does this affect your access pattern in any way?
- Consistency model(一致性模型). Strictly or eventually consistent? The question is, how does the storage system achieve its goals: does it have to weaken the consistency guarantees? While this seems like a cursory question, it can make all the difference in certain use-cases. It may especially affect latency, i.e., how fast the system can respond to read and write requests. This is often measured harvest and yield.
- Physical model(物理模型). Distributed or single machine? What does the architecture look like - is it built from distributed machines or does it only run on single machines with the distribution handled client-side, i.e., in your own code? Maybe the distribution is only an afterthought and could cause problems once you need to scale the system. And if it does offer scalability, does it imply specific steps to do so? Easiest would be to add one machine at a time, while sharded setups sometimes (especially those not supporting virtual shards) require for each shard to be increased simultaneously because each partition needs to be equally powerful.
- Read/write performance(读写性能). You have to understand what your application's access patterns look like. Are you designing something that is written to a few times, but read much more often? Or are you expecting an equal load between reads and writes? Or are you taking in a lot of writes and just a few reads? Does it support range scans or is better suited doing random reads? Some of the available systems are advantageous for only one of these operations, while others may do well in all of them.
- Secondary indexes(二级索引). Secondary indexes allow you to sort and access tables based on different fields and sorting orders. The options here range from systems that have absolutely no secondary indexes and no guaranteed sorting order (like a HashMap, i.e., you need to know the keys) to some that weakly support them, all the way to those that offer them out-of-the-box. Can your application cope, or emulate, if this feature is missing?
- Failure handling(失败处理). It is a fact that machines crash, and you need to have a mitigation plan in place that addresses machine failures (also refer to the discussion of the CAP theorem in Consistency Models). How does each data store handle server failures? Is it able to continue operating? This is related to the "Consistency model" dimension above, as losing a machine may cause holes in your data store, or even worse, make it completely unavailable. And if you are replacing the server, how easy will it be to get back to 100% operational? Another scenario is decommissioning a server in a clustered setup, which would most likely be handled the same way.
- Compression(压缩). When you have to store terabytes of data, especially of the kind that consists of prose or human readable text, it is advantageous to be able to compress the data to gain substantial savings in required raw storage. Some compression algorithms can achieve a 10:1 reduction in storage space needed. Is the compression method pluggable? What types are available?
- Load balancing(负载均衡). Given that you have a high read or write rate, you may want to invest into a storage system that transparently balances itself while the load shifts over time. It may not be the full answer to your problems, but may help you to ease into a high throughput application design.
- Atomic Read-Modify-Write(原子读修改写操作). While RDBMSs offer you a lot of these operations directly (because you are talking to a central, single server), it can be more difficult to achieve in distributed systems. They allow you to prevent race conditions in multi-threaded or shared-nothing application server design. Having these compare and swap (CAS) or check and set operations available can reduce client-side complexity. Locking, waits and deadlocks It is a known fact that complex transactional processing, like 2-phase commits, can increase the possibility of multiple clients waiting for a resource to become available. In a worst-case scenario, this can lead to deadlocks, which are hard to resolve. What kind of locking model does the system you are looking at support? Can it be free of waits and therefore deadlocks?
There is also the option to run client-supplied code in the address space of the server. The server-side framework to support this is called Coprocessors. The code has access to the server local data and can be used to implement light-weight batch jobs, or use expressions to analyze or summarize data based on a variety of operators. Coprocessors were added to HBase in version 0.91.0(coprocess是允许在server部分执行的代码,主要的功能是用来帮助hbase开发者能够做一些灵活的扩展而不需要重新编译代码)
Since flushing memstores to disk causes more and more HFile's to be created, HBase has a housekeeping mechanism that merges the files into larger ones using compactions. There are two types of compaction: minor compactions and major compactions.
- The former reduce the number of storage files by rewriting smaller files into fewer but larger ones, performing an n-way merge. Since all the data is already sorted in each HFile, that merge is fast and bound only by disk IO performance.
- The major compactions rewrite all files within a column family for a region into a single new one. They also have another distinct feature compared to the minor compactions: based on the fact that they scan all key/value pairs, they can drop deleted entries including their deletion marker. Predicate deletes are handled here as well - for example, removing values that have expired according to the configured time-to-live or when there are too many versions.(major compaction合并成为一个文件,清除标记删除的数据,多余的version以及超时的数据)
The master server is also responsible for handling load balancing of regions across region servers, to unload busy servers and move regions to less occupied ones. The master is not part of the actual data storage or retrieval path. It negotiates load balancing and maintains the state of the cluster, but never provides any data services to either the region servers or clients and is therefore lightly loaded in practice. In addition, it takes care of schema changes and other metadata operations, such as creation of tables and column families.(master觉得类似与coordinator,以及负责meta操作,工作相对比较轻量)
3. Chapter 2. Installation
3.1. Hardware
In practice a lot of HBase setups are colocated with Hadoop, to make use of locality using HDFS as well as MapReduce. This can significantly reduce the required network IO and boost processing speeds. Running Hadoop and HBase on the same server results in at least three Java processes running (data node, task tracker, and region server) and may spike to much higher numbers when executing MapReduce jobs. All of these processes need a minimum amount of memory, disk, and CPU resources to run sufficiently.(事实上将Hadoop和HBase混布非常常见的情形,好处就是可以提高locality,减少网络IO,加快处理速度)
3.1.1. CPU
It makes no sense to run three and more Java processes, plus the services provided by the operating system itself, on single core CPU machines. For production use it is typical that you use multi-core processors. Quad-core are state of the art and affordable, while hexa-core processors are also becoming more popular. Most server hardware supports more than one CPU, so that you can use two quad-core CPUs for a total of 8 cores. This allows for each basic Java process to run on its own core while the background tasks like Java garbage collection can be executed in parallel. In addition there is hyperthreading, which adds to their overall performance. (单个core上不要分配超过3个Java进程)
As far as CPU is concerned you should spec the master and slave machines the same.
