GCC内嵌汇编
Table of Contents
1. 基本形式
__asm__ __volatile__( "xorps %%xmm0,%%xmm1\n\t" "1:\n\t" "movdqa %%xmm0,%%xmm1\n\t" "pcmpgtd (%1),%%xmm1\n\t" "andps %%xmm1,%%xmm0\n\t" "andnps (%1),%%xmm1\n\t" "orps %%xmm1,%%xmm0\n\t" "addq $16,%1\n\t" "subq $4,%2\n\t" "jnz 1b\n\t" "movdqu %%xmm0,(%3)\n\t" "movl (%3),%%eax\n\t" "cmpl 4(%3),%%eax\n\t" "cmovll 4(%3),%%eax\n\t" "cmpl 8(%3),%%eax\n\t" "cmovll 8(%3),%%eax\n\t" "cmpl 12(%3),%%eax\n\t" "cmovll 12(%3),%%eax\n\t" "movl %%eax,%0\n\t" :"=m"(mx) :"r"(a),"r"((long long)N),"r"(tmp) :"eax");
一共包含4个部分,之间使用:分隔.
- instruction指令.每条指令之后最好使用"\n\t"结尾,这样在gcc产生汇编格式比较好.
- output operand输出.每个输出部分使用,分隔."="作为修饰符,"m"表示存放位置/约束符,()里面表示对应C程序值.
- input operand输入.这个部分和输出是一样的.
- clobber.这个部分是告诉gcc在这条指令里面我们会修改什么值.
汇编扩展以__asm__开头表示后面部分为汇编,__volatile__严禁将此处的汇编语句和其他语句进行重组优化,就是希望gcc不要修改我们这个部分。
- 寄存器使用%%开头
- 直接数使用$开头的十进制
- %0,%1,%2用来引用输出和输入的内容.
2. 约束符
约束符影响的内容包括
- whether an operand may be in a register
- which kinds of register
- whether the operand can be a memory reference
- which kinds of address
- whether the operand may be an immediate constant
- which possible values it may have
约束符包括[还有一些不是很理解]
- p 内存地址
- m 内存变量
- o 内存变量,但是寻址方式必须是偏移量的,就是基址寻址或者是基址变址寻址.
- V 内存变量,但是寻址方式是非偏移量的.
- r general寄存器操作数
- i 立即操作数,内容在编译器可以确定.
- n 立即操作数.有些系统不支持字(双字节)以外的立即操作数,这些操作数以n非i来表示.
- E/F 浮点常数
- g 内存操作数,整数常数,非genernal寄存器操作数
- X 任何操作数
- 0,1,2…9 和编号指定操作数匹配的操作数
这里在列举一下Intel386的约束符
- q 在i386下面对应a,b,c,d,在x86-64下面对应r
- Q 对应a,b,c,d
- R 在i386下面对应r
- A 对应a,d.这个对应%edx和%eax寄存器.可以保存64位内容.比如("rdstc":"=A"(ret)::);
- f 浮点寄存器
- t first浮点寄存器
- u second浮点寄存器
- a,b,c,d eax,ebx,ecx,edx
- C 可以直接载入SSE寄存器的常数
- D di
- S si
- x SSE寄存器xmm
- y MMX寄存器
- I [0,31]的常数,常用于32位的移位指令.
- J [0,63]的常数,常用于64位的移位指令.
- K 0xff
- L 0xffff
- M (0,1,2,3)
- N [0,255]的常数,常用于out指令.
- Z [0,0xfffffff]
- e [-2147483648,2147483647]
- G 80387浮点常数
3. 修饰符
修饰符包括[还有一些不是很理解]
- = 操作数是write only的
- + 操作数是可读可写的
- & 常用于输出限定符,表示某个寄存器不会被输入所使用.
__asm__ __volatile__ ("call func\n\tmovl %%ebx,%1","=a"(foo),"r"(bar));
我们本来想把func返回值给foo,保存在eax寄存器.但是因为bar分配到了eax寄存器, 所以foo最终是ebx寄存器结果.为了避免这个问题,我们可以使用&修饰符.
__asm__ __volatile__ ("call func\n\tmovl %%ebx,%1","=&a"(foo),"r"(bar));
4. 注意事项
4.1. 值类型
值的类型会影响寄存器的分配.比如这里"r"((long long)N).本来N是一个int类型的, 如果存放位置是r的话,那么gcc可能会分配%ebx,%ecx这样的32位寄存器, 而指令中我们使用的是"subq $4,%2"这样的指令,应该是一个64位寄存器. 强制转换的话可以告诉gcc我们这里分配的是64位寄存器而不是32位寄存器.
4.2. 跳转标签
对于跳转标签我们可以使用1,2,3来命名,然后在跳转的时候,需要在后面加上后缀. b表示backward,f表示foreward.比如jnz 1b.使用1,2,3来命名的标签都是局部标签.
4.3. 输入/输出使用同一个寄存器
如果想输入和输出使用同一个寄存器的话,存在两种方式.
__asm__ __volatile__ ("cpuid":"+r"(a)::) __asm__ __volatile__ ("cpuid":"=r"(a):"0"(a):)
第一种方式默认情况下面对于output operand处理我们只是认为在之前之前是dead的,只是 一个可写的状态.如果加上+修饰符的话,那么表示在指令之前不是dead状态并且是可读的. 第二种方式是同时告诉a是输入也是输出,但是两者使用同一个寄存器.
