Hadoop权威指南(笔记)
Table of Contents
1. 初识Hadoop
古代,人们用牛来拉中午,当一头牛拉不动一根圆木的时候,他们不曾想过培育更大更壮的牛。同样,我们也不需要尝试开发超级计算机,而应试着结合使用更多计算机系统。
2. 关于MapReduce
- 设置HADOOP_CLASSPATH就可以直接使用hadoop CLASSNAME来在本地运行mapreduce程序。
- hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-0.20.2-cdh3u3.jar 可以用来启动streaming任务
- 使用stdin/stdout来作为输入和输出
- Input/Output Format
- 外围环境的访问比如访问hdfs以及hbase
- 程序打包。比如使用很多第三方库的话在其他机器上面没有部署。
- 使用stdin/stdout来作为输入和输出
- hadoop pipes 可以用来启动pipes任务
- Hadoop的Pipes是Hadoop MapReduce的C++接口代称
- 使用Unix Domain Socket来作为输入和输出
- #note: 可能使用上面还是没有native mr或者是streaming方式方便
3. Hadoop分布式文件系统
- 使用hadoop archive能够将大量小文档打包,存档文件之能够只读访问
- 使用hadoop archive -archiveName <file>.har -p <parent-path> src dst
- 存档过程使用mapreduce完成,输出结果为目录
- part-0 表示存档内容文件,应该是使用一个reduce做聚合。
- _index,_masterindex 是对存档内容文件的索引文件。
- har(hadoop archive)文件系统是建立在其他文件系统上面的,比如hdfs或者是local fs.
- hadoop fs -ls har:///file.har 那么访问的是默认的文件系统上面的file.har
- 如果想显示地访问hdfs文件系统的话,那么可以hadoop fs -ls har://hdfs-localhost:9000/file.har
- 如果想显示地访问本地文件系统的话,那么可以使用hadoop fs -ls har://file-localhost/file.har
- hadoop fs -ls har://schema-<host>/<path> 是通用的访问方式
4. Hadoop IO
- 文件系统
- ChecksumFileSystem
- 使用decorator设计模式,底层filesystem称为RawFileSystem
- 对于每个文件filename都会创建.filename.crc文件存储校验和
- 计算crc的单位大小通过io.bytes.per.checksum来进行控制
- 读取文件如果出现错误的话,那么会抛出ChecksumException
- 考虑到存在多副本的情况,如果读取某个副本出错的话,期间那么会调用reportChecksumFailure方法
- #note: 这个部分的代码不太好读,非常绕
- RawLocalFileSystem
- 本地文件系统
- LocalFileSystem
- RawLocalFileSystem + ChecksumFileSystem
- reportChecksumFailure实现为将校验和存在问题的文件移动到bad_files边际文件夹(side directory)
- DistributedFileSystem
- 分布式文件系统
- ChecksumDistributedFileSystem
- DistributedFileSystem + ChecksumFileSystem
- ChecksumFileSystem
- 压缩解压
- DEFLATE org.apache.hadoop.io.compress.DefaultCodec 扩展名.defalte
- Gzip org.apache.hadoop.io.compress.GzipCodec 扩展名.gz 使用DEFLATE算法但是增加了额外的文件头。
- bzip2 org.apache.hadoop.io.compress.BZip2Codec 扩展名.bz2 自身支持文件切分,内置同步点。
- LZO com.hadoop.compression.lzo.LzopCodec 扩展名.lzo 和lzop工具兼容,LZO算法增加了额外的文件头。
- LzopCodec则是纯lzo格式的codec,使用.lzo_deflate作为文件扩展名
- 因为LZO代码库拥有GPL许可,因此没有办法包含在Apache的发行版本里面。
- 运行MapReduce时候可能需要针对不同压缩文件解压读取,就需要构造CompressionCodec对象,我们可以通过CompressionCodecFactory来构造这个对象
- CompressionCodecFactory读取变量io.compression.codecs
- 然后根据输入文件的扩展名来选择使用何种codec.
- getDefaultExtension
- 压缩和解压算法可能同时存在Java实现和原生实现
- 如果是原生实现的话通常是.so,那么需要设置java.library.path或者是在环境变量里面设置LD_LIBRARY_PATH
- 如果同时有原生实现和Java实现,我们想只是使用原生实现的话,那么可以设置hadoop.native.lib = false来禁用原生实现。
- 压缩算法涉及到对应的InputFormat,也就涉及到是否支持切分
- 对于一些不支持切分的文件,可能存在一些外部工具来建立索引,从而支持切分。
- 下面这些选项可以针对map结果以及mapreduce结果进行压缩
- mapred.output.compress = true 将mapreduce结果做压缩
- mapred.output.compression.codec mapreduce压缩格式
- mapred.output.compress.type = BLOCK/RECORD 如果输出格式为SequenceFile的话,那么这个参数可以控制是块压缩还是记录压缩
- #note: 感觉MR的中间结果存储格式为SequenceFile
- #note: 应该是IFile,但是是否共享了这个配置呢
- mapred.compress.map.output = true 将map结果做压缩
- mapred.map.output.compression.codec map压缩格式
- 序列化
- Hadoop的序列化都是基于Writable实现的,WritableComparable则是同时继承Writable,Comparable<T>.