| Node Type | Recommendation |
|---|---|
| Master | dual quad-core CPUs, 2.0-2.5 GHz |
| Slave | dual quad-core CPUs, 2.0-2.5 GHz |
@dp quad-core hyperthreading http://detail.zol.com.cn/servercpu/index234825.shtml
3.1.2. Memory
The question really is: is there too much memory? In theory no, but in practice it has been empirically determined that when using Java you should not set the amount of memory given to a single process too high. Memory (called heap in Java terms) can start to get fragmented and in a worst case scenario the entire heap would need a rewriting - this is similar to the well known disk fragmentation but cannot run in the background. The Java Runtime pauses all processing to clean up the mess which can lead to quite a few problems (more on this later). The larger you have set the heap the longer this process will take. Processes that do not need a lot of memory should only be given their required amount to avoid this scenario but with the region servers and their block cache there is in theory no upper limit. You need to find a sweet spot depending on your access pattern. (内存大小分配是一门艺术)
At the time of this writing, setting the heap of the region servers to larger than 16GB is considered dangerous. Once a stop-the-world garbage collection is required, it simply takes too long to rewrite the fragmented heap. Your server could be considered dead by the master and be removed from the working set. This may change sometime as this is ultimately bound to the Java Runtime Environment used, and there is development going on to implement JREs that do not stop the running Java processes when performing garbage collections.(内存分配不要超过16GB,不然使用stop-the-world GC进行回收的话耗时非常严重,当然如果使用其他的GC算法的话应该就没有这个限制)
Exemplary memory allocation per Java process for a cluster with 800TB of raw disk storage space
| Process | Heap | Description | @dp |
|---|---|---|---|
| NameNode | 8GB | About 1GB of heap for every 100TB of raw data stored, or per every million files/inodes | |
| SecondaryNameNode | 8GB | Applies the edits in memory and therefore needs about the same amount as the NameNode. | |
| JobTracker | 2GB | Moderate requirements | |
| HBase Master | 4GB | Usually lightly loaded, moderate requirements only | |
| DataNode | 1GB | Moderate requirements | |
| TaskTracker | 1GB | Moderate requirements | |
| HBase RegionServer | 12GB | Majority of available memory, while leaving enough room for the operating system (for the buffer cache), and for the Task Attempt processes | |
| Task Attempts | 1GB | Multiply with the maximum number you allow for each | |
| ZooKeeper | 1GB | Moderate requirements |
It is recommended to optimize your RAM for the memory channel width of your server. For example, when using dual-channel memory each machine should be configured with pairs of DIMMs. With triple-channel memory each server should have triplets of DIMMs. This could mean that a server has 18GB (9x2GB) of RAM instead of 16GB (4x4GB). Also make sure that not just the server's motherboard supports this feature, but also your CPU: some CPUs only support dual-channel memory and therefore, even if you put in triple-channel DIIMMs, they will only be used in dual-channel mode.(内存使用双通道还是三通道,另外CPU是否支持三通道)
3.1.3. Disks
The data is stored on the slave machines and therefore it is those servers that need plenty of capacity. Depending if you are more read/write or processing oriented you need to balance the number of disks with the number of CPU cores available. Typically you should have at least one core per disk, so in an 8 core server adding 6 disks is good, but adding more might not be giving you the optimal performance.(磁盘数量最好不要超过CPU core数目)
For the slaves you should not use RAID but rather what is called JBOD. For the master nodes on the other hand it does make sense to use a RAID disk setup to protect the crucial file system data. A common configuration is RAID 1+0, or RAID 0+1. For both servers though, make sure to use disks with RAID firmware. The difference between these and consumer grade disks is the RAID firmware will fail fast if there is a hardware error, thus not freezing the DataNode in disk wait for a long time.(slave节点使用JBOD,master节点使用RAID,并且使用RAID firmware来尽快检测硬件损坏)
Some consideration should go into the type of drives, for example 2.5" or 3.5" drives or SATA vs. SAS. In general SATA drives are recommended over SAS since they are more cost effective, and since the nodes are all redundantly storing replicas of the data across multiple servers you can safely use the more affordable disks. 3.5" disks on the other hand are more reliable compared to 2.5" disks but depending on the server chassis you may need to go with the later.
The disk capacity is usually 1TB per disk but you can also use 2TB drives if necessary. Using high density servers with 1 to 2TB drives and 6 to 12 of them is good as you get a lot of storage capacity and the JBOD setup with enough cores can saturate the disk bandwidth nicely.
