Finding a needle in Haystack: Facebook’s photo storage
Table of Contents
https://www.usenix.org/legacy/event/osdi10/tech/full_papers/Beaver.pdf @ 2010
解决存储大量静态小文件问题
1. Abstract
- Facebook currently stores over 260 billion images, which translates to over 20 petabytes of data. Users up-load one billion new photos (∼60 terabytes) each week and Facebook serves over one million images per sec-ond at peak. # 260G张图片, 20PB数据(~= 20 * 1024 * 1024 * 1.024 ^ 3 / 260 = 84k bytes). 每周上传1G张图片~60TB(~= 60 * 1024 * 1.024 ^ 3 / 1 = 64k bytes). 高峰1000k QPS.
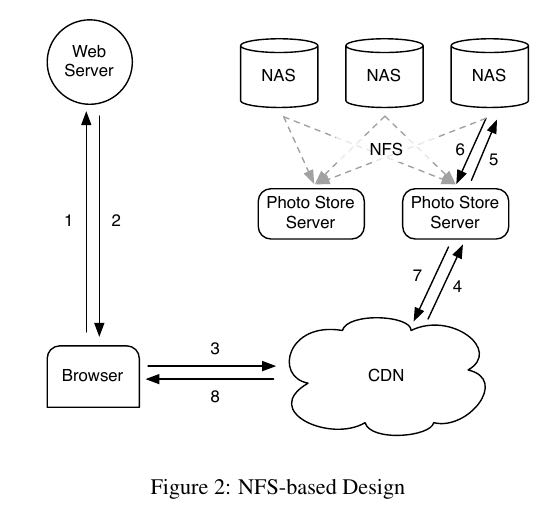
- Haystack provides a less expensive and higher performing solution than our previous approach, which leveraged network attached storage appliances over NFS. # 取代之前NFS方案.
- Our key observation is that this traditional design incurs an excessive number of disk operations because of metadata lookups. # NFS(or POSIX based fs)最大性能问题在于因为读取元数据使得磁盘访问次数太多.
- We carefully reduce this per photo metadata so that Haystack storage machines can perform all metadata lookups in main memory. # haystack减少metadata大小, 然后全部放入memory. 减少磁盘访问次数.
2. Introduction
3. Background & Previous Design
下面是图片服务的典型设计图. 这个设计存在个问题就是, 图片访问呈现长尾趋势, 有大量的不那么popular的图片访问量加起来造成的traffic巨大. CDN容量有限只能缓存那些非常popular的那些, 对那些长尾却没有办法缓存. 所以这些图片的访问全部落在了photo-storage部分.
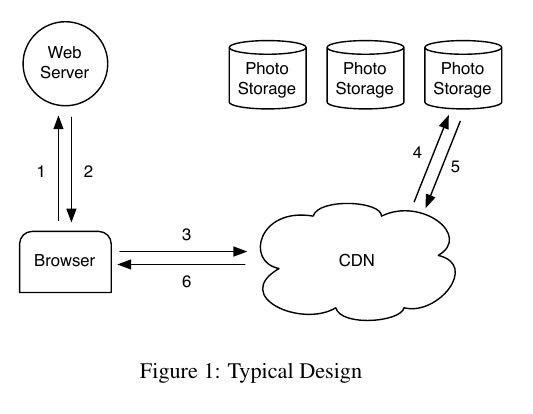
我么最初选用的是NFS来做photo-storage. 但是NFS读取metata会产生许多disk IO. 当时为了节省这个disk IO, 实现了filename -> filehandle的cache. 但是这个改进收效甚微, 因为那些less popular图片访问次数可能非常少. 最后我们发现, 其实完全依赖于cache并不是一个正确的方向. 因为那些less popular图片完全没有办法缓存, 所以我们真正该改进的是减少磁盘访问这些less popular图片的代价.
4. Design & Implementation
4.1. Overview
Recall that storing a single photo per file resulted in more filesystem metadata than could be reasonably cached. Haystack takes a straight-forward approach: it stores multiple photos in a single file and therefore maintains very large files. # 将许多图片存储在一个文件里面来减少metadata.
The Haystack architecture consists of 3 core compo-nents:
- the Haystack Store,
- physical volumes. # on a single node. 100 pv on 1TB, 100GB/pv.
- logical volumes. # redundancy. several physical volumes => a single logical volumes.
- Haystack Directory,
- application metadata
- mapping(filename -> logical volume)
- logical volume free space.
- mapping(logical volume->physical volumes)
- and Haystack Cache.