- 序列化对象需要实现RawComparator,接口为public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)进行二进制比较。
- WritableComparator简化了这个实现,继承WritableComparator就实现了这个接口
- 但是这个接口实现起来非常naive,就是将两个byte stream反序列化然后调用对象的compareTo实现
- 如果想要提高效率的话,可以考虑通过直接比较两个byte stream来做优化。
- 基于文件的数据结构
- SequenceFile 主要用来存储KV数据结构,多条记录之间会穿插一些同步标记,因此允许进行切分。
- 使用SequenceFileInputFormat和SequenceFileOutputFormat来读取和输出SequenceFile
- hadoop fs -text 可以用来读取文件
mapred.output.compress.type = BLOCK/RECORD 可以用来控制压缩方式
- 如果没有使用压缩的话,那么格式为 recordLength(4byte) + keyLength(4byte) + key + value
- 如果使用记录压缩的话,那么格式为 recordLnegth(4byte) + keyLength(4byte) + key + compressedValue
- 如果使用块压缩的话,那么格式为 numberRecord(1-5byte) + keyLength(4byte) + compressedKeys + valueLength(4byte) + compressedValues.每个block之间会插入sync标记
- 块压缩大小可以使用io.seqfile.compress.blocksize来控制,默认1MB
- MapFile 也是用来存储KV数据结构,但是可以认为已经按照了Key进行排序 #note: 要求添加顺序就按照Key排序
- 存储格式实际上也是SequenceFile,data,index都是。
- 底层会建立index,index在搜索的时候会加载到内存里面,这样可以减少data上的随机查询次数。
- 使用io.map.index.interval可以控制多少个item在index里面创建一个条目
使用io.map.index.skip = 0/1/2/n 可以控制skip几个index的item,如果为1的话那么表示只是使用1/2的索引。
- 从SequenceFile创建MapFile非常简单
- 首先使用sort将SequenceFile进行排序(可以使用hadoop example的sort)
- 然后调用hadoop MapFileFixer来建立索引
5. MapReduce应用开发
- Configuration用来读取配置文件,功能还是比较强大的,有变量替换的功能
- <property><name>…</name><value>…</value></property>
- 如果使用<final>true</final>标记的话那么这个变量不允许被重置
- 变量替换可以使用${variable}
- 通过addResource来添加读取的配置文件
- Hadoop集群有三种工作方式,分别为
- standalone 使用单个JVM进程来模拟
- 如果不进行任何配置的话默认使用这个模式
- fs.default.name = file 本地文件系统
- mapred.job.tracker = local
- pseudo-distributed 本地启动单节点集群
- fs.default.name = hdfs://localhost
- mapred.job.tracker = localhost:8021
- fully-distributed 完全分布式环境
- fs.default.name = hdfs://<namenode>
- mapred.job.tracer = <jobtracker>:8021
- standalone 使用单个JVM进程来模拟
- 使用hadoop启动MapReduce任务的常用参数
- -D property=value 覆盖默认配置属性
- -conf filename 添加配置文件
- -fs uri 设置默认文件系统
- -jt host:port 设置jobtracker
- -files file,file2 这些文件可以在tasktracker工作目录下面访问
- -archives archive,archive2 和files类似,但是是存档文件
- 突然觉得这个差别在files只能是平级结构,而archive可以是层级结构。
- -libjars jar1,jar2 和files类似,通常这些JAR文件是MapReduce所需要的。
如果希望运行时候动态创建集群的话,可以通过这几个类来创建
- MiniDFSCluster
- MiniMRCluster
- MiniHBaseCluster
- MiniZooKeeperClutser
另外还有自带的ClusterMapReduceTestCase以及HBaseTestingUtility来帮助进行mapreduce的testcase. 这些类散布在hadoop,hbase,hadoop-test以及hbase-test里面。
#note: 个人觉得可能还是没有本地测试方便