3.1.4. Chassis
The actual server chassis is not that crucial, most servers in a specific price bracket provide very similar features. It is often better to shy away from special hardware that offers proprietary functionality but opt for the generic servers so that they can be easily combined over time as you extend the capacity of the cluster
As far as networking is concerned, it is recommended to use a two port Gigabit Ethernet card - or two channel-bonded cards. If you have already support for 10 Gigabit Ethernet or Infiniband then you should use it.(双口千兆网卡???)
For the slave servers a single power supply (PSU) is sufficient, but for the master node you should use redundant PSUs, such as the optional dual-PSUs available for many servers.(slave节点使用一个PSU,而master节点使用冗余PSU)
In terms of density it is advisable to select server hardware that fits into a low number of rack units (abbreviated as "U"). Typically 1U or 2U servers are used in 19" racks or cabinets. A consideration while choosing the size is how many disks they can hold and their power consumption. Usually a 1U server is limited to a lower number of disks or force you to use 2.5" disks to get the capacity you want.(机器大小限制了单个机架上面允许放置的机器数量,磁盘数量以及功耗相关)
3.2. Networking
In a data center servers are typically mounted into 19" racks or cabinets with 40U or more in height. You could fit up to 40 machines (although with half-depth servers some companies have up to 80 machines in a single rack, 40 machines on either side) and link them together with a top-of-rack (or ToR in short) switch. Given the Gigabit speed per server you need to ensure that the ToR switch is fast enough to handle the throughput these servers can create. Often the backplane of a switch cannot handle all ports at line rate or is oversubscribed - in other words promising you something in theory it cannot do in reality.
Switches often have 24 or 48 ports and with the above channel-bonding or two port cards you need to size the networking large enough to provide enough bandwidth. Installing 40 1U servers would need 80 network ports then, so in practice you may need a staggered setup where you use multiple rack switches and then aggregate to a much larger core aggregation switch (abbreviated as CaS). This results in a two tier architecture, where the distribution is handled by the ToR switch and the aggregation by the CaS
While we cannot address all the considerations for large scale setups we can still notice that this is a common design pattern. Given the operations team is part of the planning, and it is known how much data is going to be stored and how many clients are expected to read and write concurrently, this involves basic math to compute the amount of servers needed - which also drives the networking considerations.
When users have reported issues with HBase on the public mailing list or on other channels, especially slower than expected IO performance bulk inserting huge amounts of data it became clear that networking was either the main or a contribution issue. This ranges from misconfigured or faulty network interface cards (NICs) to completely oversubscribed switches in the IO path. Please make sure to verify every component in the cluster to avoid sudden operational problems - the kind that could have been avoided by sizing the hardware appropriately.
Finally, given the current status of built-in security into Hadoop and HBase, it is common for the entire cluster to be located in its own network, possibly protected by a firewall to control access to the few required, client-facing ports.
3.3. Software
3.3.1. Operating System
- CentOS
- CentOS is a community-supported, free software operating system, based on Red Hat Enterprise Linux (shortened as RHEL). It mirrors RHEL in terms of functionality, features, and package release levels as it is using the source code packages Red Hat provides for its own enterprise product to create CentOS branded counterparts. Like RHEL it provides the packages in RPM format.(基于RHEL的社区版本)
- It is also focused on enterprise usage and therefore does not adopt new features or newer versions of existing packages too quickly. The goal is to provide an OS that can be rolled out across a large scale infrastructure while not having to deal with short term gains of small incremental package updates.(主要针对企业应用,很多新feature不会及时采用)
- Fedora
- Fedora is also a community-supported, free and open source operating system, and is sponsored by Red Hat. But compared to RHEL and CentOS it is more a playground for new technologies and strives to advance new ideas and features. Because of that it has a much shorter life cycle compared to enterprise oriented products. An average maintenance period for Fedora release is around 13 months.(RedHat的社区版本,相对RHEL/CentOS会尝试添加更多的新特性)
- Aimed at workstations and with exposure to many new features made Fedora a quite popular choice, only beaten by more desktop oriented operating systems. For production use you may want to take into account the reduced life-cycle that counteract the freshness of this distribution. You may want to consider not using the latest Fedora release but trail by one version to be able to rely on some feedback from the community as far as stability and other issues are concerned.(主要针对工作站但是逐渐被基于桌面的系统取代,产品应用的话尽量不要使用最新的版本)
- Debian
- Debian is another Linux kernel based OS that has software packages released as free and open source software. It can be used for desktop and server systems and has a conservative approach when it comes to package updates. Releases are only published after all included packages have been sufficiently tested and deemed stable.(开源软件,针对desktop以及server,包含的功能相对保守)
- As opposed to other distributions Debian is not backed by a commercial entity but solely governed by its own project rules. It also uses its own packaging system that supports DEB packages only. Debian is known to run on many hardware platforms as well as to have a very large repository of packages.(没有商业个体支持)
- Ubuntu
- Ubuntu is a Linux distribution based on Debian. It is distributed as free and open source software, and backed by Canonical Ltd., which is not charging for the OS but is selling technical support for Ubuntu.(Canonical支持)
- The life cycle is split into a longer and a shorter term release. The long-term support (or LTS) releases are supported for three years on the desktop and five years on the server. The packages are also DEB format and are based on the unstable branch of Debian: Ubuntu in a sense is for Debian what Fedora is for Red Hat Linux. Using Ubuntu as a server operating system is further made more difficult as the update cycle for critical components is very frequent.(Ubuntu从不稳定的Debian分支拉出来开发的,关系对Debian来说就和Fedora对RedHat)
- Solaris
- Solaris is offered by Oracle, and is available for a limited number of architecture platforms. It is a descendant of Unix System V Release 4 and therefore the most different OS in this list. Some of the source code is available as open source while the rest is closed source. Solaris is a commercial product and needs to be purchased. The commercial support for each release is maintained for 10 to 12 years.(从SVR4继承下来,部分代码是公开的,需要购买获得。商业支持在10-12年)
- Red Hat Enterprise Linux
- Abbreviated as RHEL, Red Hat's Linux distribution is aimed at commercial and enterprise level customers. The OS is available as a server and a desktop version. The license comes with offerings for official support, training, and a certification programme.(针对企业用户,针对桌面和服务器版本,license包含了官方支持,培训以及认证)
- The package format for RHEL is called RPM (the Red Hat Package Manager), comprised of the software packaged in the .rpm file format, and the package manager itself.