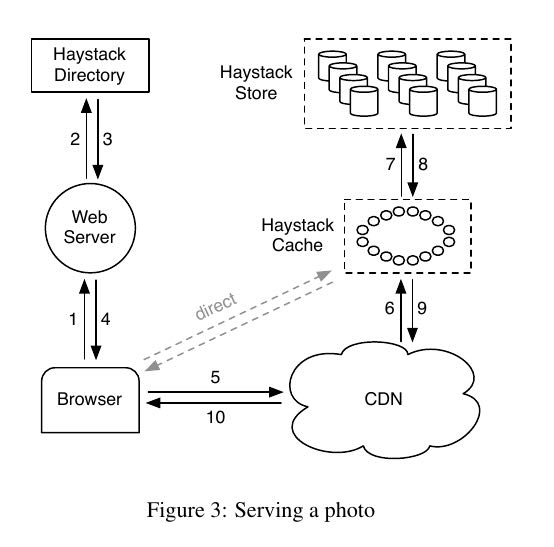
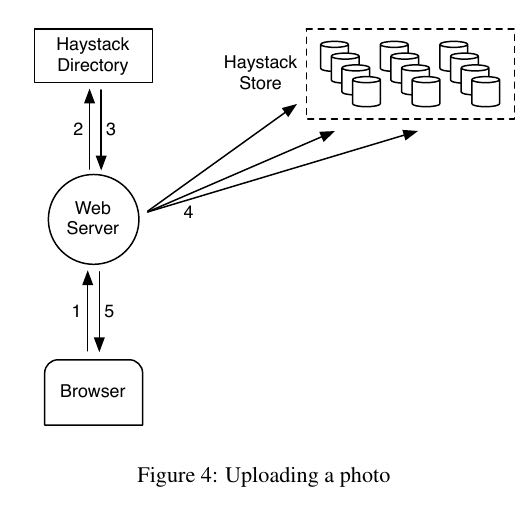
图片url格式是 "http://<CDN>/<Cache>/<Machine id>/<Logical volume, Photo>". 请求流程大致是:
- CDN解析最后部分<lv, photo>看是否在自己cache中, 如果不在的话. 那么去掉<CDN>部分请求<Cache>
- Cache和CDN一样. 如果找不到的话那么交给machine处理.
- machine根据<lv, photo>在磁盘上找到图片之后层级返回.
4.2. Haystack Directory
#note: 不知道是否支持副本自动迁移
The Directory serves four main functions.
- First, it pro-vides a mapping from logical volumes to physical vol-umes. Web servers use this mapping when uploading photos and also when constructing the image URLs for a page request. # 映射关系
- Second, the Directory load balances writes across logical volumes and reads across physi-cal volumes. # 在各个节点以及volumes之间平衡.
- Third, the Directory determines whether a photo request should be handled by the CDN or by the Cache. This functionality lets us adjust our depen-dence on CDNs. # 系统灵活性
- Fourth, the Directory identifies those logical volumes that are read-only either because of op-erational reasons or because those volumes have reached their storage capacity. We mark volumes as read-only at the granularity of machines for operational ease. # 方便运维
The Directory is a relatively straight-forward compo-nent that stores its information in a replicated database accessed via a PHP interface that leverages memcache. In the event that we lose the data on a Store machine we remove the corresponding entry in the mapping and replace it when a new Store machine is brought online. # 数据存储在replicated database前面有memcache. (#note: 似乎没有办法进行自动迁移)
4.3. Haystack Cache
We now highlight an important behavioral aspect of the Cache. It caches a photo only if two conditions are met:
- (a) the request comes directly from a user and not the CDN and # 如果有CDN的话那么就不使用Cache
- The justification for the first condition is that our experience with the NFS-based de-sign showed post-CDN caching is ineffective as it is un-likely that a request that misses in the CDN would hit in our internal cache. # 根据使用NFS方案经验来看, post-CDN caching基本没有效果.
- (b) the photo is fetched from a write-enabled Store machine. # 只缓存从write-enabled machine取的数据.
- photos are most heavily accessed soon after they are uploaded. # 最近上传的图片有可能很快就会被大量访问
- filesystems for our workload gener-ally perform better when doing either reads or writes but not both. # 平衡读写比例
4.4. Haystack Store
Each Store machine manages multiple physical vol-umes. Each volume holds millions of photos. For concreteness, the reader can think of a physical vol-ume as simply a very large file (100 GB) saved as '/hay/haystack_<logical volume id>'. # 一个logical volumn在一台机器上只有一个对应的physical volume. 这是redundancy的需要, 同时也简化了文件组织.
A Store machine keeps open file descriptors for each physical volume that it manages and also an in-memory mapping of photo ids to the filesystem meta-data (i.e., file, offset and size in bytes) critical for re-trieving that photo. # 每个store machine保存了fds, 以及维护内存表用于id->metadata的映射. metadata包括文件(fd, offset, size). 这样在内存中就可以定位到文件位置.