job,task and attempt
- jobID常见格式为 job_200904110811_0002
- 其中200904110811表示jobtracker从2009.04.11的08:11启动的
- 0002 表示第三个job,从0000开始计数。超过10000的话就不能够很好地排序
- taskID常见格式为 task_200904110811_0002_m_000003
- 前面一串数字和jobID匹配,表示从属于这个job
- m表示map任务,r表示reduce任务
- 000003表示这是第4个map任务。顺序是在初始化时候指定的,并不反应具体的执行顺序。
- attemptID常见格式为 attempt_200904110811_0002_m_000003_0
- 前面一串数字和taskID匹配,表示从属与这个task
- attempt出现的原因是因为一个task可能会因为失败重启或者是预测执行而执行多次
- 如果jobtracker重启而导致作业重启的话,那么做后面id从1000开始避免和原来的attempt冲突。
作业调试
- 相关配置
- mapred.jobtracker.completeuserjobs.maximum 表示web页面下面展示completed jobs的个数,默认是100,超过的部分放到历史信息页。
- mapred.jobtracker.restart.recover = true jobtracker重启之后自动恢复作业
- hadoop.job.history.location 历史作业信息存放位置,超过30天删除,默认在_logs/history
- hadoop.job.history.user.location 如果不为none那么历史作业信息在这里也会存在一份,不会删除。
- 相关命令
- hadoop fs -getmerge <src> <dst> 能够将hdfs的src下面所有的文件merge合并成为一份文件并且copy到本地
- hadoop job -history 察看作业历史
- hadoop job -counter 察看作业计数器
- 相关日志
- 系统守护进程日志 写入HADOOP_LOG_DIR里面,可以用来监控namenode以及datanode的运行情况
- MapReduce作业历史日志 _logs/history
- MapReduce任务日志 写入HADOOP_LOG_DIR/userlogs里面,可以用来监控每个job的运行情况
- 分析任务
- JobConf允许设置profile参数
- #note: 新的接口里面JobConf->JobContext->Job,Job没有这些接口,但是可以通过Configuration来设置
- setProfileEnabled 打开profile功能,默认false,属性 mapred.task.profile
- setProfileParams 设置profile参数
- JobConf允许设置profile参数
- 属性 mapred.task.profile.params
- 默认使用hprof -agentlib:hprof=cpu=samples,heap=sites,force=n,thread=y,verbose=n,file=%s"
其中%s会替换成为profile输出文件
- #note: 其实这里似乎也可以设置成为jmxremote来通过jvisualvm来调试
- setProfileTaskRange(boolean,String)
- 参数1表示针对map还是reduce task做profile, true表示map, false表示reduce
- 参数2表示针对哪些tasks做优化,"0-2"表示针对0,1,2三个任务,默认也是"0-2"
- map task对应属性mapred.task.profile.maps,reduce task对应属性mapred.task.profile.reduces
- 任务重现
- 首先将keep.failed.task.files设置为true,这样如果任务失败的话,那么这个任务的输入和输出都会保留下来
- 如果是map任务的话,那么输入分别会在本地保留
- 如果是reduce任务的话,那么对应的map任务输出会在本地保留
- 然后我们使用hadoop IsolationRunner job.xml来重新运行这个任务
- 可以修改HADOOP_OPTS添加远程调试选项来启动这个任务。
- 如果希望任务都保留而不仅仅是失败任务保留的话,那么可以设置 keep.task.files.pattern 为正则表达式(与保留的任务ID匹配)
- 首先将keep.failed.task.files设置为true,这样如果任务失败的话,那么这个任务的输入和输出都会保留下来
- 任务重现
6. MapReduce的工作机制
Hadoop运行MapReduce作业的工作原理
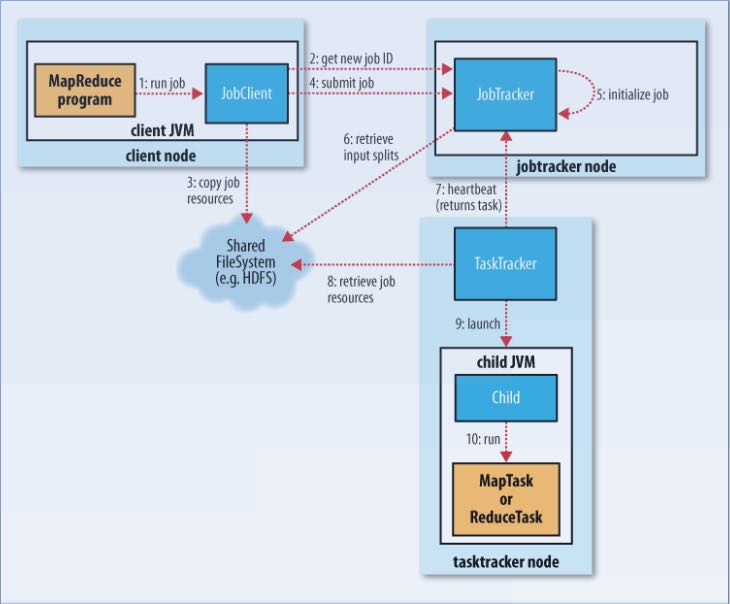
其中有几点需要注意的:
- 计算分片信息是在本地完成的,分片信息和其他resouce(包括jars,files,archives等)一起copy到HDFS上面,然后jobtracker直接读取分片信息。
- 提交的资源可以设置replication数目,高副本数目可以缓解tasktracker获取resource的压力。参数是mapred.submit.replication.