个人感觉还是第一种方式直观,变量只需要写一次.
4.4. 内存访问
如果在指令中存在某种不可以预见的访问内存方式的话,那么最好在clobber部分写上"memory". 不可预见的访问内存方式是相对于gcc来说的,如果我们指令里面某些操作如果会影响到外部内存 而这个内存实际上在其他地方被gcc认为是存放在寄存器的话,如果我们不告诉gcc我们可能会修改 这个部分内存的话,gcc在后面代码还会继续使用这个寄存器来代替这个内存访问导致错误.
使用"memory"作为clobber部分另外一个作用是可以让在这条指令之后的指令,告诉gcc应该刷新 内存状态.内存的状态可能发生修改,如果需要操作的话,需要重新把内存内容载入寄存器.比如
__asm__ __volatile__ ("":::"memory")
4.5. 指令顺序调整
即使对于一条__asm__指令的话,可能被调整执行顺序.如果希望不被调整执行顺序的话,那么应该把 这些指令放在一个asm指令内部.
4.6. 关于Condition Code
如果load和store会改写的Condition Code的话,那么在刚进入asm第一条指令以及刚出asm第一条指令 的时候,可能看到的不是一个正确的Condition Code.因为在进入asm之前需要load数据而在出asm之后 需要store数据,这个部分是不会被asm内部指令看见的,所有所见到的Condition Code可能不是 我们所希望的.如果会修改Condition Code的话,那么需要在clobber里面写上"cc".
4.7. 关于asm大小
asm大小是根据指令数量*最长指令来计算大小*的.所以如果内部使用macro来编写的话,可能会造成 asm大小计算错误,影响产生的代码.
5. 其他文章
5.1. gcc内嵌汇编码1
信件标题: [转贴]gcc内嵌汇编码
发 信 人: Yong_Q@bbs.ustc.edu.cn (小忍)
信 区: Linux视图M[997/7721]
原发信站: 中国科大BBS站(Wed, 27 Oct 1999 13:59:50)
======================================================================
发信人: rover (Eggplant), 信区: Lisoleg
标 题: gcc中的内嵌汇编语言(Intel i386平台)
发信站: 中国信息技术论坛──阿卡 (Sun Apr 4 19:53:36 1999), 转信
NOTE: 原文是我在老铁的网站上看到的,原文是灵溪所作。
我直接给贴过来了,我也不太懂,希望大家都来研究。
gcc中的内嵌汇编语言(Intel i386平台)
一.声明
虽然Linux的核心代码大部分是用C语言编写的,但是不可避免的其中
还是有一部分是用汇编语言写成的。有些汇编语言代码是直接写在汇
编源程序中的,特别是Linux的启动代码部分;还有一些则是利用gcc
的内嵌汇编语言嵌在C语言程序中的。这篇文章简单介绍了gcc中的内
嵌式汇编语言,主要想帮助那些才开始阅读Linux核心代码的朋友们
能够更快的入手。
写这篇文章的主要信息来源是GNU的两个info文件:as.info和
gcc.info,如果你觉得这篇文章中的介绍还不够详细的话,你可以查
阅这两个文件。当然,直接查阅这两个文件可以获得更加权威的信息。
如果你不想被这两篇文档中的一大堆信息搞迷糊的话,我建议你先阅
读一下这篇文章,然后在必要时再去查阅更权威的信息。
二.简介
在Linux的核心代码中,还是存在相当一部分的汇编语言代码。如果
你想顺利阅读Linux代码的话,你不可能绕过这一部分代码。在Linux
使用的汇编语言代码中,主要有两种格式:一种是直接写成汇编语言
源程序的形式,这一部分主要是一些Linux的启动代码;另一部分则
是利用gcc的内嵌式汇编语言语句asm嵌在Linux的C语言代码中的。这
篇文章主要是介绍第二种形式的汇编语言代码。
首先,我介绍一下as支持的汇编语言的语法格式。大家知道,我们现
在学习的汇编语言的格式主要是Intel风格的,而在Linux的核心代码
中使用的则是AT&T格式的汇编语言代码,应该说大部分人对这种格式
的汇编语言还不是很了解,所以我觉得有必要介绍一下。
接着,我主要介绍一下gcc的内嵌式汇编语言的格式。gcc的内嵌式汇
编语言提供了一种在C语言源程序中直接嵌入汇编指令的很好的办法,
既能够直接控制所形成的指令序列,又有着与C语言的良好接口,所
以在Linux代码中很多地方都使用了这一语句。
三.AT&T的汇编语言语法格式
我想我们大部分人对Intel格式的汇编语言都很了解了。但是,在
Linux核心代码中,所有的汇编语言指令都是用AT&T格式的汇编语
言书写的。这两种汇编语言在语法格式上有着很大的不同:
1.在AT&T的汇编语言中,用'$'前缀表示一个立即操作数;而在Intel
的格式中,立即操作数的表示不带任何前缀符。例如:下面两个语句
是完全相同的:
*AT&T: pushl $4
*Intel: push 4
2.AT&T和Intel的汇编语言格式中,源操作数和目标操作数的位置正
好相反。Intel的汇编语言中,目标操作数在源操作数的左边;而在
AT&T的汇编语言中,目标操作数则在源操作数的右边。例如:
*AT&T : addl $4,%eax
*Intel: add eax,4
