F1 Query: Declarative Querying at Scale
http://www.vldb.org/pvldb/vol11/p1835-samwel.pdf
Spanner/F1/F1 Query. 这三者是啥关系呢?我的理解是Spanner/F1是相关联的,Spanner是一个分布式(关系?)数据库系统,F1可能是在上面加入SQL界面和其他功能(这个我也不确定)。F1 Query从F1继续发展出来,它主要是提供一个SQL引擎可以同时满足:OLTP查询,OLAP查询,ETL. 最大的亮点就是将这些可能使用到的SQL场景有机地统一起来。不过好像现在OLAP查询这块还是基于row-format来做的,所以性能上相比Dremel/PowerDrill/BigQuery还差些。
F1 Query effectively blurs the traditional distinction between transactional, interactive, and batch-processing workloads, covering many use cases by sup- porting: (i) OLTP point queries that affect only a few records, (ii) low-latency OLAP querying of large amounts of data, and (iii) large ETL pipelines transforming and blending data from different sources into new tables supporting complex analysis and report- ing workloads. F1 Query has also significantly reduced the need for developing hard-coded data processing pipelines, by enabling declarative queries integrated with custom business logic. As such, F1 is a one-size-fits-all querying system that can support the vast majority of use cases for enterprise data processing and analysis.
F1 Query has evolved from F1 [55], a distributed relational database for managing revenue-critical advertising data within Google, which included a storage layer as well as an engine for processing SQL queries. In its early stages, this engine executed SQL queries against data stored in only two data sources: Span- ner [23, 55] and Mesa [38], one of Google’s analytical data ware- houses. Today, F1 Query runs as a stand-alone, federated query processing platform to execute declarative queries against data stored in different file-based formats as well as different remote storage systems (e.g., Google Spreadsheets, Bigtable [20]). F1 Query has become the query engine of choice for numerous critical applications including Advertising, Shopping, Analytics, and Pay- ments. The driving force behind this momentum comes from F1 Query’s flexibility, enabling use cases large and small, with sim- ple or highly customized business logic, and across whichever data sources the data resides in.
整个系统有这么几个亮点,前面几个亮点可以认为是数据湖,最后一个则是可扩展性:
- 对接多种数据源,Spanner, Bigtable, Google sheet, ColumnIO, files etc.
- 针对数据中心架构,可以认为是shared-disk架构. 但是长尾查询这个东西依然没有办法消除。
- 可伸缩性:OLTP查询单机完成,OLAP查询MPP架构,ETL则启动MR
- 可扩展性:UDF, UDA, TVF. 可扩展性实现上比较巧妙(UDF Server)
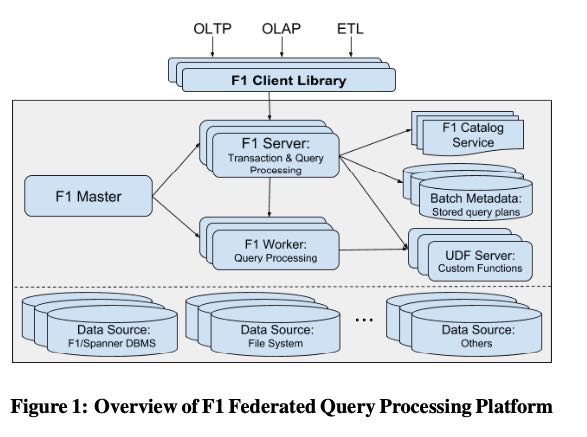
F1 server分析SQL之后根据SQL类型分为:Interactive Execution/Batch Execution. IE里面继续分为centerialized/distributed execution. 分别对应OLTP/OLAP查询
For interactive execution, the query optimizer applies heuris- tics to choose between single-node centralized execution and dis- tributed execution. In centralized execution, the server analyzes, plans, and executes the query immediately at the first F1 server that receives it. In distributed mode, the first F1 server to receive the query acts only as the query coordinator. That server sched- ules work on separate workers that then together execute the query. The interactive execution modes provide good performance and resource-efficient execution for small and medium-sized queries.
Batch mode provides increased reliability for longer-running queries that process large volumes of data. The F1 server stores plans for queries running under batch mode in a separate execution repository. The batch mode distribution and scheduling logic asyn- chronously runs the query using the MapReduce framework. Query execution in this mode is tolerant to server restarts and failures.