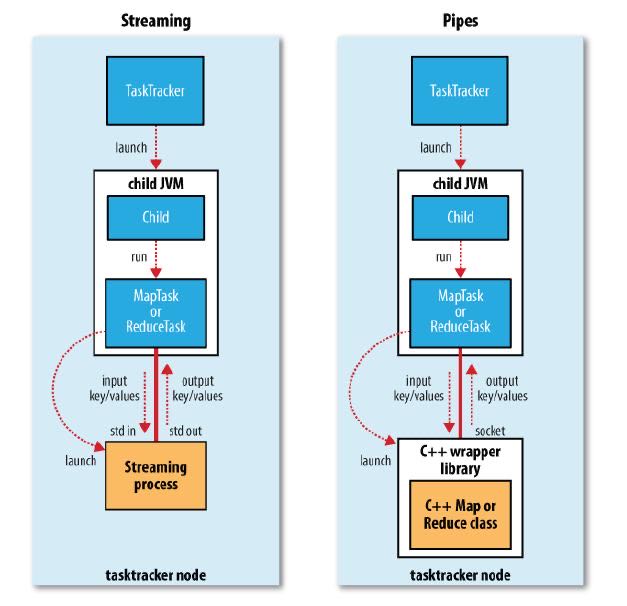
- 对于streaming以及pipes的实现,无非就是task并不直接执行任务,而是开辟另外一个子进程来运行streaming或者是pipes的程序。
进度和状态的更新
- map任务进度是已经处理输入的比例
- reduce任务进度分为三个部分
- shuffle 1/3
- sort 1/3
- reduce 1/3
- 也就是说如果刚运行完成sort的话,那么进度是2/3
- 状态的更新
- 触发事件
- 读取记录
- 输出记录
- 修改状态 reporter的setStatus
- 计数器修改
- reporter的progress
- 子进程有单独线程每隔3秒检查progress位是否设置,如果设置的话那么和tasktracker发起心跳
- 通过mapred.task.timeout控制
- tasktracker每隔5秒和jobtracker做心跳
- 心跳时间通过 mapred.tasktracker.expircy.interval 设置
- jobClient定期会去jobtracker询问job是否完成
- jobClient也可以设置属性job.end.notification.url,任务完成jobtracker会调用这个url
- 可以认为就是推拉方式的结合。
- 触发事件
失败检测和处理
- 任务失败
- 子进程抛出异常的话,tasktracker将异常信息记录到日志文件然后标记失败
- 对于streaming任务的话非0退出表示出现问题,也可以使用stream.non.zero.exit.is.failure = false来规避( 这样是否就没有办法判断是否正常退出了? )
- 如果长时间没有响应的话,没有和tasktracker有交互,那么也会认为失败。这个时间使用mapred.task.timeout控制,默认10min
- 如果任务失败的话,jobtracker会尝试进行多次重试
- map重试次数通过 mapred.map.max.attempts 配置
- reduce重试次数通过 mapre.reduce.max.attempts 配置
- 任何任务重试超过4次的话那么会认为整个job失败
- 另外需要区分KILLED状态和FAILED状态,对于KILLED状态可能是因为推测执行造成的,不会记录到failed attempts里面
- 如果我们希望允许少量任务失败的话,那么可以配置
- mapred.max.map.failures.percent 允许map失败的最大比率
- mapred.max.reduce.failures.percent 允许reduce失败的最大比率
- 如果一个job超过一定的task在某个tt上面运行失败的话,那么就会将这个tt加入到这个job的blacklist. mapred.max.tracker.failures = 4
- 如果job成功的话,检查运行task失败的tt并且标记,如果超过一定阈值的话,那么会将tt加入到全局的blacklist. mapred.max.tracker.blacklists = 4
作业的调度
- fifo scheduler
- 可以通过mapred.job.priority或者是setJobPriority设置
- 当队列中有空闲的槽位需要执行任务时,从等待队列中选择优先级最高的作业
- fair scheduler
- capacity scheduler
shuffle和排序
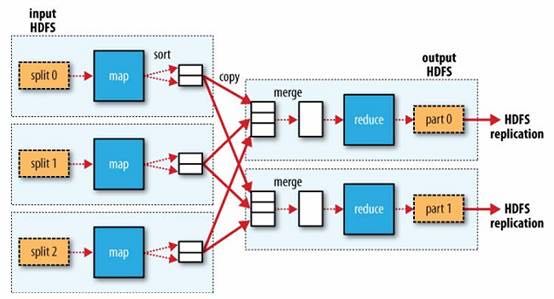
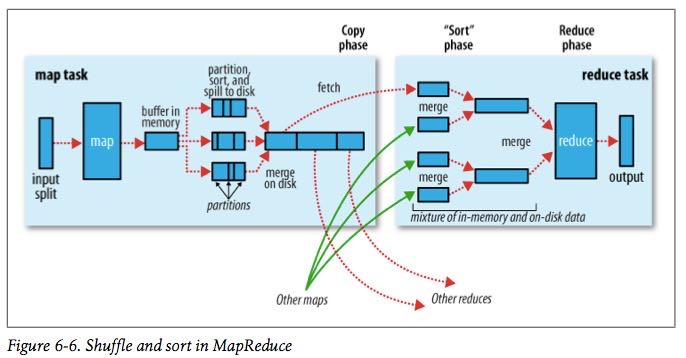
有下面这些参数控制shuffle和sort的过程 #note: 书上倒是有很多参数,但是好多还是不太理解
- io.sort.mb map输出缓存空间大小,默认是100MB. 建议设置10* io.sort.factor.
