Effective Scala
Table of Contents
http://twitter.github.io/effectivescala/
还是看 中文版 比较省力:)
1. Introduction
Scala provides many tools that enable succinct expression. Less typing is less reading, and less reading is often faster reading, and thus brevity enhances clarity. However brevity is a blunt tool that can also deliver the opposite effect: After correctness, think always of the reader.
>> Scala提供很多工具使表达式可以很简洁。敲的少读的就少,读的少就能更快的读,因此简洁增强了代码的清晰。然而简洁也是一把钝器(blunt tool)也可能起到相反的效果:在考虑正确性之后,也要为读者着想。
Above all, program in Scala. You are not writing Java, nor Haskell, nor Python; a Scala program is unlike one written in any of these. In order to use the language effectively, you must phrase your problems in its terms. There’s no use coercing a Java program into Scala, for it will be inferior in most ways to its original.
>> 首先,用Scala编程,你不是在写Java,Haskell或Python;Scala程序不像这其中的任何一种。为了高效的使用语言,你必须用其术语表达你的问题。 强制把Java程序转成Scala程序是无用的,因为大多数情况下它会不如原来的。
This is a living document that will change to reflect our current “best practices,” but its core ideas are unlikely to change: Always favor readability; write generic code but not at the expensive of clarity; take advantage of simple language features that afford great power but avoid the esoteric ones (especially in the type system). Above all, be always aware of the trade offs you make A sophisticated language requires a complex implementation, and complexity begets complexity: of reasoning, of semantics, of interaction between features, and of the understanding of your collaborators. Thus complexity is the tax of sophistication — you must always ensure that its utility exceeds its cost.
>> 永远重视可读性;写泛化的代码但不要牺牲清晰度; 利用简单的语言特性的威力,但避免晦涩难懂(尤其是类型系统)。最重要的,总要意识到你所做的取舍。一门成熟的(sophisticated)语言需要复杂的实现,复杂性又产生了复杂性:之于推理,之于语义,之于特性之间的交互,以及与你合作者之间的理解。因此复杂性是为成熟所交的税——你必须确保效用超过它的成本。
2. Formatting
用主动语态(active)来命名有副作用的操作:user.activate()而非 user.setActive()
getters不采用前缀get:用get是多余的: site.count而非site.getCount
不要诉诸于ASCII码艺术或其他可视化修饰。用文档记录APIs但不要添加不必要的注释。如果你发现你自己添加注释解释你的代码行为,先问问自己是否可以调整代码结构,从而可以明显地可以看出它做了什么。相对于“it works, obviously” 更偏向于“obviously it works”
3. Types and Generics
Scala的强大类型系统是学术探索和实践共同来源(例如 Type level programming in Scala) 。但这是一个迷人的学术话题,这些技术很少在应用和正式产品代码中使用。它们应该被避免。
Immutable collections should be covariant. Methods that receive the contained type should “downgrade” the collection appropriately. Mutable collections should be invariant. Covariance is typically invalid with mutable collections.
>> 不可变(Immutable)集合应该是协变的(covariant)。接受容器化类型得方法应该适当地降级(downgrade)集合. 可变(mutable)集合应该是不可变的(invariant). 协变对于可变集合是典型无效的。
If you do find yourself using implicits, always ask yourself if there is a way to achieve the same thing without their help. Do not use implicits to do automatic conversions between similar datatypes (for example, converting a list to a stream); these are better done explicitly because the types have different semantics, and the reader should beware of these implications.
>> 如果你发现自己在用隐式转换,总要问问自己是否不使用这种方式也可以达到目的。不要使用隐式转换对两个相似的数据类型做自动转换(例如,把list转换为stream);显示地做更好,因为不同类型有不同的语意,读者应该意识到这些含义。
4. Collections
http://www.scala-lang.org/docu/files/collections-api/collections.html
Scala有一个非常通用,丰富,强大,可组合的集合库;集合是高阶的(high level)并暴露了一大套操作方法。很多集合的处理和转换可以被表达的简洁又可读,但不审慎地用它们的功能也会导致相反的结果。每个Scala程序员应该阅读 集合设计文档;通过它可以很好地洞察集合库,并了解设计动机。 总使用最简单的集合来满足你的需求
The collections library is large: in addition to an elaborate hierarchy — the root of which being Traversable[T] — there are immutable and mutable variants for most collections. Whatever the complexity, the following diagram contains the important distinctions for both immutable and mutable hierarchies.