Exchange依赖于Google Jupiter网络任意节点之间带宽可以高达10Gbps
The exchange operation is implemented using direct Remote Procedure Calls (RPCs, for short) from each source fragment par- tition to all destination fragment partitions, with flow control be- tween each sender and receiver. This RPC-based communica- tion mode scales well up to thousands of partitions per fragment. Queries requiring higher parallelism generally run in batch execu- tion mode (described in Section 4). F1 Query’s exchange opera- tor runs locally within a datacenter, taking advantage of Google’s Jupiter network [56]. Jupiter allows each server in a cluster of tens of thousands of hosts to communicate with any other server in the same cluster with sustained bandwidth of at least 10 Gb/s.
支持CTE, 同时也支持spill策略
As discussed earlier, the execution plans in F1 are DAG shaped, potentially with multiple roots. For forks in the data flow DAG, a plan fragment repartitions to multiple destination fragments, each with different partitioning functions. These DAG forks implement run-once semantics for SQL WITH clauses and identical subplans that are deduplicated by the optimizer. The DAG forks are also used for other complex plans e.g., analytic functions and multiple aggregations over DISTINCT inputs. DAG forks are sensitive to different data consumption speeds in consumer fragments, as well as to distributed deadlocks if multiple branches block when merg- ing again later. Examples include self hash-joins from DAG forks that attempt to initially consume all tuples during the build phase. Exchange operators that implement DAG forks address these prob- lems by buffering data in memory and then spilling data to Colossus when all consumers are blocked.
Batch执行框架的映射关系比较简单,不过可以在上面做一些优化比如右表创建出来之后,可以生成sstable, 然后左表开始scan的时候可以进行点查,或者是使用bloom filter等计数来减少数据量。
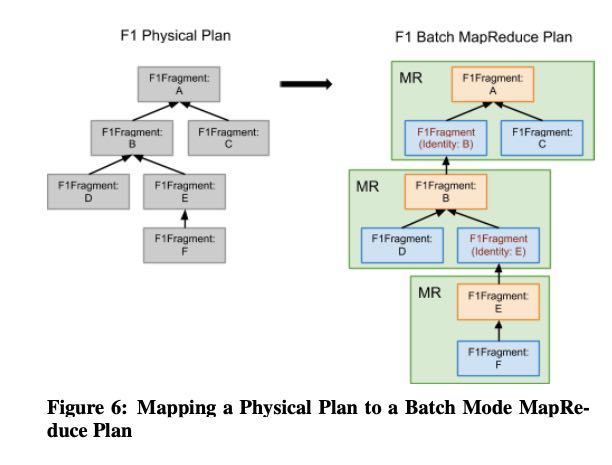
Note that F1 Query batch mode operates at very large scale, and incurs a large data materialization overhead for every exchange op- erator in the query plan. As such, it is beneficial to reduce the num- ber of exchange operators in the plan where possible, especially when dealing with very large tables. One method of avoiding ex- change operators is by replacing a hash join with a lookup join. For joins where the smaller input is too large for a broadcast hash join, or where there is significant skew, batch mode can materi- alize the smaller input into disk-based lookup tables called sorted string tables (SSTables) [20]. It then uses a lookup join operator, in the same fragment as the larger input, to look up into these tables, thereby avoiding a costly repartitioning on the larger input. The lookups use a distributed caching layer to reduce disk I/O.
Query Optimizer使用脚本生成可以极大地减少代码工作量和提升稳定性;认为PB结构是first-citizen可以将predicates推送到里面,并且读取的时候只读取必要的列。
The optimizer has separate tree hierarchies for expressions, log- ical plans, and physical plans. The boilerplate code for the hun- dreds of tree node kinds is generated from only ~3K lines of Python code accompanied by ~5K lines of Jinja2 [7] templates, resulting in ~600K lines of C++. The generated code enables a domain spe- cific language (DSL) for query planning and contains methods to compute a hash for each tree node, to perform tree equality compar- isons, as well as other helpers suitable for storing trees in standard collections and representing them in testing frameworks. The use of code generation saves F1 Query engineers considerable time, re- duces mistakes during development, and enables the effective roll- out of new features across tree hierarchies.
All relational algebra rules and plan conversion stages inspect and manipulate trees using a C++ embedded DSL for tree pattern matching and building. Because of code generation and C++ tem- plates, tree pattern expressions perform as well as optimized hand- written code. At the same time, they are more concise than hand written code and more clearly express the intent of each rewrite.
