Frangipani: A Scalable Distributed File System
https://pdos.csail.mit.edu/6.824/papers/thekkath-frangipani.pdf
https://pdos.csail.mit.edu/6.824/notes/l-frangipani.txt
这里我简称FP,FP其实是运行在叫做Petal的分布式存储服务上的,然后配合petal lock service,实现出POSIX语义的文件系统。
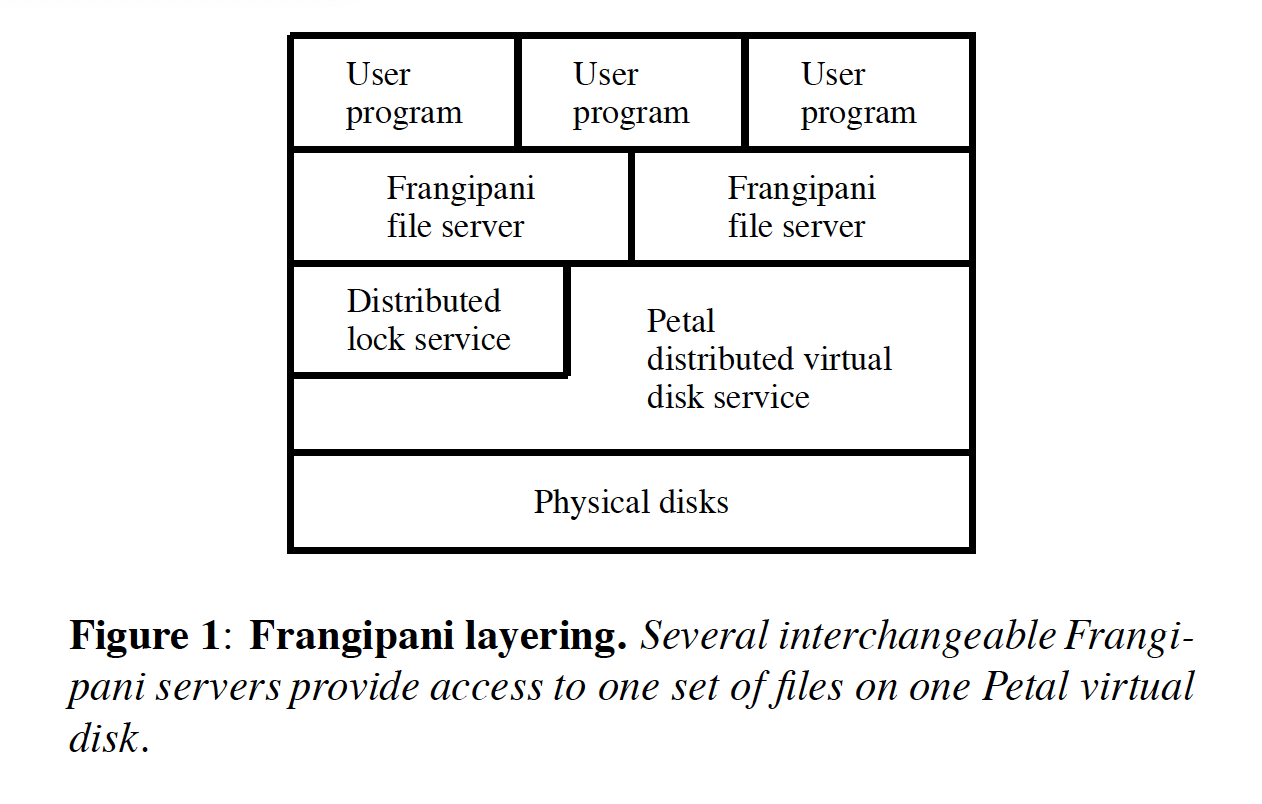
层次结构如下图。这里提到的FP其实就是图片里面的fragnipani server. Distributed lock service是做在petal里面的,用Paxos来做共识算法。
另外文章里面有图说明在实际情况中是如何部署的. Petal服务是单独部署的。在用户机器上部署了:
- file system switch FP文件系统的设备驱动
- FP file server module. 每个server之间其实是通过petal lock service来做协调的
- petal device driver. petal服务的设备驱动.
