推荐系统讨论
@20160218 这天晚上和wenjie讨论了一下推荐系统的设计,主要是在框架层面的讨论。下面是这次讨论的草稿纸。顺便说一句,之前和minghua老师也有过一次关于反作弊的讨论,不过草稿纸就比这个要高大上不少了, 用的是iPad Pro + iPencil,体验确实非常的好
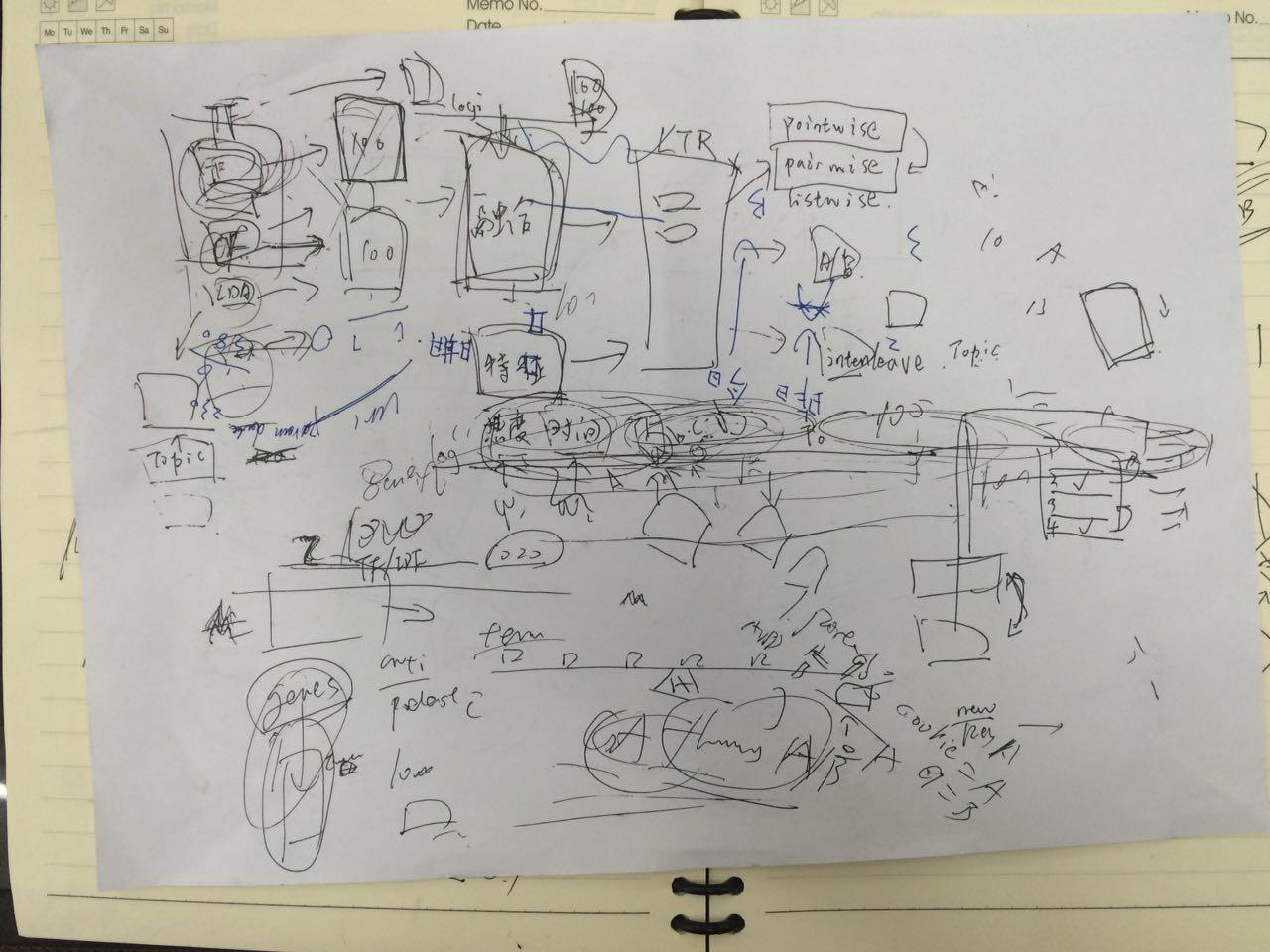
从图的左上角开始,一般会有多个特定的算法比如TF-IDF来计算item之间的相似度来选取item,以及使用CF来计算用户相似度然后选取item,或者使用topic-model算法比如LDA来选取潜在相似的item. 不同算法有不同的侧重,TF-IDF主要是从term上来考察item, 而topic-model可以说从语义上来考察item。这两个都是从item本身之间的相似性来考量,而CF则依赖于些潜在相似用户的表现。比如UserA喜欢(漫画,音乐),如果UserB只关注漫画这个频道的话,使用TF-IDF或是topic model只能找出和漫画相关的item, 而通过发现UserB和UserA比较相似的话则可以推荐一些音乐相关的item.
多个特定的算法都会返回topN. 在图上就是100. 接着对每个算法产生的top100进行融合。具体怎么做wenjie也没有和我说,融合算法只输出部分输入,比如也选取100个。然后再进入第三步LTR(learning to rank). LTR这个模块只是根据item本身的属性做特征来进行学习排序,比如热度,时间,TF-IDF-feature-vector, LDA-feature-vector等等,当然也可能没有那么复杂,只是用在TF-IDF和在LDA输出列表中的rank来做特征。学习排序的Y可以是pointwise(为这个item单纯定义一个分数), 也可以是pairwise(返回顺序是itemA, itemB. 但是用户却点击了itemB, 那么认为itemB实际效果应该比itemA要好。那么产生item A, item B, -1. 这样的数据,表示item A rank < item B rank), 也可以是listwise(这个wenjie没有和我说)
所有的这些都只是离线计算部分。从架构上看各个模块都比较独立,可以异步化工作。还有一个需要解决的问题是,这些计算部分如何来做准实时处理。准实时处理应该是根据用户行为快速地计算出一个delta item set. 最后在LTR部分与离线计算结果做合并。