HA Namenode for HDFS with Hadoop 1.0
http://hortonworks.com/blog/ha-namenode-for-hdfs-with-hadoop-1-0-part-1/
Hadoop1 NameNode HA code failover with LinuxHA
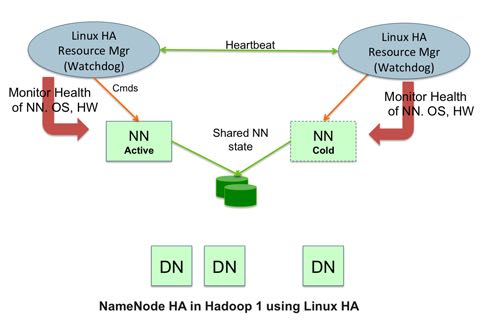
Failover Times and Cold versus Hot Failover
The failover time of a high available system with active-passive failover is the sum of (1) time to detect that the active service has failed, (2) time to elect a leader and/or for the leader to make a failover decision and communicate to the other party, and (3) the time to transition the standby service to active.
The first and second items are the same for cold or hot failover: they both rely on heartbeat timeouts, monitoring probe timeouts, etc. We have observed that total combined time for failure detection and leader election to range from 30 seconds to 2.5 minutes depending on the kind of failure; the lowest times are typical when the active server’s host or host operating system fails; hung processes take longer due to the grace period needed to be confident that the process is not blocked during Garbage Collection.
For the third item, the time to transition the standby service to active, Hadoop 1 requires starting a second NameNode and for the NameNode to get out of safe mode. In our experiments we have observed the following times:
- A 60 node cluster with 6 million blocks using 300TB raw storage, and 100K files: 30 seconds. Hence total failover time ranges from 1-3 minutes.
- A 200 node cluster with 20 million blocks occupying 1PB raw storage and 1 million files: 110 seconds. Hence total failover time ranges from 2.5 to 4.5 minutes.