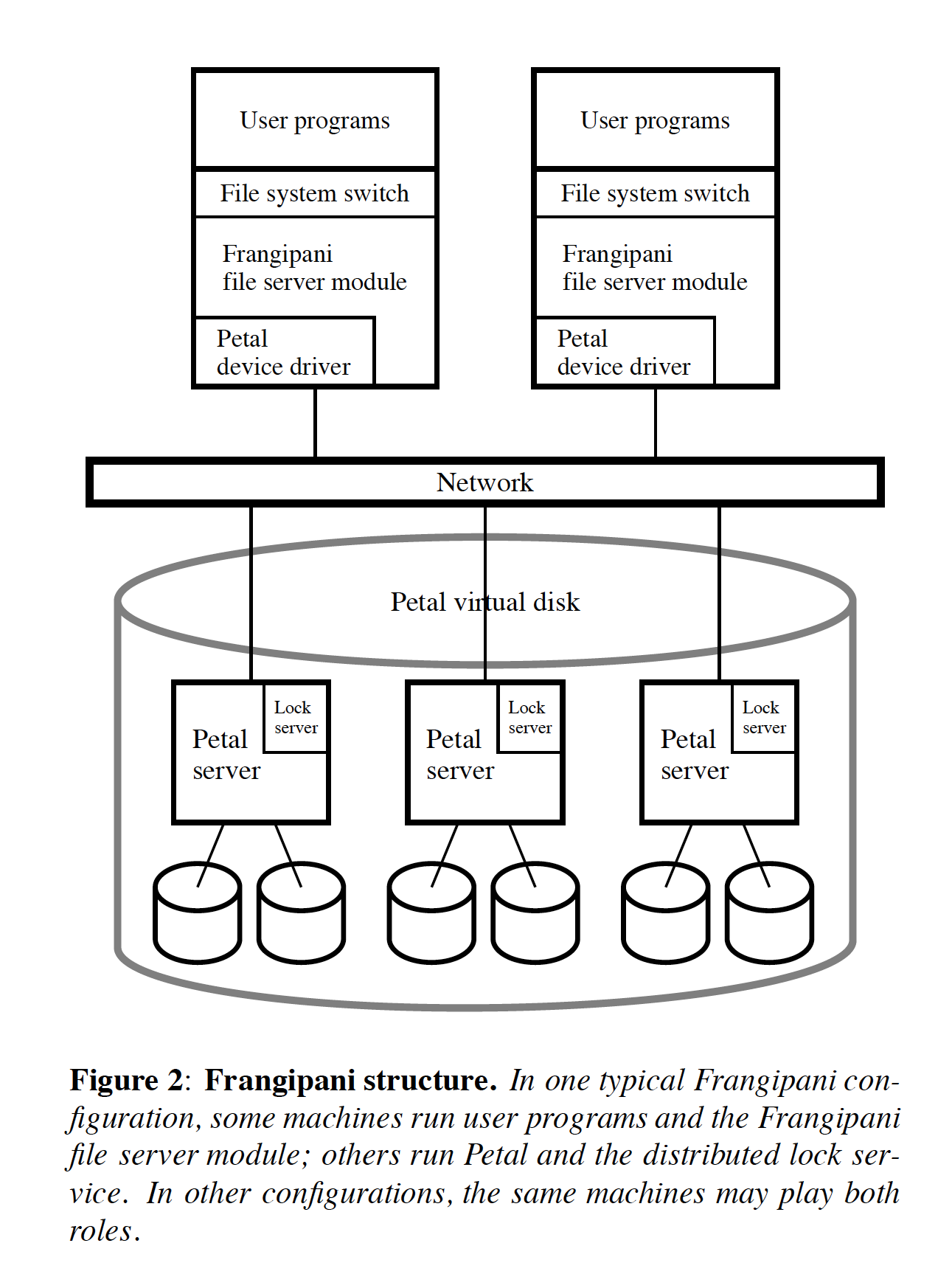
Petal提供的是虚拟磁盘服务,具体来说就是2^64字节大小的存储空间。FP要做的事情就是两件:1. 在这个存储空间上做个文件系统(file, directory, permission etc.) 2. 以及利用petal lock service做好并发控制
FP在写入user data的时候也是先写入到kernel buffer pool里面去,然后定时或者是被fsync/sync这样的调用刷到petal磁盘上去。 在写入meta data的时候则要先把log写到petal上,如果这个时候FP挂了的话则需要回放log. 如果检测到FP server挂掉的话, 会有 "recovery demon" 启动把这个server的log做个回放,文章也没有给这个demon太多的细节。
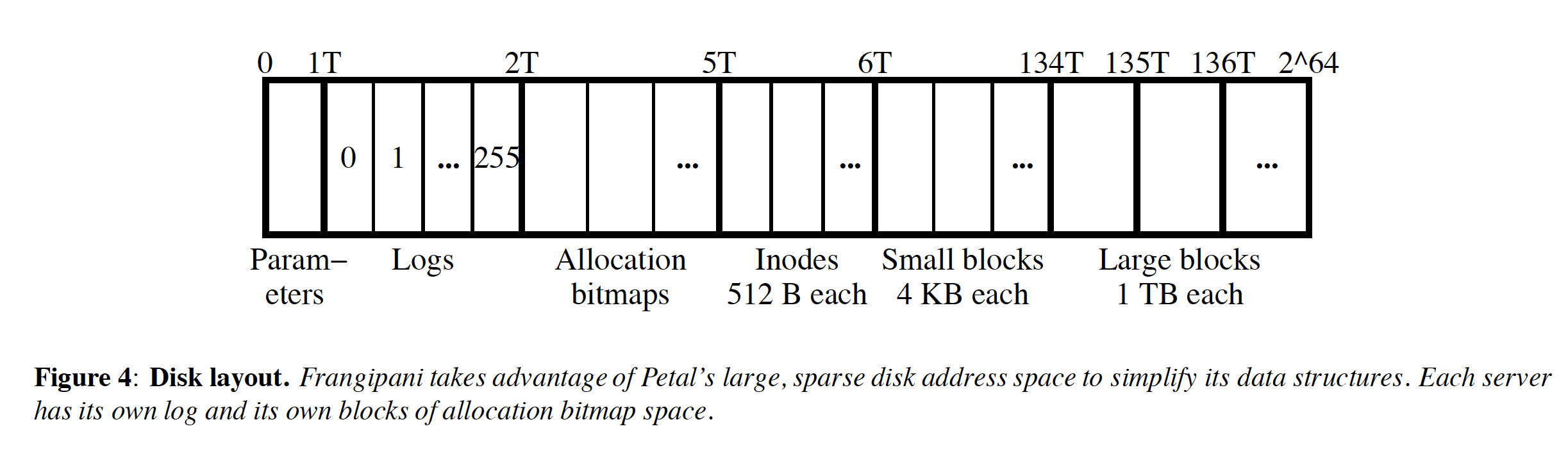
支持的最大文件是1TB + 64KB. 在上面的disk layout上可以看到,专门为每个server提供了独立的log空间,最多支持256 servers.
文章里面提到"We have made inodes 512 bytes long, the size of a disk block, thereby avoiding the unnecessary contention (“false sharing”) between servers that would occur if two servers needed to access different inodes in the same block.". 所以我理解512 bytes dist block是petal管理的最小单位,所以inode肯定只由一个petal server管理,所以只需要请求一个petal server的锁就行。
FP解决并发控制的方法就是读写锁,这里需要注意的地方就是这是隐式锁(implicit lock),要避免false sharing的问题。和上面inode大小设计道理一样,如果某个数据结构被两个lock都管理的话,那么就会出现deadlock. 另外一个出现deadlock的可能原因是申请lock的顺序不同。关于这两个问题,文章里面都有提到解决办法。
We have divided the ondisk structures into logical segments with locks for each segment. To avoid false sharing, we ensure that a single disk sector does not hold more than one data structure that could be shared. Our division of ondisk data structures into lockable segments is designed to keep the number of locks reasonably small, yet avoid lock contention in the common case, so that the lock service is not a bottleneck in the system.
Each log is a single lockable segment, because logs are private. The bitmap space is also divided into segments that are locked exclusively, so that there is no contention when new files are allocated. A data block or inode that is not currently allocated to a file is protected by the lock on the segment of the allocation bitmap that holds the bit marking it as free. Finally, each file, directory, or symbolic link is one segment; that is, one lock protects both the inode and any file data it points to. This perfile lock granularity is appropriate for engineering workloads where files rarely undergo concurrent writesharing. Other workloads, however, may require finer granularity locking.