- io.sort.spill.percent 如果map输出超过了缓存空间大小的这个阈值的话,那么就会spill,默认是0.8
- 每次spill之前先会对这个文件进行排序,如果有combiner的话那么会在上面调用combiner
- 写磁盘是按照轮询的方式写到mapred.local.dir属性指定的目录下面
- 如果spill速度太慢的话,那么往缓存空间写入进程就会阻塞,直到spill腾出空间。
- io.sort.factor 多路归并的数量,默认是10. 建议设置在25-32.
- 在map阶段,因为最终会存在多个spill文件,所以需要做多路归并。#note: 如果归并数量少的话需要多次merge.
- 在reduce阶段的话,因为可能存在多路map输出的结果,所以需要做多路归并。
- min.num.spill.for.combine 如果指定combiner并且spill次数超过这个值的话就会调用combine,默认为3
- tasktracker.http.threads reduce通过HTTP接口来发起数据请求,这个就是HTTP接口相应线程数目,默认为40。 mapper as server
- mapred.reduce.parallel.copies reduce启动多少个线程去请求map输出,默认为5。 reducer as client
- #note: 如果reduce和每个map都使用一个线程去请求输出结果的话,只要shuffle阶段没有出现network congestion,那么提高线程数量是有效果的
- #note: 通常可以设置到15-50
- mapred.reduce.copy.backoff = 300(s) reduce下载线程最大等待时间
- mapred.job.shuffle.input.buffer.percent = 0.7 用来缓存shuffle数据的reduce task heap百分比
- mapred.job.shuffle.merge.percent = 0.66 缓存的内存中多少百分比后开始做merge操作
- mapred.job.reduce.input.buffer.percent = 0.0 sort完成后reduce计算阶段用来缓存数据的百分比. 默认来说不会使用任何内存来缓存,因此完全从磁盘上进行读取。
任务的执行
- 推测执行参数
- 如果某个任务执行缓慢的话会执行另外一个备份任务
- mapred.map.tasks.speculative.execution true
- mapred.reduce.tasks.speculative.execution true
- JVM重用
- 一个JVM实例可以用来执行多个task.
- mapred.job.reuse.jvm.num.tasks/setNumTasksToExecutePerJvm 单个JVM运行任务的最大数目
- -1表示没有限制
- 任务执行环境
- 程序自身可以知道执行环境对于开发还是比较有帮助的
- 这些属性对于streaming可以通过环境变量获得
- mapred.job.id string jobID
- mapred.tip.id string taskID
- mapred.task.id string attemptID
- mapred.task.partition int 作业中任务编号
- mapred.task.is.map boolean 是否为map
- mapred.work.output.dir / FileOutputFormat.getWorkOutputPath 当前工作目录
- 杂项
- mapred.job.map.capacity # 最大同时运行map数量
- mapred.job.reduce.capacity # 最大同时运行reduce数量
- mapred.job.queue.name # 选择执行queue
7. MapReduce的类型与格式
MapReduce的类型
老API里面还有MapRunner这个类,这个类主要的作用是可以用来控制Mapper运行的方法,比如可以多线程来控制Mapper的运行。 但是在新API里面已经完全集成到Mapper实现里面来了,用户可以重写两个方法来完全控制mapper的运行
- map 如何处理kv
- run 如何从context里面读取kv
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
#note: 觉得这个特性不是特别有用
- mapred.input.format.class setInputFormat
- mapred.mapoutput.key.class setMapOutputKeyClass
- mapred.mapoutput.value.class setMapOutputValueClass
- mapred.output.key.class setOutputKeyClass
- mapred.output.value.class setOutputValueClass
- mapred.mapper.class setMapperClass
- mapred.map.runner.class setMapRunnerClass
- mapred.combiner.class setCombinerClass
- mapred.partitioner.class setPartitionerClass
- mapred.output.key.comparator.class setOutputKeyComparatorClass
- mapred.output.value.groupfn.class setOutputValueGroupingComparator
- mapred.reducer.class setReducerClass
- mapred.output.format.class setOutputFormat
输入格式
对于InputFormat来说包含两个任务
- 根据job描述来对输入进行切片(InputSplit)
- 根据切片信息来读取记录(RecordReader)
public abstract class InputFormat<K, V> {
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
public abstract class InputSplit {
public abstract long getLength() throws IOException, InterruptedException;