- Being commercially supported and maintained RHEL has a very long life cycle of seven to ten years.(商业支持7-10年)
3.3.2. File System
- ext3
- It has been proven stable and reliable, meaning it is a safe bet setting up your cluster with it. Being part of Linux since 2001 it has been steadily improved over time and has been the default file system for years.(相对来说比较稳定)
- There are a few optimizations you should keep in mind when using ext3.
- First you should set the noatime option when mounting the file system to reduce the administrative overhead for the kernel to keep the access time for each file.(关闭access time,/etc/fstab with "/dev/sdd1 /data ext3 defaults,noatime 0 0")
- By default it reserves a specific number of bytes in blocks for situations where a disk fills up but crucial system processes need this space to continue to function. This is really useful for critical disks, for example the one hosting the operating system, but it is less useful for the storage drives, and in a large enough cluster can have a significant impact on available storage capacities.(减少磁盘的预留空间,主要还是需要针对数据磁盘,不要针对系统磁盘)
- tune2fs -m 1 <device-name> (1% reserved)
- Yahoo has publicly stated that it is using ext3 as their file system of choice on their large Hadoop cluster farm. This shows that although it is by far not the most current or modern file system that it does very well in large clusters. In fact, you are more likely to saturate your IO on other levels of the stack before reaching the limits of ext3.(Yahoo对ext3的使用证明还是比较稳定的,并且在ext3达到极限之前可能网络IO已经到达bottleneck)
- The biggest drawback of ext3 is that during the bootstrap process of the servers it requires the largest amount of time. Formatting a disk with ext3 can take minutes to complete and may become a nuisance when spinning up machines dynamically on a regular basis - although that is not very common practice. (ext3最大的缺点就在于启动server的时候消耗大量时间,并且做磁盘格式化的时候费时)
- ext4
- It is officially part of the Linux kernel since then end of 2008. To that extent it has only a few years to prove its stability and reliability. Nevertheless Google has announced to upgrade its storage infrastructure from ext2 to ext4. This can be considered a strong endorsement, but also shows the advantage of the extended filesystem (the ext in ext3, ext4, etc.) lineage to be upgradable in place. Choosing an entirely different file system like XFS would have made this impossible.(从2008年开始进入Linux kernel所以还需要一段时间的考验,但是google使用证明了其稳定性。在ext文件系统上面的升级是平滑的,而不像XFS一样不兼容的)
- Performance wise ext4 does beat ext3 and allegedly comes close to the high performance XFS. It also has many advanced features, that allows to store files up to 16TB in size and supports volumes up to one exabyte (that is 1018 bytes).(性能好过ext3并且接近XFS, 并且支持更大的文件)
- A more critical feature is the so called delayed allocation and it is recommended to turn it off for Hadoop and HBase use. Delayed allocation keeps the data in memory and reserves the required number of blocks until the data is finally flushed to disk. It helps keeping blocks for files together and can at times write the entire file into a contiguous set of blocks. This reduces fragmentation and improves performance reading the file subsequently. On the other hand it increases the possibility of data loss in case of a server crash.(delay allocation能够将data缓存起来进行聚合,在应用层面上做一些merge直到flush下去,这样的好处是减少文件磁盘碎片的产生,但是也有丢失数据的风险)
- XFS
- XFS (see http://en.wikipedia.org/wiki/Xfs for details) is available in Linux for about the same time as ext3. It was originally developed by Silicon Graphics in 1993. Most Linux distributions today have XFS support included. (和ext3一起出现,SGI开发的)
- It has similar features compared to ext4, for example both have extents (grouping contiguous blocks together, reducing the number of blocks required to maintain per file) and the mentioned delayed allocation.(和ext4都非常多相似的特性)
- A great advantage of XFS during bootstrapping a server is the fact that it formats the entire drive in virtually no time. This can effectively reduce the time required to provision new servers with many storage disks significantly.(启动以及格式化非常快几乎不耗费时间)
- On the other hand there are also some drawbacks using XFS. There is a known shortcoming in the design that impacts metadata operations, such as deleting a large number of files. The developers have picked up the issue and applied various fixes to improve the situation. You will have to check how you use HBase to make a knowledge decision if this might affect you. For normal use you should not have a problem with this limitation of XFS as HBase operates on fewer but larger files.(但是存在设计上的缺陷,比如大量的metadata操作性能不好,不过对Hadoop来说这个问题似乎不是很严重,并且也有补丁解决)
- ZFS
- Introduced in 2005 ZFS (see http://en.wikipedia.org/wiki/ZFS for details) was developed by Sun Microsystems. The name is an abbreviation for zettabyte file system, as it has the ability to store 258 zettabytes (which in turn are 1021 bytes).