3.在AT&T的汇编语言中,操作数的字长是由操作码助记符的最后一个
字母决定的,后缀'b'、'w'、'l'分别表示操作数的字长为8比特(字
节,byte),16比特(字,word)和32比特(长字,long),而
Intel格式中操作数的字长是用“word ptr”或者“byte ptr”等前
缀来表示的。例如:
*AT&T: movb FOO,%al
*Intel: mov al,byte ptr FOO
4.在AT&T汇编指令中,直接远跳转/调用的指令格式是“lcall/ljmp
$SECTION,$OFFSET”,同样,远程返回的指令是“lret
$STACK-ADJUST”;而在Intel格式中,相应的指令分别为“call/jmp
far SECTION:OFFSET”和“ret far STACK-ADJUST”。
①AT&T汇编指令操作助记符命名规则
①AT&T汇编指令操作助记符命名规则
AT&T汇编语言中,操作码助记符的后缀字符指定了该指令中操作数的
字长。后缀字母'b'、'w'、'l'分别表示字长为8比特(字节,byte),
16比特(字,word)和32比特(长字,long)的操作数。如果助记符
中没有指定字长后缀并且该指令中没有内存操作数,汇编程序'as'会
根据指令中指定的寄存器操作数补上相应的后缀字符。所以,下面的
两个指令具有相同的效果(这只是GNU的汇编程序as的一个特性,AT&T
的Unix汇编程序将没有字长后缀的指令的操作数字长假设为32比特):
mov %ax,%bx
movw %ax,%bx
AT&T中几乎所有的操作助记符与Intel格式中的助记符同名,仅有一
小部分例外。操作数扩展指令就是例外之一。在AT&T汇编指令中,操
作数扩展指令有两个后缀:一个指定源操作数的字长,另一个指定目
标操作数的字长。AT&T的符号扩展指令的基本助记符为'movs',零扩
展指令的基本助记符为'movz'(相应的Intel指令为'movsx'和
'movzx')。因此,'movsbl %al,%edx'表示对寄存器al中的字节数据
进行字节到长字的符号扩展,计算结果存放在寄存器edx中。下面是一
些允许的操作数扩展后缀:
*bl: 字节->长字
*bw: 字节->字
*wl: 字->长字
还有一些其他的类型转换指令的对应关系:
*Intel *AT&T
⑴ cbw cbtw
符号扩展:al->ax
⑵ cwde cwtl
符号扩展:ax->eax
⑶ cwd cwtd
符号扩展:ax->dx:ax
⑷ cdq cltd
符号扩展:eax->edx:eax
还有一个不同名的助记符就是远程跳转/调用指令。在Intel格式中,
还有一个不同名的助记符就是远程跳转/调用指令。在Intel格式中,
远程跳转/调用指令的助记符为“call/jmp far”,而在AT&T的汇编
语言中,相应的指令为“lcall”和“ljmp”。
②AT&T中寄存器的命名
在AT&T汇编语言中,寄存器操作数总是以'%'作为前缀。80386芯片的
寄存器包括:
⑴8个32位寄存器:'%eax','%ebx','%ecx','%edx','%edi','%esi',
'%ebp','%esp'
⑵8个16位寄存器:'%ax','%bx','%cx','%dx','%si','%di','%bp',
'%sp'
⑶8个8位寄存器:'%ah','%al','%bh','%bl','%ch','%cl','%dh',
'%dl'
⑷6个段寄存器:'%cs','%ds','%es','%ss','%fs','%gs'
⑸3个控制寄存器:'%cr0','%cr1','%cr2'
⑹6个调试寄存器:'%db0','%db1','%db2','%db3','%db6','%db7'
⑺2个测试寄存器:'%tr6','%tr7'
⑻8个浮点寄存器栈:'%st(0)','%st(1)','%st(2)','%st(3)',
'%st(4)','%st(5)','%st(6)','%st(7)'
*注:我对这些寄存器并不是都了解,这些资料只是摘自as.info文档。
如果真的需要寄存器命名的资料,我想可以参考一下相应GNU工具的机
器描述方面的源文件。
③AT&T中的操作码前缀
⑴段超越前缀'cs','ds','es','ss','fs','gs':当汇编程序中对内
存操作数进行SECTION:MEMORY-OPERAND引用时,自动加上相应的段超
越前缀。
⑵操作数/地址尺寸前缀'data16','addr16':这些前缀将32位的操作
数/地址转化为16位的操作数/地址。
⑶总线锁定前缀'lock':总线锁定操作。'lock'前缀在Linux核心代码
中使用很多,特别是SMP代码中。
⑷协处理器等待前缀'wait':等待协处理器完成当前操作。
⑸指令重复前缀'rep','repe','repne':在串操作中重复指令的执行。
④AT&T中的内存操作数
在Intel的汇编语言中,内存操作数引用的格式如下:
在Intel的汇编语言中,内存操作数引用的格式如下:
SECTION:[BASE + INDEX*SCALE + DISP]
而在AT&T的汇编语言中,内存操作数的应用格式则是这样的:
SECTION:DISP(BASE,INDEX,SCALE)
下面是一些内存操作数的例子:
*AT&T *Intel
⑴ -4(%ebp) [ebp-4]
