Hadoop I/O: Sequence, Map, Set, Array, BloomMap Files
http://blog.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
SequenceFile存储格式如下

内部有三种可选的存储格式:
- “Uncompressed” format
- “Record Compressed” format
- “Block-Compressed” format
然后使用哪种格式以及元信息是在Header里面标记的

其中metadata部分可以存储这个文件的一些元信息,存储格式也非常简单。key和value只是允许Text格式,并且在创建的时候就需要指定

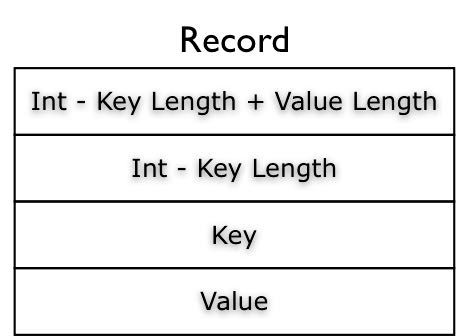
至于里面的record/block存储格式如下
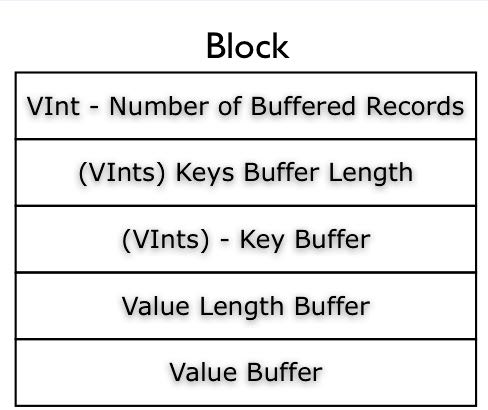
至于Compress算法,这个在Header里面的Compress Codec Class Name里面就指定了。
Hadoop SequenceFile is the base data structure for the other types of files, like MapFile, SetFile, ArrayFile and BloomMapFile.
MapFile是由两个SequenceFile组成,一个是index文件,一个是data文件。data文件里面的key是顺序存储的,index文件是data中key的部分索引. index的key和data的key相同,而value是这个record在data文件中的偏移,至于这个索引间隔可以通过setIndexInterval来设置。操作的时候会将index全部都读取到内存,然后在index里面所二分查找,然后在data文件里面做顺序查找。 #note: 如果data文件要压缩的话,那么这个边界必须和index对应
SetFile是基于MapFile完成的,只不过value = NullWritable
ArrayFile也是基于MapFile完成的,只不过key = LongWriatble,然后每次写入都会+1
BloomMapFile扩展了MapFile添加了一个bloom文件,存储的是DynamicBloomFilter序列化内容。在判断key是否在MapFile之前,先走BloomFilter.