- ZFS is primarily supported on Solaris and has advanced features that may be useful in combination with HBase. It has built-in compression support that could be used as a replacement for the pluggable compression codecs in HBase.
4. Chapter 3. Client API: The Basics
General Notes
- All operations that mutate data are guaranteed to be atomic on a per row basis.
- Finally, creating HTable instances is not without cost. Each instantiation involves scanning the .META. table to check if the table actually exists and if it is enabled as well as a few other operations that makes this call quite costly. Therefore it is recommended to create HTable instances only once - and one per thread - and reuse that instance for the rest of the lifetime of your client application.(创建HTable的overhead还是比较大的)
5. Chapter 7. MapReduce Integration
MapReduce Locality
- And here is the kicker: HDFS is smart enough to put the data where it is needed! It has a block placement policy in place that enforces all blocks to be written first on a colocated server. The receiving data node compares the server name of the writer with its own, and if they match the block is written to the local file system. Then a replica is sent to a server within the same rack, and another to a remote rack - assuming you are using rack awareness in HDFS. If not then the additional copies get placed on the least loaded data node in the cluster.(HDFS文件在写的时候已经可以感知尽量将数据写在和client比较近的位置上面)
- This means for HBase that if the region server stays up for long enough (which is what you want) that after a major compaction on all tables - which can be invoked manually or is triggered by a configuration setting - it has the files local on the same host. The data node that shares the same physical host has a copy of all data the region server requires. If you are running a scan or get or any other use-case you can be sure to get the best performance.(如果做compaction之后,所有的文件都尽量地写在服务的region serve上面并且通常不会出现变化,所以可以这样说基本上region server服务的数据在本地磁盘上都存在。所以这样达到的性能是比较好的)
- The number of splits therefore is equal to all regions between the start and stop key. If you do not set one, then all are included. (split number和region number是一致的)
- The split also contains the server name hosting the region. This is what drives the locality for MapReduce jobs over HBase: the framework compares the server name and if there is a task tracker running on the same machine, it will preferably run it on that server. Since the region server is also colocated with the data node on that same node, the scan of the region will be able to retrieve all data from local disk.(split信息包含了region的hostname,那么在选择tt的时候优先选择和hostname比较近的机器。而因为region本身就带有一定的data locality,所以通常scan的时候也是从本地磁盘进行读取的)
- When running MapReduce over HBase, it is strongly advised to turn off the speculative execution mode. It will only create more load on the same region and server, and also works against locality. This results in all data being send over the network, adding to the overall IO load.(关于预测执行模式,因为data locality比较差)
6. Chapter 8. Architecture
6.1. Storage
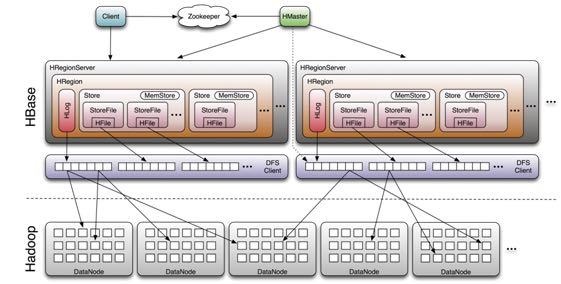
The HRegionServer opens the region and creates a corresponding HRegion object. When the HRegion is opened it sets up a Store instance for each HColumnFamily for every table as defined by the user beforehand. Each of the Store instances can in turn have one or more StoreFile instances, which are lightweight wrappers around the actual storage file called HFile. A Store also has a MemStore , and the HRegionServer a shared HLog instance
- RegionServer(HRegionServer) 上面存在有多个 Region(HRegion),一个Region对应一个Table里面多个连续的Row
- 每个Region为不同的ColumnFamily(HColumnFamily)分配一个Stoe,但是共享一个Log(HLog)作为WAL
- Put.setWriteToWAL(boolean) 控制是否写入WAL
- The WAL is a standard Hadoop SequenceFile and it stores HLogKey instances.
- These keys contain a sequential number as well as the actual data and are used to replay not yet persisted data after a server crash.