⑵ foo(,%eax,4) [foo+eax*4]
⑶ foo(,1) [foo]
⑷ %gs:foo gs:foo
还有,绝对跳转/调用指令中的内存操作数必须以'*'最为前缀,否则
as总是假设这是一个相对跳转/调用指令。
⑤AT&T中的跳转指令
as汇编程序自动对跳转指令进行优化,总是使用尽可能小的跳转偏移
量。如果8比特的偏移量无法满足要求的话,as会使用一个32位的偏
移量,as汇编程序暂时还不支持16位的跳转偏移量,所以对跳转指令
使用'addr16'前缀是无效的。
还有一些跳转指令只支持8位的跳转偏移量,这些指令包括:'jcxz',
'jecxz','loop','loopz','loope','loopnz'和'loopne'。所以,
在as的汇编源程序中使用这些指令可能会出错。(幸运的是,gcc并
不使用这些指令)
对AT&T汇编语言语法的简单介绍差不多了,其中有些特性是as特有的。
在Linux核心代码中,并不涉及到所有上面这些提到的语法规则,其
中有两点规则特别重要:第一,as中对寄存器引用时使用前缀'%';第
二,AT&T汇编语言中源操作数和目标操作数的位置与我们熟悉的Intel
的语法正好相反。
四.gcc的内嵌汇编语言语句asm
利用gcc的asm语句,你可以在C语言代码中直接嵌入汇编语言指令,
利用gcc的asm语句,你可以在C语言代码中直接嵌入汇编语言指令,
同时还可以使用C语言的表达式指定汇编指令所用到的操作数。这一
特性提供了很大的方便。
要使用这一特性,首先要写一个汇编指令的模板(这种模板有点类似
于机器描述文件中的指令模板),然后要为每一个操作数指定一个限
定字符串。例如:
extern __inline__ void change_bit(int nr,volatile void *addr)
{
__asm__ __volatile__( LOCK_PREFIX
"btcl %1,%0"
:"=m" (ADDR)
:"ir" (nr));
}
上面的函数中:
LOCK_PREFIX:这是一个宏,如果定义了__SMP__,扩展为"lock;",
用于指定总线锁定前缀,否则扩展为""。
ADDR:这也是一个宏,定义为(*(volatile struct __dummy *) addr)
"btcl %1,%0":这就是嵌入的汇编语言指令,btcl为指令操作码,%1,
%0是这条指令两个操作数的占位符。后面的两个限定字符串就用于描
述这两个操作数。
: "=m" (ADDR):第一个冒号后的限定字符串用于描述指令中的“输
出”操作数。刮号中的ADDR将操作数与C语言的变量联系起来。这个
限定字符串表示指令中的“%0”就是addr指针指向的内存操作数。这
是一个“输出”类型的内存操作数。
: "ir" (nr):第二个冒号后的限定字符串用于描述指令中的“输入”
操作数。这条限定字符串表示指令中的“%1”就是变量nr,这个的操
作数可以是一个立即操作数或者是一个寄存器操作数。
作数可以是一个立即操作数或者是一个寄存器操作数。
*注:限定字符串与操作数占位符之间的对应关系是这样的:在所有
限定字符串中(包括第一个冒号后的以及第二个冒号后的所有限定字
符串),最先出现的字符串用于描述操作数“%0”,第二个出现的字
符串描述操作数“%1”,以此类推。
①汇编指令模板
asm语句中的汇编指令模板主要由汇编指令序列和限定字符串组成。
在一个asm语句中可以包括多条汇编指令。汇编指令序列中使用操作
数占位符引用C语言中的变量。一条asm语句中最多可以包含十个操
作数占位符:%0,%1,...,%9。汇编指令序列后面是操作数限定字
符串,对指令序列中的占位符进行限定。限定的内容包括:该占位符
与哪个C语言变量对应,可以是什么类型的操作数等等。限定字符串
可以分为三个部分:输出操作数限定字符串(指令序列后第一个冒号
后的限定字符串),输入操作数限定字符串(第一个冒号与第二个冒
号之间),还有第三种类型的限定字符串在第二个冒号之后。同一种
类型的限定字符串之间用逗号间隔。asm语句中出现的第一个限定字
符串用于描述占位符“%0”,第二个用于描述占位符“%1”,以此类
推(不管该限定字符串的类型)。如果指令序列中没有任何输出操作
数,那么在语句中出现的第一个限定字符串(该字符串用于描述输入
操作数)之前应该有两个冒号(这样,编译器就知道指令中没有输出
操作数)。
指令中的输出操作数对应的C语言变量应该具有左值类型,当然对于
输出操作数没有这种左值限制。
输出操作数必须是只写的,也就是说,asm对取出某个操作数,执行
一定计算以后再将结果存回该操作数这种类型的汇编指令的支持不是
直接的,而必须通过特定的格式的说明。如果汇编指令中包含了一个
输入-输出类型的操作数,那么在模板中必须用两个占位符对该操作
数的不同功能进行引用:一个负责输入,另一个负责输出。例如:
asm ("addl %2,%0":"=r"(foo):"0"(foo),"g"(bar));
在上面这条指令中,“%0”是一个输入-输出类型的操作数,"=r"(foo)
用于限定其输出功能,该指令的输出结果会存放到C语言变量foo中;
指令中没有显式的出现“%1”操作数,但是针对它有一个限定字符串
指令中没有显式的出现“%1”操作数,但是针对它有一个限定字符串
"0"(foo),事实上指令中隐式的“%1”操作数用于描述“%0”操作数
