Designs, Lessons and Advice from Building Large Distributed Systems
Table of Contents
- http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf
- http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//people/jeff/stanford-295-talk.pdf
1. Architectural view of the storage hierarchy
对于分布式系统来说,存储层次扩展到了rack,cluster,datacenter级别
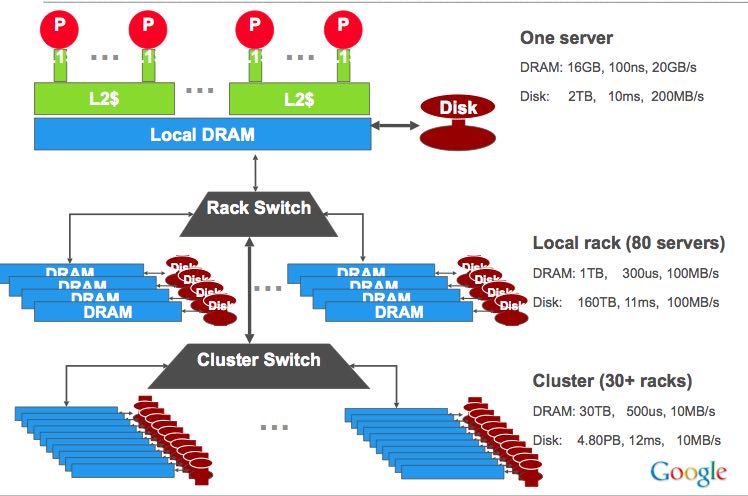
- 带宽收到了网络限制,因此memory和disk的bandwidth是相同的。
- 内存延迟变化比较大,而disk延迟本身基数就比较大因此变化不明显。
2. Reliability & Availability
- Things will crash. Deal with it! (就是MTBF有30年,但是如果有上万节点的话,那么每年也会挂掉一台,所以设计fault-tolerant软件是必要的)
- Assume you could start with super reliable servers (MTBF of 30 years)
- Build computing system with 10 thousand of those
- Watch one fail per day
- Fault-tolerant software is inevitable
- Typical yearly flakiness metrics
- 1-5% of your disk drives will die
- Servers will crash at least twice (2-4% failure rate)
3. Making Applications Robust Against Failures
- Canary requests
- Failover to other replicas/datacenters
- Bad backend detection:(后端故障检测,如果出现问题尽早退出)
- stop using for live requests until behavior gets better
- More aggressive load balancing when imbalance is more severe(比较严重的imbalance那么越需要比较激进的balance策略)
- Make your apps do something reasonable even if not all is right – Better to give users limited functionality than an error page(出现问题的话尽可能地只是限制功能)
4. Add Sufficient Monitoring/Status/Debugging Hooks
- All our servers:
- Export HTML-based status pages for easy diagnosis(输出HTML状态页面便于简单地分析)
- Export a collection of key-value pairs via a standard interface – monitoring systems periodically collect this from running servers(通过标准接口输出kv便于收集数据) #note: 这点和JMX类似,但是JMX过于重量
- RPC subsystem collects sample of all requests, all error requests, all requests >0.0s, >0.05s, >0.1s, >0.5s, >1s, etc.(RPC收集请求采样并且统计时间分布)
- Support low-overhead online profiling #note: 这点JMX也完成得非常好
- cpu profiling
- memory profiling
- lock contention profiling
- If your system is slow or misbehaving, can you figure out why?
5. BigTable: What’s New Since OSDI’06?
bigtable相对于原始论文的改进
- Lots of work on scaling
- Service clusters, managed by dedicated team
- Improved performance isolation(隔离性)
- fair-share scheduler within each server, better accounting of memory used per user (caches, etc.)(每个server对用户使用资源进行隔离)
- can partition servers within a cluster for different users or tables(每个table和用户允许使用的服务器不同)
- Improved protection against corruption
- many small changes
- e.g. immediately read results of every compaction, compare with CRC. Catches ~1 corruption/5.4 PB of data compacted
- Replication
- Configured on a per-table basis
- Typically used to replicate data to multiple bigtable clusters in different data centers
- Eventual consistency model: writes to table in one cluster eventually appear in all configured replicas(最终一致性)
- Nearly all user-facing production uses of BigTable use replication(延迟已经非常低)
- Coprocessors
- Arbitrary code that runs run next to each tablet in table
- as tablets split and move, coprocessor code automatically splits/moves too
- High-level call interface for clients
- Unlike RPC, calls addressed to rows or ranges of rows
- coprocessor client library resolves to actual locations
- Calls across multiple rows automatically split into multiple parallelized RPCs
- Very flexible model for building distributed services
- automatic scaling, load balancing, request routing for apps
- Arbitrary code that runs run next to each tablet in table