- 每个Store有一个MemStore以及多个StoreFile(HFile的包装,存放在HDFS上)
6.2. Files
➜ ~ hadoop fs -lsr /home/dirlt/hbase 13/05/30 12:32:37 INFO security.UserGroupInformation: JAAS Configuration already set up for Hadoop, not re-installing. drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/-ROOT- drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:47 /home/dirlt/hbase/-ROOT-/70236052 drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/-ROOT-/70236052/.oldlogs -rw-r--r-- 1 dirlt supergroup 607 2013-05-08 14:49 /home/dirlt/hbase/-ROOT-/70236052/.oldlogs/hlog.1367995791534 -rw-r--r-- 1 dirlt supergroup 634 2013-05-08 14:49 /home/dirlt/hbase/-ROOT-/70236052/.regioninfo drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:47 /home/dirlt/hbase/-ROOT-/70236052/.tmp drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:47 /home/dirlt/hbase/-ROOT-/70236052/info -rw-r--r-- 1 dirlt supergroup 502 2013-05-30 11:47 /home/dirlt/hbase/-ROOT-/70236052/info/1721598584244731834 -rw-r--r-- 1 dirlt supergroup 706 2013-05-08 14:49 /home/dirlt/hbase/-ROOT-/70236052/info/3005841342258328397 drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:47 /home/dirlt/hbase/-ROOT-/70236052/recovered.edits drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/.META. drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/.META./1028785192 drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/.META./1028785192/.oldlogs -rw-r--r-- 1 dirlt supergroup 124 2013-05-08 14:49 /home/dirlt/hbase/.META./1028785192/.oldlogs/hlog.1367995791729 -rw-r--r-- 1 dirlt supergroup 618 2013-05-08 14:49 /home/dirlt/hbase/.META./1028785192/.regioninfo drwxr-xr-x - dirlt supergroup 0 2013-05-08 14:49 /home/dirlt/hbase/.META./1028785192/info drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:46 /home/dirlt/hbase/.corrupt drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:46 /home/dirlt/hbase/.logs drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:46 /home/dirlt/hbase/.logs/localhost,53731,1369885582228 -rw-r--r-- 1 dirlt supergroup 0 2013-05-30 11:46 /home/dirlt/hbase/.logs/localhost,53731,1369885582228/localhost%3A53731.1369885616058 drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:47 /home/dirlt/hbase/.oldlogs -rw-r--r-- 1 dirlt supergroup 3 2013-05-08 14:49 /home/dirlt/hbase/hbase.version drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:57 /home/dirlt/hbase/test drwxr-xr-x - dirlt supergroup 0 2013-05-30 12:32 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab drwxr-xr-x - dirlt supergroup 0 2013-05-30 11:57 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/.oldlogs -rw-r--r-- 1 dirlt supergroup 124 2013-05-30 11:57 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/.oldlogs/hlog.1369886221849 -rw-r--r-- 1 dirlt supergroup 700 2013-05-30 11:57 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/.regioninfo drwxr-xr-x - dirlt supergroup 0 2013-05-30 12:32 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/.tmp drwxr-xr-x - dirlt supergroup 0 2013-05-30 12:32 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/cf -rw-r--r-- 1 dirlt supergroup 381 2013-05-30 12:32 /home/dirlt/hbase/test/1938ab7ad31208641c117035f7c012ab/cf/2684233566687696328
- Root Level Files
- .logs. WAL
- An interesting observation is that the log file is reported to have a size of 0. This is fairly typical when this file was created recently, as HDFS is using the built-in append support to write to this file, and only complete blocks are made available to readers. After waiting for an hour the log file is rolled, as configured by the hbase.regionserver.logroll.period configuration property (set to 60 minutes by default), you will see the existing log file reported with its proper size, since it is closed now and HDFS can state the "correct" number. The new log file next to it again starts at zero size.
- hbase.id / hbase.version. the unique ID of the cluster, and the file format version.
- splitlog. intermediate split files when log splitting.
- .corrupt. corrupted logs.
- .logs. WAL
- Table Level Files
- regionName = <tableName>,<startRow>,<endRow> eg. test,,1369886221574
- encodedName = md5sum(regionName)
- regionNameOnWebUI = <regionName>.encodedName eg. test,,1369886221574.1938ab7ad31208641c117035f7c012ab.
- path = /<tableName>/encodedName/<columnFamily>/fileName(random number)
- .tmp hold temporary files, for example the rewritten files from a compaction.
- .regioninfo the serialized information of the HRegionInfo instance for the given region.
- recovered.edits 在/splitlog完成了log splitting之后移动到这个目录下面进行恢复
- splits Once the region needs to split because of its size, a matching splits directory is created, which is used to stage the two daughter regions. 用来进行region splitting
6.3. HFile
The actual storage files are implemented by the HFile class, which was specifically created to serve one purpose: store HBase's data efficiently. They are based on Hadoop's TFile class, and mimic the SSTable format used in Google's BigTable architecture.(可以参考 leveldb 代码)
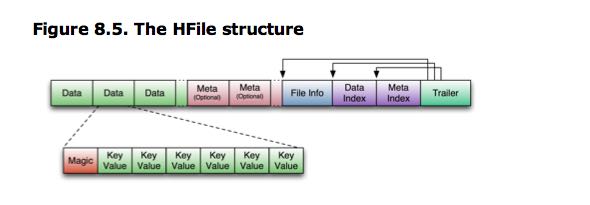
可以通过命令 "./bin/hbase org.apache.hadoop.hbase.io.hfile.HFile" 来查看hfile文件
下面是KeyValue结构
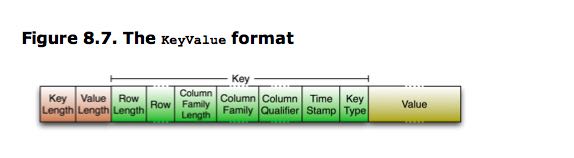
- The reason why in the example above the average key is larger than the value can be attributed to the contained fields in the key: it includes the fully specified dimensions of the cell. The key holds the row key, the column family name, the column qualifier, and so on.(注意包含了rowkey,column family,column qualifier,所以使得key存储空间还是比较大的)
- On the other hand, compression should help mitigate this problem as it looks at finite windows of data, and all contained repetitive data is compressed efficiently. (但是压缩存储能够在很大程度上缓解这个问题)
6.4. Compactions
6.4.1. Minor
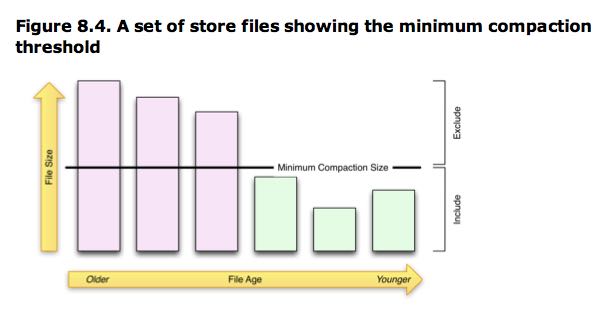
- The minor compactions are responsible for rewriting the last few files into one larger one.