的输入功能,它的限定字符串中的"0"限定了“%1”操作数与“%0”
具有相同的地址。可以这样理解上述指令中的模板:该指令将“%1”
和“%2”中的值相加,计算结果存放回“%0”中,指令中的“%1”与
“%0”具有相同的地址。注意,用于描述“%1”的"0"限定字符足以
保证“%1”与“%0”具有相同的地址。但是,如果用下面的指令完成
这种输入-输出操作就不会正常工作:
asm ("addl %2,%0":"=r"(foo):"r"(foo),"g"(bar));
虽然该指令中“%0”和“%1”同样引用了C语言变量foo,但是gcc并
不保证在生成的汇编程序中它们具有相同的地址。
还有一些汇编指令可能会改变某些寄存器的值,相应的汇编指令模板
中必须将这种情况通知编译器。所以在模板中还有第三种类型的限定
字符串,它们跟在输入操作数限定字符串的后面,之间用冒号间隔。
这些字符串是某些寄存器的名称,代表该指令会改变这些寄存器中的
内容。
在内嵌的汇编指令中可能会直接引用某些硬件寄存器,我们已经知道
AT&T格式的汇编语言中,寄存器名以“%”作为前缀,为了在生成的
汇编程序中保留这个“%”号,在asm语句中对硬件寄存器的引用必须
用“%%”作为寄存器名称的前缀。如果汇编指令改变了硬件寄存器的
内容,不要忘记通知编译器(在第三种类型的限定串中添加相应的字
符串)。还有一些指令可能会改变CPU标志寄存器EFLAG的内容,那么
需要在第三种类型的限定字符串中加入"cc"。
为了防止gcc在优化过程中对asm中的汇编指令进行改变,可以在"asm"
关键字后加上"volatile"修饰符。
可以在一条asm语句中描述多条汇编语言指令;各条汇编指令之间用
“;”或者“\n”隔开。
②操作数限定字符
操作数限定字符串中利用规定的限定字符来描述相应的操作数,一些
常用的限定字符有:(还有一些没有涉及的限定字符,参见gcc.info)
1。"m":操作数是内存变量。
2。"o":操作数是内存变量,但它的寻址方式必须是“偏移量”类型的,
也就是基址寻址或者基址加变址寻址。
3。"V":操作数是内存变量,其寻址方式非“偏移量”类型。
4。" ":操作数是内存变量,其地址自动增量。
6。"r":操作数是通用寄存器。
7。"i":操作数是立即操作数。(其值可在汇编时确定)
8。"n":操作数是立即操作数。有些系统不支持除字(双字节)以外的
立即操作数,这些操作数要用"n"而不是"i"来描述。
9。"g":操作数可以是立即数,内存变量或者寄存器,只要寄存器属
于通用寄存器。
10。"X":操作数允许是任何类型。
11。"0","1",...,"9":操作数与某个指定的操作数匹配。也就是说,
该操作数就是指定的那个操作数。例如,如果用"0"来描述"%1"操作
数,那么"%1"引用的其实就是"%0"操作数。
12。"p":操作数是一个合法的内存地址(指针)。
13。"=":操作数在指令中是只写的(输出操作数)。
14。"+":操作数在指令中是读-写类型的(输入-输出操作数)。
15。"a":寄存器EAX。
16。"b":寄存器EBX。
17。"c":寄存器ECX。
17。"c":寄存器ECX。
18。"d":寄存器EDX。
19。"q":寄存器"a","b","c"或者"d"。
20。"A":寄存器"a"或者"d"。
21。"a":寄存器EAX。
22。"f":浮点数寄存器。
23。"t":第一个浮点数寄存器。
24。"u":第二个浮点数寄存器。
25。"D":寄存器di。
26。"S":寄存器si。
27。"I":0-31之间的立即数。(用于32位的移位指令)
28。"J":0-63之间的立即数。(用于64位的移位指令)
29。"N":0-255之间的立即数。(用于"out"指令)
30。"G":标准的80387浮点常数。
*注:还有一些不常见的限定字符并没有在此说明,另外有一些限定
字符,例如"%","&"等由于我缺乏编译器方面的一些知识,所以我也
不是很理解它们的含义,如果有高手愿意补充,不慎感激!不过在
核心代码中出现的限定字符差不多就是上面这些了。
--ober 1999.3.31
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
5.2. gcc内嵌汇编码2
信件标题: [Forward]对 《gcc中的内嵌汇编语言》一文的补充说明
发 信 人: Yong_Q@bbs.ustc.edu.cn (小忍)
信 区: Linux视图M[998/7721]
原发信站: 中国科大BBS站(Wed, 27 Oct 1999 19:21:18)
======================================================================
对 《gcc中的内嵌汇编语言》一文的补充说明
欧阳光 ouyangguang@263.net 1999.10.13
初次接触到AT&T格式的汇编代码,看着那一堆莫名其妙的怪符号,真是有点痛不
欲生的感觉,只好慢慢地去啃gcc文档,在似懂非懂的状态下过了一段时间。后来又
在网上找到了灵溪写的《gcc中的内嵌汇编语言》一文,读后自感大有裨益。几个
月下来,接触的源代码多了以后,慢慢有了一些经验。为了使初次接触AT&T格式的
汇编代码的同志不至于遭受我这样的痛苦,就整理出该文来和大家共享.如有错误
之处,欢迎大家指正,共同提高.