public abstract
String[] getLocations() throws IOException, InterruptedException;
}
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
public abstract float getProgress() throws IOException, InterruptedException;
public abstract void close() throws IOException;
}
下面是一些常见的InputFormat实现
- FileInputFormat
- addInputPath或者是setInputPaths修改输入路径 mapred.input.dir
- setInputPathFilter可以修改过滤器 mapred.input.path.Filter.class
- 基本实现会排除隐藏.或者是_开头文件。
- 自定义的过滤器是建立在默认过滤器的基础上的。
- 分片大小由下面三个参数控制
- mapred.min.split.size 1
- mapred.max.split.size MAX
- dfs.block.size 64MB
- 算法是max(minSplitSize,min(maxSplitSize,blockSize))
- isSplitable可以控制输入文件是否需要分片
- CombineFileInputFormat 可以处理多个小文件输入,抽象类需要继承实现。
- TextInputFormat
- 输入单位是行,key是LongWritable表示行偏移,value是Text表示行内容
- KeyValueTextInputFormat
- 输入单位是行,按照key.value.seperator.in.input.line来进行分隔默认是\t
- key和value的格式都是Text
- NLineInputFormat
- 和TextInputFormat非常类似,大师使用多行输入默认为1行
- 通过mapred.line.input.format.linespermap来控制行数
- XML
- InputFormat使用StreamInputFormat,
- 设置RecordReader使用stream.recordreader.class来设置
- RecordReader使用org.apache.hadoop.streaming.StreamXmlRecordReader
- #note: 也有现成的XmlInputFormat的实现
- SequenceFileInputFormat
- SequenceFileAsTextInputFormat
- 将输入的kv转换成为text对象适合streaming处理方式
- SequenceFileAsBinaryInputFormat #note: 似乎没有什么用
- MultipleInputs
- DBInputFormat/DBOutputFormat JDBC数据库输入输出
- TableInputFormat/TableOutputFormat HBase输入输出
输出格式
- TextOutputFormat
- 使用mpared.textoutputformat.seperator来控制kv的分隔,默认是\t
- 对应的输入格式为KeyValueTextInputFormat
- 可以使用NullWritable来忽略输出的k或者是v
- SequenceFileOutputFormat
- SequenceFileAsBinaryOutpuFormat #note: 似乎没有什么用
- MapFileOutputFormat
- MultipleOutputFormat
- MultipleOutputs
- 如果不像生成那写part-r-00000这些空文件的话,那么可以将OutputFormat设置成为NullOutputFormat
- 但是使用NullOutputFormat的话会没有输出目录,如果想保留目录的话那么可以使用LazyOutputFormat
8. MapReduce的特性
- 计数器
- streaming计数器和可以通过写stderr来提交
- reporter:counter:<group>,<counter>,<amount>
- reporter:status:<message>
- streaming计数器和可以通过写stderr来提交
- 连接
- map端连接
- 必须确保多路输入文件的reduce数量相同以及键相同。
- 使用CompositeInputFormat来运行map端连接。
- #note: 稍微看了一下代码,实现上其实也是针对输入文件对每条记录读取,然后进行join包括inner或者是outer。感觉场景会有限,而且效率不会太高
- map端连接
- 分布式缓存
- 使用-files以及-archives来添加缓存文件
- 也可以使用DistributedAPI来完成之间事情
- addCacheFile/addCacheArchive
- 然后在task里面通过configuration的getLocalCacheFiles以及getLocalCacheArchives来获得这些缓存文件
- 工作原理
- 缓存文件首先被放到hdfs上面
- task需要的话那么会尝试下载,之后会对这个缓存文件进行引用计数,如果为0那么删除
- 这也就意味着缓存文件可能会被多次下载
- 但是运气好的话多个task在一个node上面的话那么就不用重复下载
- 缓存文件存放在${mapred.local.dir}/taskTracker/archive下面,但是通过软连接指向工作目录
- 缓存大小通过local.cache.size来配置
- MapReduce库类
- ChainMapper/ChainReducer 能够在一个mapper以及reducer里面运行多次mapper以及reducer
- ChainMapper 允许在Map阶段,多个mapper组成一个chain,然后连续进行调用
- ChainReducer 允许在Reuduce阶段,reducer完成之后执行一个mapper chain.
- 最终达到的效果就是 M+ -> R -> M* (1个或者是多个mapper, 一个reducer,然后0个或者是多个mapper)
- #todo: 这样做倒是可以将各个mapper组合起来用作adapter.