- The number of files is set with the hbase.hstore.compaction.min property (which was previously called hbase.hstore.compactionThreshold, and although deprecated it is still supported). It is set to 3 by default, and needs to be at least 2 or more. A number too large would delay minor compactions, but also require more resources and take longer once they start. (至少多少个文件才能够触发,高数值会延迟compaction, 但是每次compaction会耗费更长时间)
- The maximum number of files to include in a minor compaction is set to 10, and configured with hbase.hstore.compaction.max. (但是每次最多多少个文件参与compaction)
- The list is further narrowed down by the hbase.hstore.compaction.min.size (set to the configured memstore flush size for the region), and the hbase.hstore.compaction.max.size (defaults to Long.MAX_VALUE) configuration properties.
- Any file larger than the maximum compaction size is always excluded. (参与compaction文件不能超过多大)
- The minimum compaction size works slightly different: it is a threshold rather than a per file limit. It includes all files that are under that limit, up to the total number of files per compaction allowed.(参与compaction文件必须小于某个阈值,直到参与compaction文件数量满足之前的需求)
- The algorithm uses hbase.hstore.compaction.ratio (defaults to 1.2, or 120%) to ensure that it does include enough files into the selection process. The ratio will also select files that are up to that size compared to the sum of the store file sizes of all newer files. The evaluation always checks the files from the oldest to the newest. This ensures that older files are compacted first. The combination of these properties allows to fine-tune how many files are included into a minor compaction.(这个参数主要是用来控制已经超过max compaction file size的文件,因为按照上面的逻辑一旦超过这个file size之后那么将没有可能进行compaction了。从oldest选择,知道file size超过所有的newer file size总和。我猜想这些同时这些文件数目必须超过compaction.min但是不能够大于compaction.max会比较有意义)
6.4.2. Major
- It triggers a check on a regular basis, controlled by hbase.server.thread.wakefrequency (multiplied by hbase.server.thread.wakefrequency.multiplier, set to 1000, to run it less often than the other thread based tasks). (定期去检查是否需要做major compaction)
- If you call the major_compact command, or the majorCompact() API call, then you force the major compaction to run.(手动调用的话那么就强制进行major compaction)
- Otherwise the server checks first if the major compaction is due, based on hbase.hregion.majorcompaction (set to 24 hours) from the last it ran. The hbase.hregion.majorcompaction.jitter (set to 0.2, in other words 20%) causes this time to be spread out for the stores. Without the jitter all stores would run a major compaction at the same time, every 24 hours.(否则根据两个参数来控制,第一个是检查一下这次major compaction是否到期,另外一个是控制不要让所有的major compaction同时启动)
- If no major compaction is due, then a minor is assumed. Based on the above configuration properties, the server determines if enough files for a minor compaction are available and continues if that is the case.(如果检查没有不需要做major compaction的话,那么就会检查是否需要做minor compaction)
6.5. WAL
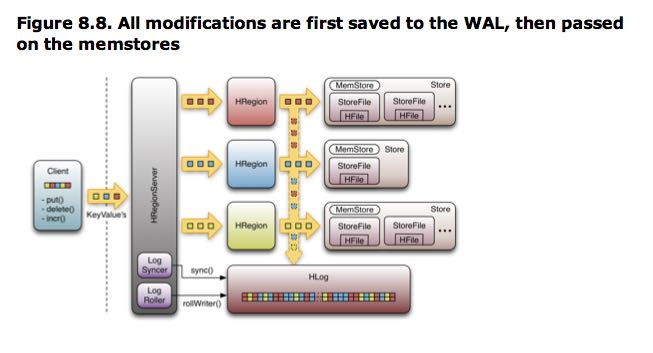
6.5.1. Format
The figure shows three different regions, hosted on the same region server, and each of them covering a different row key range. Each of these regions shares the same single instance of HLog. This means that the data is written to the WAL in the order of arrival. This imposes some extra work needed when a log needs to be replayed (see the section called “Replay”). But since this happens rather seldom it is optimized to store data sequentially, giving it the best IO performance.