本文主要以举例的方式对gcc中的内嵌汇编语言进行进一步的解释。
一、gcc对内嵌汇编语言的处理方式
gcc在编译内嵌汇编语言时,采取的步骤如下
1. 变量输入: 根据限定符的内容将输入操作数放入合适的寄存器,如果限定符
指定为立即数("i")或内存变量("m"),则该步被省略,如果限定符没有具体指
定输入操作数的类型(如常用的"g"),gcc会视需要决定是否将该操作数输入到
某个寄存器.这样每个占位符都与某个寄存器,内存变量,或立即数形成了一一
对应的关系.这就是对第二个冒号后内容的解释.
如::"a"(foo),"i"(100),"m"(bar)表示%0对应eax寄存器,%1对应100,%2对应
内存变量bar.
2. 生成代码: 然后根据这种一一对应的关系(还应包括输出操作符),用这些寄
存器,内存变量,或立即数来取代汇编代码中的占位符(则有点像宏操作),注
意,则一步骤并不检查由这种取代操作所生成的汇编代码是否合法,例如,如果
有这样一条指令asm("movl %0,%1"::"m"(foo),"m"(bar));如果你用gcc -c
-S选项编译该源文件,那么在生成的汇编文件中,你将会看到生成了movl
foo,bar这样一条指令,这显然是错误的.这个错误在稍后的编译检查中会被发
现.
3. 变量输出: 按照输出限定符的指定将寄存器的内容输出到某个内存变量
中,如果输出操作数的限定符指定为内存变量("m"),则该步骤被省略.这就是
对第一个冒号后内容的解释,如:asm("mov %0,%1":"=m"(foo),"=a"(bar):);
编译后为
#APP
movl foo,eax
#NO_APP
movl eax,bar
该语句虽然有点怪怪的,但它很好的体现了gcc的运作方式.
再以arch/i386/kernel/apm.c中的一段代码为例,我们来比较一下它们编译前后
的情况
源程序
编译后的汇编代码
__asm__ (
"pushl %%edi\n\t"
"pushl %%ebp\n\t"
"lcall %%cs:\n\t"
"setc %%al\n\t"
"addl %1,%2\n\t"
"popl %%ebp\n\t"
"popl %%edi\n\t"
:"=a"(ea),"=b"(eb),
"=c"(ec),"=d"(ed),"=S"(es)
:"a"(eax_in),"b"(ebx_in),"c"(ecx_in)
:"memory","cc");
movl eax_in,%eax
movl ebx_in,%ebx
movl ecx_in,%ecx
#APP
pushl %edi
pushl %ebp
lcall %cs:
setc %al
addl eb,ec
popl %ebp
popl %edi
#NO_APP
movl %eax,ea
movl %ebx,eb
movl %ecx,ec
movl %edx,ed
movl %esi,es
二.对第三个冒号后面内容的解释
第三个冒号后面内容主要针对gcc优化处理,它告诉gcc在本段汇编代码中对寄
存器和内存的使用情况,以免gcc在优化处理时产生错误.
1. 它可以是"eax","ebx","ecx"等寄存器名,表示本段汇编代码对该寄存器进行
了显式操作,如 asm ("mov %%eax,%0",:"=r"(foo)::"eax");这样gcc在优化
时会避免使用eax作临时变量,或者避免cache到eax的内存变量通过该段汇编
码.
下面的代码均用gcc的-O2级优化,它显示了嵌入汇编中第三个冒号后"eax"的
作用
源程序 编译后的汇编代码
正常情况下 int main()
{int bar=1;
bar=fun();
bar++;
return bar;
} pushl %ebp
movl %esp,%ebp
call fun
incl %eax #显然,bar缺省使用eax寄存器
leave
ret
加了汇编后 int main()
{int bar=1;
bar=fun();
asm volatile("" : : : "eax");
bar++;
return bar;
} pushl %ebp
movl %esp,%ebp #建立堆栈框架
call fun
#fun的返回值放入bar中,此时由于嵌入汇编
#指明改变了eax的值,为了避免冲突,
#bar改为使用edx寄存器
movl %eax,%edx
#APP
#NO_APP
incl %edx
movl %edx,%eax #放入main()的返回值
leave
ret
2. "merory"是一个常用的限定,它表示汇编代码以不可预知的方式改变了内存,
这样gcc在优化时就不会让cache到寄存器的内存变量使用该寄存器通过汇编
代码,否则可能会发生同步出错.有了上面的例子,这个问题就很好理解了
三.对"&"限定符的解释
这是一个较常见用于输出的限定符.它告诉gcc输出操作数使用的寄存器不可再
让输入操作数使用.
对于"g","r"等限定符,为了有效利用为数不多的几个通用寄存器,gcc一般会让
输入操作数和输出操作数选用同一个寄存器.但如果代码没编好,会引起一些意想
不到的错误:如 asm("call fun;mov ebx,%1":"=a"(foo):"r"(bar));gcc编译的结
果是foo和bar同时使用eax寄存器:
movl bar,eax
#APP
call fun
movl ebx,eax
#NO_APP
movl eax,foo
本来这段代码的意图是将fun()函数的返回值放入foo变量,但半路杀出个程咬金,
用ebx的值冲掉了返回值,所以这是一段错误的代码,解决的方法是加上一个给输出
操作数加上一个"&"限定符:asm("call fun;mov
ebx,%1":"=&a"(foo):"r"(bar));这样gcc就会让输入操作数另寻高就,不再使
用eax寄存器了
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
5.3. 关于gcc的行内汇编(1)
信件标题: :关于gcc的行内汇编(1)
发 信 人: Roy_G@bbs.ustc.edu.cn (想去西藏的小巴郎)
信 区: Linux视图M[699/7721]
原发信站: 中国科大BBS站(Fri, 20 Nov 1998 21:35:00)
======================================================================
我的资料也是在网上取来的,但是站点忘记了,有兴趣的可以
在khg上查查.
gcc采用的是AT&T的汇编格式,MS采用Intel的格式.