>> 集合库很大:除了精心设计的层级(Hierarchy)——根是 Traversable[T] —— 大多数集合都有不可变(immutable)和可变(mutable)两种变体。无论其复杂性,下面的图表包含了可变和不可变集合层级的重要差异。
Iterable[T] 是所有可遍历的集合,它提供了迭代的方法(foreach)。Seq[T] 是有序集合,Set[T]是数学上的集合(无序且不重复),Map[T]是关联数组,也是无序的。
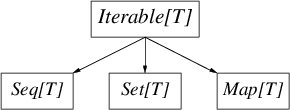
- Iterable[T] is any collection that may be iterated over, they provide an iterator method (and thus foreach).
- Seq[T]s are collections that are ordered,
- Set[T]s are mathematical sets (unordered collections of unique items),
- and Map[T]s are associative arrays, also unordered.
Prefer using immutable collections. They are applicable in most circumstances, and make programs easier to reason about since they are referentially transparent and are thus also threadsafe by default. Use the mutable namespace explicitly.
>> 优先使用不可变集合。不可变集合适用于大多数情况,让程序易于理解和推断,因为它们是引用透明的( referentially transparent )因此缺省也是线程安全的。使用可变集合时,明确地引用可变集合的命名空间。
import scala.collection.mutable val set = mutable.Set()
Use the default constructor for the collection type. The corollary to the above is: in your own methods and constructors, receive the most generic collection type appropriate. This typically boils down to one of the above: Iterable, Seq, Set, or Map.
>> 使用集合类型缺省的构造函数。上面的推论是:在你自己的方法和构造函数里,适当地接受最宽泛的集合类型。通常可以归结为Iterable, Seq, Set, 或 Map中的一个。如果你的方法需要一个 sequence,使用 Seq[T],而不是List[T]
High level collections libraries (as with higher level constructs generally) make reasoning about performance more difficult: the further you stray from instructing the computer directly — in other words, imperative style — the harder it is to predict the exact performance implications of a piece of code. Reasoning about correctness however, is typically easier; readability is also enhanced. With Scala the picture is further complicated by the Java runtime; Scala hides boxing/unboxing operations from you, which can incur severe performance or space penalties.
>> 高阶集合库(通常也伴随高阶构造)使推理性能更加困难:你越偏离直接指示计算机——即命令式风格——就越难准确预测一段代码的性能影响。然而推理正确性通常很容易;可读性也是加强的。在Java运行时使用Scala使得情况更加复杂,Scala对你隐藏了装箱(boxing)/拆箱(unboxing)操作,可能引发严重的性能或内存空间问题。
Use scala.collection.JavaConverters to interoperate with Java collections. These are a set of implicits that add conversion asJava and asScala conversion methods. The use of these ensures that such conversions are explicit, aiding the reader.
>> 使用 scala.collection.JavaConverters 与Java集合交互。它有一系列的隐式转换,添加了asJava和asScala的转换方法。使用它们这些方法确保转换是显式的,有助于阅读
5. Concurrency
完全看不懂下面这段话的意思. 感觉像是说了一些什么, 但是好像油什么都没有说:X. 资源管理确实危害了模块化, 但是线程本身并没有让逻辑从基础资源中分离出来更加复杂.
现代服务是高度并发的—— 服务器通常是在10–100秒内并列上千个同时的操作——处理隐含的复杂性是创作健壮系统软件的中心主题。
线程提供了一种表达并发的方式:它们给你独立的,堆共享的(heap-sharing)由操作系统调度的执行上下文。然而,在Java里线程的创建是昂贵的,是一种必须托管的资源,通常借助于线程池。这对程序员创造了额外的复杂,也造成高度的耦合:很难从所使用的基础资源中分离应用逻辑。
当创建高度分散(fan-out)的服务时这种复杂度尤其明显: 每个输入请求导致一大批对另一层系统的请求。在这些系统中,线程池必须被托管以便根据每一层请求的比例来平衡:一个线程池的管理不善会导致另一个线程池也出现问题。
一个健壮系统必须考虑超时和取消,两者都需要引入更多“控制”线程,使问题更加复杂。注意若线程很廉价这些问题也将会被削弱:不再需要一个线程池,超时的线程将被丢弃,不再需要额外的资源管理。
因此,资源管理危害了模块化。
Prefer transforming futures over creating your own. Future transformations ensure that failures are propagated, that cancellations are signalled, and free the programmer from thinking about the implications of the Java memory model.
>> 更愿意转换(transforming)future而非自己创造。Future的转换(transformations)确保失败会传播,可以通过信号取消,对于程序员来说不必考虑Java内存模型的含义。
The subject of concurrent collections is fraught with opinions, subtleties, dogma and FUD. In most practical situations they are a nonissue: Always start with the simplest, most boring, and most standard collection that serves the purpose. Don’t reach for a concurrent collection before you know that a synchronized one won’t do: the JVM has sophisticated machinery to make synchronization cheap, so their efficacy may surprise you.
