Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing
Mesa有几个比较重要的Requirements:
- Atomic Updates. 原子性的数据更新,实现上就是靠MVCC
- Strong Consistency. 可以认为是上面一点的延续
- Availability and Scalability. PB,trillion rows 级别,跨区域副本
- Query Performance. 99th latency是几百毫秒,不能用作online serving
- Online Data and Schema Change. 在线Schema Change
Mesa底层用了许多Google已有的基础架构,Colossus,BigTable and MapReduce. 跨区域的一致性算法是Paxos,主要是确保写入多个DC写入到BigTable里面的metadata是一致的。
Fact Table里面每个记录可以认为有两个属性:dimensional【维度】 and measure【测量】,这个属于可能和OLAP有关系,这里就算是复习一下。其中测量属性就是具体的数值通常就是values,而维度属性就是描述这个数值的上下文通常就是keys. 比如“顾客A在商场B买了东西C花费100元”,那么keys可以是(A, B, C), values可以是(100). 这只是一种划分方法。这种划分可以帮助我们,我们要针对那些值进行aggregation,针对哪些维度做drill-downs和roll-ups.
在Update上有两个特点:atomicity and strict ordering. 其中atomicity就是最开始说的,需要确保某次更新是原子的,否则会出现数据不一致的问题。考虑到这个系统是应用在广告系统报表上的,这点就显得更加重要。atomicity的实现是通过MVCC来完成的,每次Update会产生一个version number(自增?), 只有等到完成这个version number才是可见的。strict ordering则要求多个updates是顺序apply的,论文里面说这个好处是可以做negative facts,比如检测到某个广告上有fraud的话可以在费用结算上加一个negative value的update.
每次Update会对应一个version, 如果有大量small updates的话很快就会出现爆炸的情况,解决办法就是做pre-aggregation. 做了pre-aggregation之后,一方面可以节省存储空间,另外一方面也可以节省query的时间。不过我理解这个pre-aggregation具体的policy是可以定制的,比如对某个value做add, 而对其他value做min/max这样。我也想象不到具体的场景是什么,所以只能理解到这里了。这个pre-aggregation在文章里面也叫做compaction, 其实和LSM-Tree compaction原理非常类似。分几个level: singleton(单次更新), cumulatives(中间聚合结果), base.

"Physical Data & Index Formats" 这节我看的不是很懂,感觉上和leveldb file format非常类似:列式存储,按照row blocks进行压缩,在data file的header/footer加index信息等等。这些Data Files存储在Colossus上面,而metadata信息则存储在BigTable上。我理解Metadata里面会包含所有的data files, 以及每个data files的key ranges以及bloom filter这样的东西,可以帮助query快速地过滤掉某些data files.
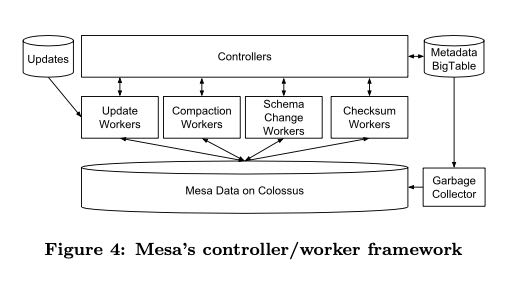
Mesa 中Updater架构图如下,master/worker这样的结构,从文中看是双向的:master可以要求worker去执行某个任务,而worker也可以问master要某个任务。值得一提的是,master是没有状态的,所有的状态都可以记录在bigtable上,所以master的扩展性很好比如可以按照table做shard. 可以看到worker也分了好几类,可能他们之间的workload差异比较大吧。
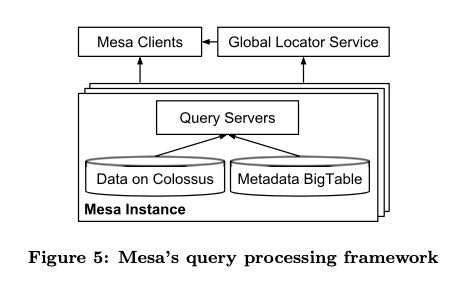
Mesa 中Query System架构图如下,因为应用场景相对比较单一,所以没有提供类似SQL这样的接口,只是提供某些操作比如filtering和aggregation ops. 因为数据都存储在Colossus上面,所以fetch数据的延迟相比从本地读会高很多,所以Query Servers利用cache应该是比较多的(这种计算和存储分离架构,不用cache是不行的)。理论上任何一个QS可以去访问any table, 实际上将QS划分到了多个sets下面. 每个set里面的QS只能访问一些tables, 这样这些table cache hit rate就可以做到很高。
在Query上除了剪枝之外,还有两个改进:一个是scan-to-seek. 假设我们要找到(A, B=2)这些keys, 但是我们是按照(A, B)做的索引。假设我们知道A的keys有[1,4,..]的话,那么我们可以先找到(A=1, B=2) 然后从这里开始scan. 下次找到(A=4, B=2) 然后从这里scan. 另外一个改进就是failover handoff,类似断点续传,但是我也没有搞清楚现实中怎么搞。Mesa底层计算引擎是MapReduce, 如果确定每个mapper的输入是个问题,这点在updater写data files会对row key进行sampling, 将采样结果单独存放。当MapReduce需要处理某些data files的时候,可以大致知道row keys的分布是什么,以此来确定每个mapper的输入。
Online Schema Change 有两种实现方式,一种比较笨就是重写一份,另外一种是针对增加column进行的优化,就是在query的时候针对没有column的记录认为是某个default value. 在检测数据损坏上,Mesa有好几个地方做了数据校验:1. compaction校验结果是否正确 2. 读取的时候校验checksum是否一致 3. Global Offline Checker会校验instance之间数据是否一致。细节太多,很多我也看的不是很明白。
最后关于经验总结,我觉得有两点值得学习:第一点就是云计算时代的基础架构设计的变化,就比如Mesa数据是放在Colossus上的,其他开源系统可能放在S3上,存储和计算分离是个趋势。为此Query Server需要做比较激进的pre-fetch & caching,以及利用好MapReduce parallelism才能把性能提高上去。第二点就是软件实现上的模块化虽然会有性能问题,但是可以显著地降低系统设计的复杂度。
Distribution, Parallelism, and Cloud Computing. Mesa is able to manage large rates of data growth through its absolute reliance on the principles of distribution and paral- lelism. The cloud computing paradigm in conjunction with a decentralized architecture has proven to be very useful to scale with growth in data and query load. Moving from spe- cialized high performance dedicated machines to this new environment with generic server machines poses interesting challenges in terms of overall system performance. New approaches are needed to offset the limited capabilities of the generic machines in this environment, where techniques which often perform well for dedicated high performance machines may not always work. For example, with data now distributed over possibly thousands of machines, Mesa’s query servers aggressively pre-fetch data from Colossus and use a lot of parallelism to offset the performance degrada- tion from migrating the data from local disks to Colossus.
Modularity, Abstraction and Layered Architecture. We recognize that layered design and architecture is crucial to confront system complexity even if it comes at the expense of loss of performance. At Google, we have benefited from modularity and abstraction of lower-level architectural com- ponents such as Colossus and BigTable, which have allowed us to focus on the architectural components of Mesa. Our task would have been much harder if we had to build Mesa from scratch using bare machines.