- ChainMapper/ChainReducer 能够在一个mapper以及reducer里面运行多次mapper以及reducer
9. 构建Hadoop集群
- 很多教程说hadoop集群需要配置ssh,但是配置这个前提是你希望使用start-all.sh这个脚本来启动集群
- 我现在的公司使用apt-get来安装,使用cssh来登陆到所有的节点上面进行配置,因此没有配置这个信任关系
- Hadoop配置
- 配置文件
- hadoop-env.sh 环境变量脚本
- core-site.xml core配置,包括hdfs以及mapred的IO配置等
- hdfs-site.xml hadoop进程配置比如namenode以及datanode以及secondary namenode
- mapred-site.xml mapred进程配置比如jobtracker以及tasktracker
- masters 运行namenode(secondary namenode)的机器列表,每行一个, 无需分发到各个节点,在本地启动primary namenode
- slaves 运行datanode以及tasktracker的机器列表,每行一个 无需分发到各个节点,在本地启动jobtracker
- hadoop-metrics.properties 对hadoop做监控的配置文件
- log4j.properties 日志配置文件
- 这些文件在conf目录下面有,如果想使用不同的文件也可以使用-config来另行指定
- hadoop-env.sh
- HADOOP_HEAPSIZE = 1000MB 守护进程大小
- HADOOP_NAMENODE_OPTS
- HADOOP_SECONDARYNAMENODE_OPTS
- HADOOP_IDENT_STRING 用户名称标记,默认为${USER}
- HADOOP_LOG_DIR hadoop日志文件,默认是HADOOP_INSTALL/logs
- core-site.xml
- io.file.buffer.size IO操作缓冲区大小,默认是4KB 这个需要提高
- hdfs-site.xml
- fs.default.name
- hadoop.tmp.dir hadoop临时目录,默认是在/tmp/hadoop-${user.name}
- dfs.name.dir namenode数据目录,一系列的目录,namenode内容会同时备份在所有指定的目录中。默认为${hadoop.tmp.dir}/dfs/name
- dfs.data.dir datanode数据目录,一系列的目录,循环将数据写在各个目录里面。默认是${hadoop.tmp.dir}/dfs/data
- fs.checkpoint.dir secondarynamenode数据目录,一系列目录,所有目录都会写一份。默认为${hadoop.tmp.dir}/dfs/namesecondary
- dfs.namenode.handler.count namenode上用来处理请求的线程数目
- dfs.datanode.ipc.address 0.0.0.0:50020 datanode的RPC接口,主要和namenode交互
- dfs.datanode.address 0.0.0.0:50010 datanode的data block传输接口,主要和client交互
- dfs.datanode.http.address 0.0.0.0:50075 datanode的HTTP接口,和user交互
- dfs.datanode.handler.count datanode上用来处理请求的线程数目
- dfs.datanode.max.xcievers datanode允许最多同时打开的文件数量
- dfs.http.address 0.0.0.0:50070 namenode的HTTP接口
- dfs.secondary.http.address 0.0.0.0:50090 secondard namenode的HTTP接口
- dfs.datanode.dns.interface default 绑定的NIC,默认是绑定默认的NIC比如eth0
- dfs.hosts / dfs.hosts.exclude 加入的datanode以及排除的datanode
- dfs.replication = 3 副本数目
- dfs.block.size = 64MB
- dfs.datanode.du.reserved 默认datanode会使用目录所在磁盘所有空间,这个值可以保证有多少空间被reserved的
- fs.trash.interval 单位分钟,如果不为0的话,那么删除文件会移动到回收站,超过这个单位时间的文件才会完全删除。
- 回收站位置/home/${user]/.Trash
- #note: 回收站这个功能只是对fs shell有效。fs shell remove时候会构造Trash这个类来处理删除文件的请求。如果调用Java API的话那么会直接删除文件
- haddop fs -expunge 强制删除
- #note: grep代码发现只有NameNode在TrashEmptier里面构造了Trash这个类,因此这个配置之需要在nn上配置即可,决定多久定期删除垃圾文件
- fs.trash.checkpoint.interval 单位分钟,namenode多久检查一次文件是否需要删除。
- #note: 似乎没有这个参数。如果没有这个参数的话,那么两次检查时长应该是由参数fs.trasn.interval来决定
- mapred-site.xml
- mapred.job.tracker
- mapred.local.dir MR中间数据存储,一系列目录,分散写到各个目录下面,默认为${hadoop.tmp.dir}/mapred/local
- mapred.system.dir MR运行期间存储,比如存放jar或者是缓存文件等。默认${hadoop.tmp.dir}/mapred/system
- mapred.tasktracker.map.tasks.maximum = 2 单个tasktracker最多多少map任务
- mapred.tasktracker.reduce.tasks.maximum = 2 单个tasktracker最多多少个reduce任务
- mapred.tasktracker.dns.interface default 绑定的NIC,默认是绑定默认的NIC比如eth0
- mapred.child.ulimit 单个tasktracker允许子进程占用的最大内存空间。通常为2-3* mapred.child.java.opts.