>> 并发集合的主题充满着意见、微妙(subtleties)、教条、恐惧/不确定/怀疑(FUD)。在大多实际场景都不存在问题:总是先用最简单,最无聊,最标准的集合解决问题。 在你知道不能使用synchronized前不要去用一个并发集合:JVM有着老练的手段来使得同步开销更小,所以它的效率能让你惊讶。
If an immutable collection will do, use it — they are referentially transparent, so reasoning about them in a concurrent context is simple. Mutations in immutable collections are typically handled by updating a reference to the current value (in a var cell or an AtomicReference). Care must be taken to apply these correctly: atomics must be retried, and vars must be declared volatile in order for them to be published to other threads.
>> 如果一个不可变(immutable)集合可行,就尽可能用不可变集合——它们是指称透明的(referentially transparent),所以在并发上下文推断它们是简单的。不可变集合的改变通常用更新引用到当前值(一个var单元或一个AtomicReference)。必须小心正确地应用:原子型的(atomics)必须重试(retried),变量(var类型的)必须声明为volatile以保证它们发布(published)到它们的线程。
可变的并发集合有着复杂的语义,并利用Java内存模型的微妙的一面,所以在你使用前确定你理解它的含义——尤其对于发布更新(新的公开方法)。同步的集合同样写起来更好:像getOrElseUpdate操作不能够被并发集合正确的实现,创建复合(composite)集合尤其容易出错。
6. Control structures
returns can have hidden costs: when used inside of a closure. implemented in bytecode as an exception catching/throwing pair which, used in hot code, has performance implications.
>> return会有隐性开销:当在闭包内部使用时。在字节码层实现为一个异常的捕获/声明(catching/throwing)对,用在频繁的执行的代码中,会有性能影响。
seq foreach { elem =>
if (elem.isLast)
return
// process...
}
require and assert both serve as executable documentation. Both are useful for situations in which the type system cannot express the required invariants. assert is used for invariants that the code assumes. Whereas require is used to express API contracts:
>> 要求(require)和断言(assert)都起到可执行文档的作用。两者都在类型系统不能表达所要求的不变量(invariants)的场景里有用。 assert用于代码假设的不变量(invariants) (内部或外部的)相反,require用于表达API契约
7. Functional programming
Value oriented programming confers many advantages, especially when used in conjunction with functional programming constructs. This style emphasizes
- the transformation of values over stateful mutation,
- yielding code that is referentially transparent,
- providing stronger invariants and thus also easier to reason about.
- Case classes, pattern matching, destructuring bindings, type inference, and lightweight closure- and method-creation syntax are the tools of this trade.
>> 面向值(value-oriented )编程有很多优势,特别是用在与函数式编程结构相结合。这种风格强调值的转换(译注:由一个不变的值生成另一个不变的值)而非状态的改变,生成的代码是指称透明的(referentially transparent),提供了更强的不变型(invariants),因此容易实现。Case类(也被翻译为样本类),模式匹配,解构绑定(destructuring bindings),类型推断,轻量级的闭包和方法创建语法都是这一类的工具。
The Option type is a container that is either empty (None) or full (Some(value)). They provide a safe alternative to the use of null, and should be used in their stead whenever possible. They are a collection (of at most one item) and they are embellished with collection operations — use them!
>> Option类型是一个容器,空(None)或满(Some(value))二选一。它提供了使用null的另一种安全选择,应该尽可能的替代null。它是一个集合(最多只有一个元素)并用集合操所修饰,尽量用Option。
Use lazy fields for this purpose, but avoid using laziness when laziness is required by semantics. In these cases it's better to be explicit since it makes the cost model explicit, and side effects can be controlled more precisely. Lazy fields are thread safe.
>> 它在需要时计算结果并会记住结果,在要达到这种目的时使用lazy成员;但当语意上需要惰性赋值时(by semantics),要避免使用惰性赋值,这种情况下,最好显式赋值因为它使得成本模型是明确的,并且副作用被严格的控制。Lazy成员是线程安全的。
flatMap — the combination of map with flatten — deserves special attention, for it has subtle power and great utility. Like its brethren map, it is frequently available in nontraditional collections such as Future and Option.
>> flatMap——结合了map 和 flatten —— 的使用要特别小心,它有着难以琢磨的威力和强大的实用性。类似它的兄弟 map,它也是经常在非传统的集合中使用的,例如 Future , Option。
8. Object oriented programming
9. Error handling
10. Garbage collection
We spend a lot of time tuning garbage collection in production. The garbage collection concerns are largely similar to those of Java though idiomatic Scala code tends to generate more (short-lived) garbage than idiomatic Java code — a byproduct of the functional style. Hotspot’s generational garbage collection typically makes this a nonissue as short-lived garbage is effectively free in most circumstances.