Currently the WAL is using a Hadoop SequenceFile, which stores records as sets of key/values. (使用SequenceFile来保存WAL)
- HLogKey
- RegionName and TableName
- Sequence Number
- Cluster ID for replication across multiple clusters.
- WALEdit
- 将client对于某个row上面所有修改的KeyValue包装起来
- 这样进行replay就能够以原子的方式进行。
6.5.2. LogRoller
- The LogRoller class runs as a background thread and takes care of rolling log files at certain intervals. This is controlled by the hbase.regionserver.logroll.period property, set by default to one hour.(单独的线程运行,每隔一段时间进行日志的回滚)
- Every 60 minutes the log is closed and a new one started. Over time the system accumulates an increasing number of log files that need to be maintained as well. The HLog.rollWriter() method, which is called by the LogRoller to do the above rolling of the current log file, is taking care of that as well by calling HLog.cleanOldLogs() subsequently.(关闭原来的log文件重新打开新的log文件进行记录,同时会做一些清除日志的操作,应该是move到oldlogs目录下面)
- It checks what the highest sequence number written to a storage file is, because up to that number all edits are persisted. It then checks if there is a log left that has edits which are all less than that number. If that is the case it moves said logs into the .oldlogs directory, and leaves just those that are still needed.(清理的过程也非常直接,首先检查在存储文件里面最高的sequence number, 然后判断日志如果里面所有的sequence number都是小于这个sequence number的话,那么可以确定这个文件是不需要的了)
- The other parameters controlling the log rolling are hbase.regionserver.hlog.blocksize (set to the file system default block size, or fs.local.block.size, defaulting to 32MB) and hbase.regionserver.logroll.multiplier (set to 0.95), which will rotate logs when they are at 95% of the block size. So logs are switched out when either the they are considered full, or a certain amount of time has passed - whatever comes first. (另外一个触发roll log的事件是,当log超过一定大小)
6.5.3. LogSyncer
#note: sync不是针对本地磁盘,而是将所写数据的offset写到namenode上面
- The table descriptor allows to set the so called deferred log flush flag, as explained in the section called “Table Properties”. The default is false and means that every time an edit is sent to the servers it will call the log writer's sync() method. It is the call that forces the update to the log to be acknowledged by the file system so that you have the durability needed.(这个功能可以防止HBase每次写HDFS都调用sync而采用延迟sync的方式。这个选项在Table Descriptor里面进行设置。默认的话是关闭的也就是说每次都会调用sync)
- Setting the deferred log flush flag to true causes for the edits to be buffered on the region server, and the LogSyncer class, running as a thread on the server, is responsible to call the sync() method at a very short interval. The default is one second and is configured by the hbase.regionserver.optionallogflushinterval property.(如果采用延迟sync的话那么存在一个单独的线程来专门进行刷新,刷新的间隔时间可以配置)
- Note that this only applies to user tables: all catalog tables are always sync'ed right away.(对ROOT/META这种catalog的表格必须每次都进行sync,延迟sync仅仅对于usertable有效)
6.5.4. Replay
- Only if you use the graceful stop (see the section called “Node Decommission”) process you will give a server the chance to flush all pending edits before stopping. The normal stop scripts simply fail the servers, and a log replay is required during a cluster restart. Otherwise shutting down a cluster could potentially take a very long time, and cause a considerable spike in IO, caused by the parallel memstore flushes. (graceful stop会将memstore完全flush到disk上,这样重启的话就不需要进行replay)
- You can turn the new distributed log splitting off by means of the hbase.master.distributed.log.splitting configuration property. Setting it to false disabled the distributed splitting, and falls back to do the work directly on the master only.(设置是否需要进行distributed log splitting)
- In non-distributed mode the writers are multi-threaded, controlled by the hbase.regionserver.hlog.splitlog.writer.threads property, which is set to 3 by default. Increasing this number needs to be carefully balanced as you are likely bound by the performance of the single log reader.(如果是在一个master上完成的话允许使用多线程完成,线程数目可以进行配置)
- The path contains the log file name itself to distinguish itself from other, possibly concurrently executed, log split output. It also has the table name, region name (the hash), and the recovered.edits directory. Lastly the name of the split file is the sequence ID of the first edit for the particular region.(进行log splitting输出的recover edits文件包含下面几个部分)
- eg. "testtable/d9ffc3a5cd016ae58e23d7a6cb937949/recovered.edits/0000000000000002352"
- tableName
- regionName
- sequenceID of first edit
- The .corrupt directory contains any log file that could not be parsed. This is influenced by the hbase.hlog.split.skip.errors property, which is set to true. It means that any edit that could not be read from a file causes for the entire log to be moved to the .corrupt folder. If you set the flag to false then an IOExecption is thrown and the entire log splitting process is stopped.(进行log splitting的时候如果出现错误的情况不能够读取的话,可以选择如何处理)
- The files in the recovered.edits folder are removed once they have been read and their edits persisted to disk. In case a file cannot be read, the hbase.skip.errors property defines what happens next: the default value is false and causes the entire region recovery to fail. If set to true the file is renamed to the original filename plus ".<currentTimeMillis>". Either way, you need to carefully check your log files to determine why the recovery has had issues and fix the problem to continue.(读取recovery edit失败的话有两种,一种直接回复失败,另外一种是rename成为另外一个文件可以方便以后追查)