下图是文件存储格式:
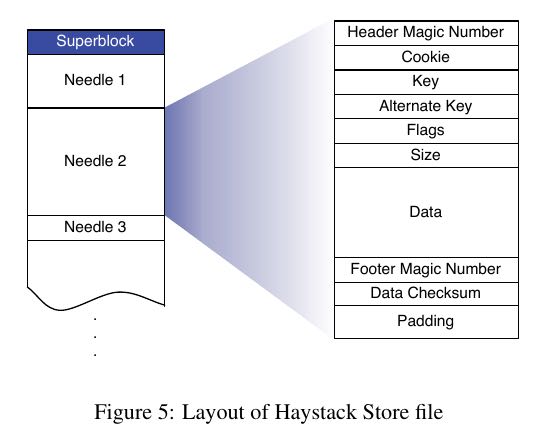
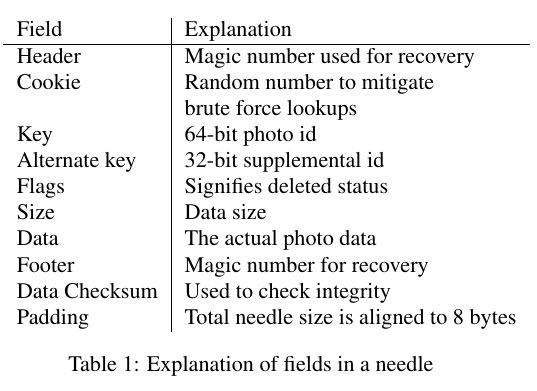
- alternate key用来表示不同大小的类型, 比如100 * 100, 200 * 200 etc.
- cookie 字段是在upload时候随机生成的. 这样可以避免猜测url来获取图片.
- 对于store-file的追加是同步完成的.
index文件可以用来加快映射表的生成:
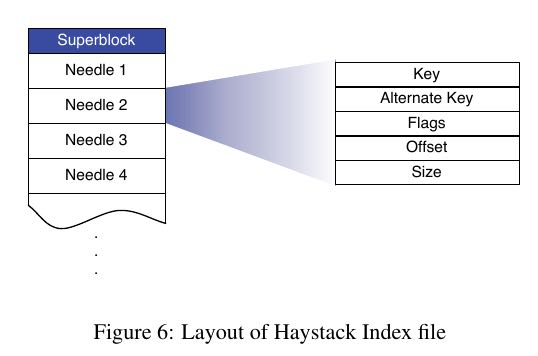

index文件是在追加store-file时候异步写入的. 那么这里有个问题就是: 通过index文件构建的映射表并不是store-file的真实反应. 但是有个比较简单的同步办法: 我们可以首先找到index-file里面最大的offset, 然后从这个offset开始读取store-file来补全index-file. 另外一个问题是即使按照这个办法, store-file可能存在一些删除文件, 但是在index里面没有反应. 这个问题我们可以惰性解决: 如果index显示存在, 但是在访问store-file实际不存在的话, 那么我们再来修改index.
4.5. Recovery from failures
#note: 自动检测, 人工修复.
To proactively find Store machines that are having problems, we maintain a background task, dubbed pitch-fork, that periodically checks the health of each Store machine. Pitchfork remotely tests the connection to each Store machine, checks the availability of each vol-ume file, and attempts to read data from the Store ma-chine. If pitchfork determines that a Store machine con-sistently fails these health checks then pitchfork auto-matically marks all logical volumes that reside on that Store machine as read-only. We manually address the underlying cause for the failed checks offline. # 后台任务pitchfork检查每个store machine的状态. 一旦发现存在问题那么立刻将这个machine上所有的logica volumes标记为read-only. 然后人工线下来分析原因
Once diagnosed, we may be able to fix the prob-lem quickly. Occasionally, the situation requires a more heavy-handed bulk sync operation in which we reset the data of a Store machine using the volume files supplied by a replica. Bulk syncs happen rarely (a few each month) and are simple albeit slow to carry out. The main bottleneck is that the amount of data to be bulk synced is often orders of magnitude greater than the speed of the NIC on each Store machine, resulting in hours for mean time to recovery. We are actively exploring techniques to address this constraint. # 如果我们不能够修复的话, 那么可能需要从其他机器上, 将故障机器上的logical volumes replicas, 同步到新机器上. 但是这个过程非常漫长, 数据量通常是NIC的几个量级.
4.6. Optimizations
- Compaction
- Saving more memory
- Batch upload