>> 我们对生产中花了很多时间来调整垃圾回收。垃圾回收的关注点与Java大致相似,尽管一些惯用的Scala代码比起惯用的Java代码会容易产生更多(短暂的)垃圾——函数式风格的副产品。Hotspot的分代垃圾收集通常使这不成问题,因为短暂的(short-lived)垃圾在大多情形下会被有效的释放掉。
Before tackling GC performance issues, watch this presentation by Attila that illustrates some of our experiences with GC tuning.
In Scala proper, your only tool to mitigate GC problems is to generate less garbage; but do not act without data! Unless you are doing something obviously degenerate, use the various Java profiling tools — our own include heapster and gcprof.
>> Scala固有的问题,你能够缓解GC的方法是产生更少的垃圾;但不要在没有数据的情况下行动。除非你做了某些明显的恶化,使用各种Java的profiling工具——我们拥有的包括heapster和gcprof。
11. Java compatibility
12. Twitter's standard libraries
The most important standard libraries at Twitter are Util and Finagle. Util should be considered an extension to the Scala and Java standard libraries, providing missing functionality or more appropriate implementations. Finagle is our RPC system; the kernel distributed systems components.
>> Twitter最重要的标准库是 Util 和 Finagle。Util 可以理解为Scala和Java的标准库扩展,提供了标准库中没有的功能或已有功能的更合适的实现。Finagle 是我们的RPC系统,核心分布式系统组件。
Futures
Twitter’s futures are asynchronous, so blocking operations — basically any operation that can suspend the execution of its thread; network IO and disk IO are examples — must be handled by a system that itself provides futures for the results of said operations. Finagle provides such a system for network IO.
Twitter的future是异步的,所以基本上任何操作(阻塞操作)——基本上任何可以suspend它的线程的执行;网络IO和磁盘IO是就是例子——必须由系统处理,它为结果提供future。Finagle为网络IO提供了这样一种系统。
Local
Util’s Local provides a reference cell that is local to a particular future dispatch tree. Setting the value of a local makes this value available to any computation deferred by a Future in the same thread. They are analogous to thread locals, except their scope is not a Java thread but a tree of “future threads”.
As with thread locals, Locals can be very convenient, but should almost always be avoided: make sure the problem cannot be sufficiently solved by passing data around explicitly, even if it is somewhat burdensome.
Locals are used effectively by core libraries for very common concerns — threading through RPC traces, propagating monitors, creating “stack traces” for future callbacks — where any other solution would unduly burden the user. Locals are inappropriate in almost any other situation.
Util的Local提供了一个位于特定的future派发树(dispatch tree)的引用单元(cell)。设定一个local的值,使这个值可以用于被同一个线程的Future 延迟的任何计算。有一些类似于thread locals(注:Java中的线程机制),不同的是它们的范围不是一个Java线程,而是一个 future 线程树。
就thread locals来说,我们的Locals非常的方便,但要尽量避免使用:除非确信通过显式传递数据时问题不能被充分的解决,哪怕解决起来有些繁重。
Locals有效的被核心库使用在非常常见的问题上——线程通过RPC跟踪,传播监视器,为future的回调创建stack traces——任何其他解决方法都使得用户负担过度。Locals在几乎任何其他情况下都不适合。
Offer/Broker
Concurrent systems are greatly complicated by the need to coordinate access to shared data and resources. Actors present one strategy of simplification: each actor is a sequential process that maintains its own state and resources, and data is shared by messaging with other actors. Sharing data requires communicating between actors.
并发系统由于需要协调访问数据和资源而变得复杂。Actor提出一种简化的策略:每一个actor是一个顺序的进程(process),保持自己的状态和资源,数据通过消息的方式与其它actor共享。 共享数据需要actor之间通信。
Offer/Broker builds on this in three important ways. First, communication channels (Brokers) are first class — that is, you send messages via Brokers, not to an actor directly. Secondly, Offer/Broker is a synchronous mechanism: to communicate is to synchronize. This means we can use Brokers as a coordination mechanism: when process a has sent a message to process b; both a and b agree on the state of the system. Lastly, communication can be performed selectively: a process can propose several different communications, and exactly one of them will obtain.
Offer/Broker 建立于Actor之上,以这三种重要的方式表现:1,通信通道(Brokers)是first class——即发送消息需要通过Brokers,而非直接到actor。2, Offer/Broker 是一种同步机制:通信会话是同步的。 这意味我们可以用 Broker做为协调机制:当进程a发送一条信息给进程b;a和b都要对系统状态达成一致。3, 最后,通信可以选择性地执行:一个进程可以提出几个不同的通信,其中的一个将被获取。