- mapred.child.java.opts = -Xmx200m 每个子JVM进程200M. #note: 这个是在提交机器上面设置的,而不是每个tasktracker上面设置的,每个job可以不同
- 不一定支持将map/reduce的jvm参数分开设置 http://hadoop-common.472056.n3.nabble.com/separate-JVM-flags-for-map-and-reduce-tasks-td743351.html
- #note: 个人折中思路是限制内存大小为1G,然后大内存机器允许同时执行map/reduce数量上限提高,通过增加job的map/reduce数量来提高并发增加性能
- #note: 我grep了一下cdh3u3的代码,应该是将map/reduce的jvm参数分开进行了设置
- mapred.map.child.java.opts
- mapred.reduce.child.java.opts
- mapred.task.tracker.report.address 127.0.0.1:0 tasktracker启动子进程通信的端口,0表示使用任意端口
- mapred.task.tracker.expiry.interval 600(sec) tt和jt之间的心跳间隔
- mapred.job.tracker.handler.count. jobtracker用来处理请求的线程数目。
- mapred.job.tracker.http.address 0.0.0.0:50030 jobtracker的HTTP接口
- mapred.task.tracker.http.address 0.0.0.0:50060 tasktrackder的HTTP接口
- mapred.hosts / mapred.hosts.exclude 加入的tasktracker以及排除的tasktracker.
- 配置文件
- Hadoop Benchmark
- 在hadoop安装目录下面有jar可以来做基准测试
- TestDFSIO测试HDFS的IO性能
- Sort测试MapReduce性能
- MRBench多次运行一个小作业来检验小作业能否快速相应
- NNBench测试namenode硬件的负载
10. 管理Hadoop
- 永久性数据结构
- namenode的目录结构
- current表示当前的namenode数据(对于辅助节点上这个数据并不是最新的)
- previous.checkpoint表示secondarynamenode完成checkpoint的数据(和current可能存在一些编辑差距)
- hadoop dfsadmin -saveNamespace 可以强制创建检查点,仅仅在安全模式下面运行
- 辅助namenode每隔5分钟会检查
- 如果超过fs.checkpoint.period = 3600(sec),那么会创建检查点
- 如果编辑日志大小超过fs.checkpoint.size = 64MB,同样也会创建检查点
- 除了将文件copy到namenode之外,在辅助节点上面可以使用选项-importCheckpoint来载入
- VERSION Java属性文件
- namespaceID 每次格式化都会重新生成一个ID,这样可以防止错误的datanode加入
- cTime namenode存储系统创建时间,对于刚格式化的存储系统为0.对于升级的话会更新到最新的时间戳
- storageType NAME_NODE or DATA_NODE
- layoutVersion 负整数表示hdfs文件系统布局版本号,对于hadoop升级的话这个版本号可能不会变化
- edits 编辑日志文件
- fsimage 镜像文件
- fstime ???
- datanode的目录结构
- blk_<id>以及blk_<id>.meta 表示块数据以及对应的元信息,元数据主要包括校验和等内容
- 如果datanode文件非常多的话,超过dfs.datanode.numblocks = 64的话,那么会创建一个目录单独存放,最终结果就是形成树存储结构。
- dfs.data.dir目录是按照round-robin的算法选择的。
- namenode的目录结构
- 安全模式
- namenode启动的时候会尝试合并edit数据并且新建一个checkpoint,然后进入安全模式,在这个模式内文件系统是只读的
- 可以通过hadoop dfsadmin -safemode来操作安全模式
- 当达到下面几个条件的时候会离开安全模式
- 整个系统的副本数目大于某个阈值的副本数目比率超过一个阈值之后,然后继续等待一段时间就会离开安全模式
- dfs.replication.min = 1 副本数目阈值
- dfs.safemode.threshold.pct = 0.999 比率阈值
- dfs.safemode.extension = 30000(ms) 等待时间
- 工具
- dfsadmin
- fsck
- scanner
- DataBlockScanner每隔一段时间会扫描本地的data block检查是否出现校验和问题
- 时间间隔是dfs.datanode.scan.period.hours = 504默认三周
- 可以通过页面访问每个datanode的block情况 http://localhost:50075/blockScannerReport
- 加上listblocks参数可以看每个block情况 http://localhost:50075/blockScannerReport?listblocks #note: 结果会很大
- balancer
- 通过start-balancer.sh来启动,集群中只允许存在一个均衡器
- 均衡的标准是datanode的利用率和集群平均利用率的插值,如果超过某个阈值就会进行block movement
- -threshold可以执行阈值,默认为10%
- dfs.balance.bandwidthPerSec = 1024 * 1024 用于balance的带宽上限。
- 监控
- 日志
- jobtracker的stack信息(thread-dump)http://localhost:50030/stacks
- 度量
- 度量从属于特性的上下文(context),包括下面几个
- dfs
- mapred
- rpc
- jvm
- 下面是几种常见的context
- FileContext 度量写到文件
- GangliaContext 度量写到ganglia (这个似乎比较靠谱)
- CompositeContext 组合context
- 度量可以从hadoop-metrics.properties进行配置
- 度量从属于特性的上下文(context),包括下面几个
- 日志