一 基本语法
语法上主要有以下几个不同.
★ 寄存器命名原则
AT&T: %eax Intel: eax
★源/目的操作数顺序
AT&T: movl %eax,%ebx Intel: mov ebx,eax
★常数/立即数的格式
AT&T: movl $_value,%ebx Intel: mov eax,_value
把_value的地址放入eax寄存器
AT&T: movl $0xd00d,%ebx Intel: mov ebx,0xd00d
★ 操作数长度标识
AT&T: movw %ax,%bx Intel: mov bx,ax
★寻址方式
AT&T: immed32(basepointer,indexpointer,indexscale)
Intel: [basepointer + indexpointer*indexscale + imm32)
Linux工作于保护模式下,用的是32位线性地址,所以在计算地址时
不用考虑segment:offset的问题.上式中的地址应为:
imm32 + basepointer + indexpointer*indexscale
下面是一些例子:
★直接寻址
AT&T: _booga ; _booga是一个全局的C变量
注意加上$是表示地址引用,不加是表示值引用.
注:对于局部变量,可以通过堆栈指针引用.
Intel: [_booga]
★寄存器间接寻址
AT&T: (%eax)
Intel: [eax]
★变址寻址
AT&T: _variable(%eax)
Intel: [eax + _variable]
AT&T: _array(,%eax,4)
Intel: [eax*4 + _array]
AT&T: _array(%ebx,%eax,8)
Intel: [ebx + eax*8 + _array]
(待续)
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
5.4. 关于gcc的行内汇编(2)
信件标题: 关于gcc的行内汇编(2)
发 信 人: Roy_G@bbs.ustc.edu.cn (想去西藏的小巴郎)
信 区: Linux视图M[700/7721]
原发信站: 中国科大BBS站(Fri, 20 Nov 1998 21:35:34)
======================================================================
二 基本的行内汇编
基本的行内汇编很简单,一般是按照下面的格式
asm("statements");
例如:asm("nop"); asm("cli");
asm 和 __asm__是完全一样的.
如果有多行汇编,则每一行都要加上 "\n\t"
例如:
asm( "pushl %eax\n\t"
"movl $0,%eax\n\t"
"popl %eax");
实际上gcc在处理汇编时,是要把asm(...)的内容"打印"到汇编
文件中,所以格式控制字符是必要的.
再例如:
asm("movl %eax,%ebx");
asm("xorl %ebx,%edx");
asm("movl $0,_booga);
在上面的例子中,由于我们在行内汇编中改变了edx和ebx的值,但是
由于gcc的特殊的处理方法,即先形成汇编文件,再交给GAS去汇编,
所以GAS并不知道我们已经改变了edx和ebx的值,如果程序的上下文
需要edx或ebx作暂存,这样就会引起严重的后果.对于变量_booga也
存在一样的问题.为了解决这个问题,就要用到扩展的行内汇编语法.
(待续)
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
5.5. 关于gcc的行内汇编(3)
信件标题: 关于gcc的行内汇编(3)
发 信 人: Roy_G@bbs.ustc.edu.cn (想去西藏的小巴郎)
信 区: Linux视图M[701/7721]
原发信站: 中国科大BBS站(Fri, 20 Nov 1998 21:35:48)
======================================================================
三 扩展的行内汇编
扩展的行内汇编类似于Watcom.
基本的格式是:
asm ( "statements" : output_regs : input_regs : clobbered_regs);
clobbered_regs指的是被改变的寄存器.
下面是一个例子(为方便起见,我使用全局变量):
int count=1;
int value=1;
int buf[10];
void main()
{
asm(
"cld \n\t"
"rep \n\t"
"stosl"
:
: "c" (count), "a" (value) , "D" (buf[0])
: "%ecx","%edi" );
}
得到的主要汇编代码为:
movl count,%ecx
movl value,%eax
movl buf,%edi
#APP
cld
rep
stosl
#NO_APP
cld,rep,stos就不用多解释了.
这几条语句的功能是向buf中写上count个value值.
冒号后的语句指明输入,输出和被改变的寄存器.
通过冒号以后的语句,编译器就知道你的指令需要和改变哪些寄存器,
从而可以优化寄存器的分配.
其中符号"c"(count)指示要把count的值放入ecx寄存器
类似的还有:
a eax
b ebx
c ecx
d edx
S esi
D edi
I 常数值,(0 - 31)
q,r 动态分配的寄存器
g eax,ebx,ecx,edx或内存变量
A 把eax和edx合成一个64位的寄存器(use long longs)
我们也可以让gcc自己选择合适的寄存器.
如下面的例子:
asm("leal (%1,%1,4),%0"
: "=r" (x)
: "0" (x) );
这段代码实现5*x的快速乘法.