Data sources in F1 Query may include structured protocol buffer data within relational table columns, and all rules have first-class knowledge of protocol buffers. For example, the core attribute pruning rule recursively pushes down extraction operation expres- sions for individual protocol buffer fields down the query plan as far as possible. If such extractions travel all the way to the leaves of the query plan, it often becomes possible to integrate them into scan operations to reduce the number of bytes read from the disk or transferred over the network.
The exact structure and types of all protos referenced in a query are known at query planning time, and the optimizer prunes away all unused fields from data source scans. Within columnar data sources, this reduces I/O and enables efficient column-wise evalu- ation of filters. For record-oriented data sources that uses the row- wise binary format, F1 Query uses an efficient streaming decoder that makes a single pass over the encoded data and extracts only the necessary fields, skipping over irrelevant data. This is enabled only by the fixed definition of each protocol buffer type, and the integer field identifiers that are fast to identify and skip over.
扩展性上主要体现在支持UDF,UDA,TVF. 大约两种方式来实现:
- 使用SQL/lua脚本语言,这种通常是发送到worker上去解释执行。
- 使用C++/Java编译语言,这种通常是启动一个UDF Server然后进行RPC交互。这个RPC是双向交互的,input/output bidirectional.
F1 Query is extensible in various ways: it supports custom data sources as well as user defined scalar functions (UDFs), aggrega- tion functions (UDAs), and table-valued functions (TVFs). User defined functions can use any type of data as input and output, in- cluding Protocol Buffers. Clients may express user-defined logic in SQL syntax, providing them with a simple way of abstracting common concepts from their queries and making them more read- able and maintainable. They may also use Lua [42] scripts to define additional functions for ad-hoc queries and analysis. For compiled and managed languages like C++ and Java, F1 Query in- tegrates with specialized helper processes known as UDF servers to help clients reuse common business logic between SQL queries and other systems.
UDF servers are RPC services owned and deployed separately by F1 Query clients. They are typically written in C++, Java, or Go, and execute in the same datacenters as the F1 servers and workers that call them. Each client maintains complete control over their own UDF server release cycle and resource provisioning. The UDF servers expose a common RPC interface that enables the F1 server to find out the details of the functions they export and to actually execute these functions. To make use of the extensions provided by a UDF server, the F1 Query client must provide the address of the UDF server pool in the query RPC that it sends to the F1 server. Alternatively, owners of F1 databases may configure default UDF servers that will be made available to all queries that run in the con- text of that database. Even though F1 will communicate with UDF servers during query execution, they remain separate processes and isolate the core F1 system from failures in the custom functions.
文章最后和几个Google现有系统进行了对比:
- Spanner SQL. OLAP以及事务实现
- BigQuery. 没有OLTP查询,可能启动overhead相比更大些。
- PowerDrill. 我不太清楚这个东西,看到后面好像是个全内存的系统
- Tenzing/FlumeJava/Dataflow. 更像是执行引擎
后续工作好像也比较像数据湖的工作:
- 列式存储+矢量计算
- 存算分离之后带来的storage cache
- 如何收集统计信息
- 如何做到scale-in? 降低网络交互延迟?
F1 Query continues to undergo active development to address new use cases and to close performance gaps with purpose-built systems. For instance, F1 Query does not yet match the perfor- mance of vectorized, columnar execution engines (e.g. Vector- wise [63]) because of its row-oriented execution kernel. A transi- tion to a vectorized execution kernel is future work. F1 Query also does not support local caches for data in the query engine’s native format, such as one naturally finds in shared-nothing architectures, since all data sources are disaggregated and remote. Currently, F1 Query relies on existing caches in the data sources, or remote caching layers such as TableCache [50]. To support in-memory or nearly-in-memory analytics, such as offered by PowerDrill [39], F1 Query would need to support local caching on individual work- ers and locality-aware work scheduling that directs work to servers where data is likely to be cached. The use of remote data sources also makes it harder to collect statistics for use in query optimiza- tion, but we are working to make them available so that F1 Query can use cost based optimization rules. And while F1 Query has excellent support for scaling out, we are working on techniques to improve how F1 scales in, for example, by running medium-sized distributed queries on only a few servers, thereby reducing the cost and latency of exchange operations.