Some operations require atomically updating several ondisk data structures covered by different locks. We avoid deadlock by globally ordering these locks and acquiring them in two phases. First, a server determines what locks it needs. This may involve acquiring and releasing some locks, to look up names in a directory, for example. Second, it sorts the locks by inode address and acquires each lock in turn. The server then checks whether any objects it examined in phase one were modified while their locks were released. If so, it releases the locks and loops back to repeat phase one. Otherwise, it performs the operation, dirtying some blocks in its cache and writing a log record. It retains each lock until the dirty blocks it covers are written back to disk.
The Lock Service
clerk是这个lock service的client, 负责和lock servers进行通信。每个FP server都会嵌入clerk,通过clerk和lock service进行通信。clerk向server发起request/release请求,server向clerk回复grant/revoke。它们之间的交互是异步的,FP在使用的时候向clerk发起请求,然后等待clerk的回应,超时就放弃。在release/revoke之前,FP server需要将dirty cache data刷回到petal disk上。
clerk连接上lock server都会被分配lease identifier, 也就相当给FP server分配了唯一标识符。每个lock都是一个int64整数。lock servers维护着一个 map<lock-id, lease-id> 的映射,这个映射关系会通过paxos做replication. clerk通过lease机制保证锁的有效性,和其他lease机制一样也会面临两个问题,时钟偏移以及检查lease有效性到发起操作时间太长,petal将这个margin的时间设置成为15s.
既然是通过paxos做replication的,那么做replication group的servers数量肯定不能太多,但是从之前的图上看每个petal server上都有一个lock server, 我直觉估计这个数量应该也是不少的。如果lock server的数量很多的话,那么就不能只形成一个replication group. 怎么形成多个replication group是个问题,论文里面没有说,直觉也比较困难。论文里面也提到global state information包含所有的lock servers, 所以我猜测lock server数量应该不多,只是一个replication group. 如果是这样的话就会简单许多。
并不是每个lock server都维护着所有的map<lock-id, lease-id>的映射,而是将这些lock-id分成了100个lock groups, 然后每个lock server会负责几个lock groups. 至于lock-id是如何映射到lock groups的话,论文里面没有写。但是论文里面提到了lock是可以做迁移的,所以这个映射可能是动态的。
A small amount of global state information that does not change often is consistently replicated across all lock servers using Lamport’s Paxos algorithm [23]. The lock service reuses an implementation of Paxos originally written for Petal. The global state information consists of a list of lock servers, a list of locks that each is responsible for serving, and a list of clerks that have opened but not yet closed each lock table. This information is used to achieve consensus, to reassign locks across lock servers, to recover lock state from clerks after a lock server crash, and to facilitate recovery of Frangipani servers. For efficiency, locks are partitioned into about one hundred distinct lock groups, and are assigned to servers by group, not individually.
Locks are occasionally reassigned across lock servers to compensate for a crashed lock server or to take advantage of a newly recovered lock server. A similar reassignment occurs when a lock server is permanently added to or removed from the system. In such cases, the locks are always reassigned such that the number of locks served by each server is balanced, the number of reassignments is minimized, and each lock is served by exactly one lock server. The reassignment occurs in two phases. In the first phase, lock servers that lose locks discard them from their internal state. In the second phase, lock servers that gain locks contact the clerks that have the relevant lock tables open. The servers recover the state of their new locks from the clerks, and the clerks are informed of the new servers for their locks.
关于这个系统的设计背景
what's the intended use?
environment: single lab with collaborating engineers
the authors' research lab
programming, text processing, e-mail, &c
workstations in offices
most file access is to user's own files
need to potentially share any file among any workstations
user/user collaboration
one user logging into multiple workstations
so:
common case is exclusive access; want that to be fast
but files sometimes need to be shared; want that to be correct
this was a common scenario when the paper was written
why is Frangipani's design good for the intended use?
strong consistency, which humans expect from a file system
caching in each workstation -- write-back
all updates initially applied just in workstation's cache -- fast
including e.g. creating files, creating directories, rename, &c
updates proceed without any RPCs if everything already cached
so file system code must reside in the workstation, not server
most complexity is in clients, not the shared Petal servers
more clients -> more CPU power
complex servers were a serious bottleneck in previous systems e.g. NFS, AFS