得到的主要汇编代码为:
movl x,%eax
#APP
leal (%eax,%eax,4),%eax
#NO_APP
movl %eax,x
几点说明:
1.使用q指示编译器从eax,ebx,ecx,edx分配寄存器.
使用r指示编译器从eax,ebx,ecx,edx,esi,edi分配寄存器.
2.我们不必把编译器分配的寄存器放入改变的寄存器列表,因为寄存器
已经记住了它们.
3."="是标示输出寄存器,必须这样用.
4.数字%n的用法:
数字表示的寄存器是按照出现和从左到右的顺序映射到用"r"或"q"请求
的寄存器.如果我们要重用"r"或"q"请求的寄存器的话,就可以使用它们.
5.如果强制使用固定的寄存器的话,如不用%1,而用ebx,则
asm("leal (%%ebx,%%ebx,4),%0"
: "=r" (x)
: "0" (x) );
注意要使用两个%,因为一个%的语法已经被%n用掉了.
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
5.6. 关于gcc的行内汇编(4)
信件标题: 关于gcc的行内汇编(4)
发 信 人: Roy_G@bbs.ustc.edu.cn (想去西藏的小巴郎)
信 区: Linux视图M[702/7721]
原发信站: 中国科大BBS站(Fri, 20 Nov 1998 21:36:07)
======================================================================
下面可以来解释letter 4854-4855的问题:
1、变量加下划线和双下划线有什么特殊含义吗?
加下划线是指全局变量,但我的gcc中加不加都无所谓.
2、以上定义用如下调用时展开会是什么意思?
#define _syscall1(type,name,type1,arg1) \
type name(type1 arg1) \
{ \
long __res; \
/* __res应该是一个全局变量 */
__asm__ volatile ("int $0x80" \
/* volatile 的意思是不允许优化,使编译器严格按照你的汇编代码汇编*/
: "=a" (__res) \
/* 产生代码 movl %eax, __res */
: "0" (__NR_##name),"b" ((long)(arg1))); \
/* 如果我没记错的话,这里##指的是两次宏展开.
即用实际的系统调用名字代替"name",然后再把__NR_...展开.
接着把展开的常数放入eax,把arg1放入ebx */
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
--
※ 来源: 中国科大BBS站 [bbs.ustc.edu.cn]
6. 函数调用约定
有三种我们熟知的函数调用顺序,假设我们调用函数 `fx(a, b, c)` 的话
- cdecl压栈的顺序是从右向左: push c, push b, push a.
- stdcall压栈的顺序是从左向右: push a, push b, push c.
- fastcall尽可能地将更多的参数通过寄存器而不是栈来进行传递。
其中cdecl这种调用约定比较适合类似 `printf` 这样的函数,因为通过很容易计算出每个参数相对于ebp的偏移。
在函数调用的时候,某些寄存器需要调用方保存下来(caller-save),某些寄存器需要被调用方保存下来(callee-save). 在不同体系结构和操作系统上,这种寄存器保存约定是不同的。但是大体设计思路应该是:
- 如果某个寄存器经常被修,改用于计算的话比如%eax, 那么这类寄存器就是called-save.
- 如果某个寄存器不经常被修改比如%ebp,如果你想使用的话那么就需要自己save,那么这类寄存器就是callee-save.
假设我们有下面这样一个程序调用
int f(int x, int y) { return x + y; } int main() { int i = 77; i = f(i, 8); i = i % 5; return i; }
在调用函数f的时候(使用cdecl call convention),我们同时执行下面这些指令为执行f做准备(prologue):
pushl %ebp movl %esp %ebp # 调整基址 %subs $8 %esp # 开辟f内部空间
假设我们不考虑优化,那么栈的情况可能回事这样的:可以看到我们可以使用8(%ebp)来引用变量i, 12(%ebp)来引用常数8. 当然这些都是没有经过寄存器优化的,否则这些传值可能是会放在寄存器里面的。
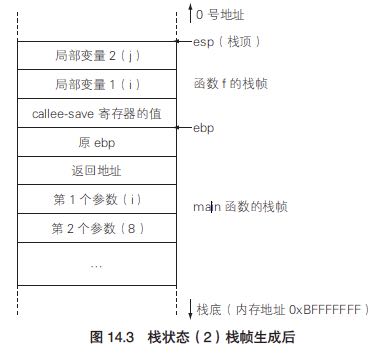
当我们执行完成f之后我们还需要执行一些指令来清空状态(epilogue):
movl %ebp %esp popl %ebp ret
通常我们使用%eax存储返回值,但是有这么几类特殊情况:
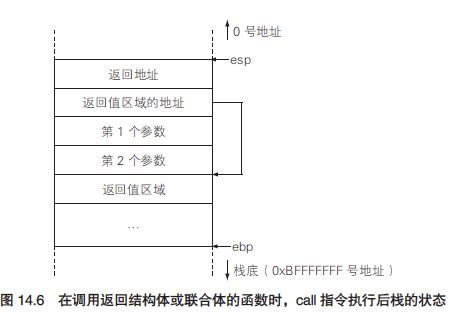
- 返回long long的64位类型,那么可以使用%edx(hi-32)和%eax(lo-32)联合返回
- 返回浮点数的话,那么可以使用浮点寄存器st(0)返回
- 如果返回struct/union比较大的数据的话,那么需要caller单独为这个数据结构在栈上分配返回空间。