Design Data-Intensive Applications
Table of Contents
这是一本关于大规模分布式存储系统的书籍,基本上每个topic都涉及到了并且有深入的介绍,既可以作为index也可以作为introduction.
Chapter1 可靠性,可扩展性,可维护性
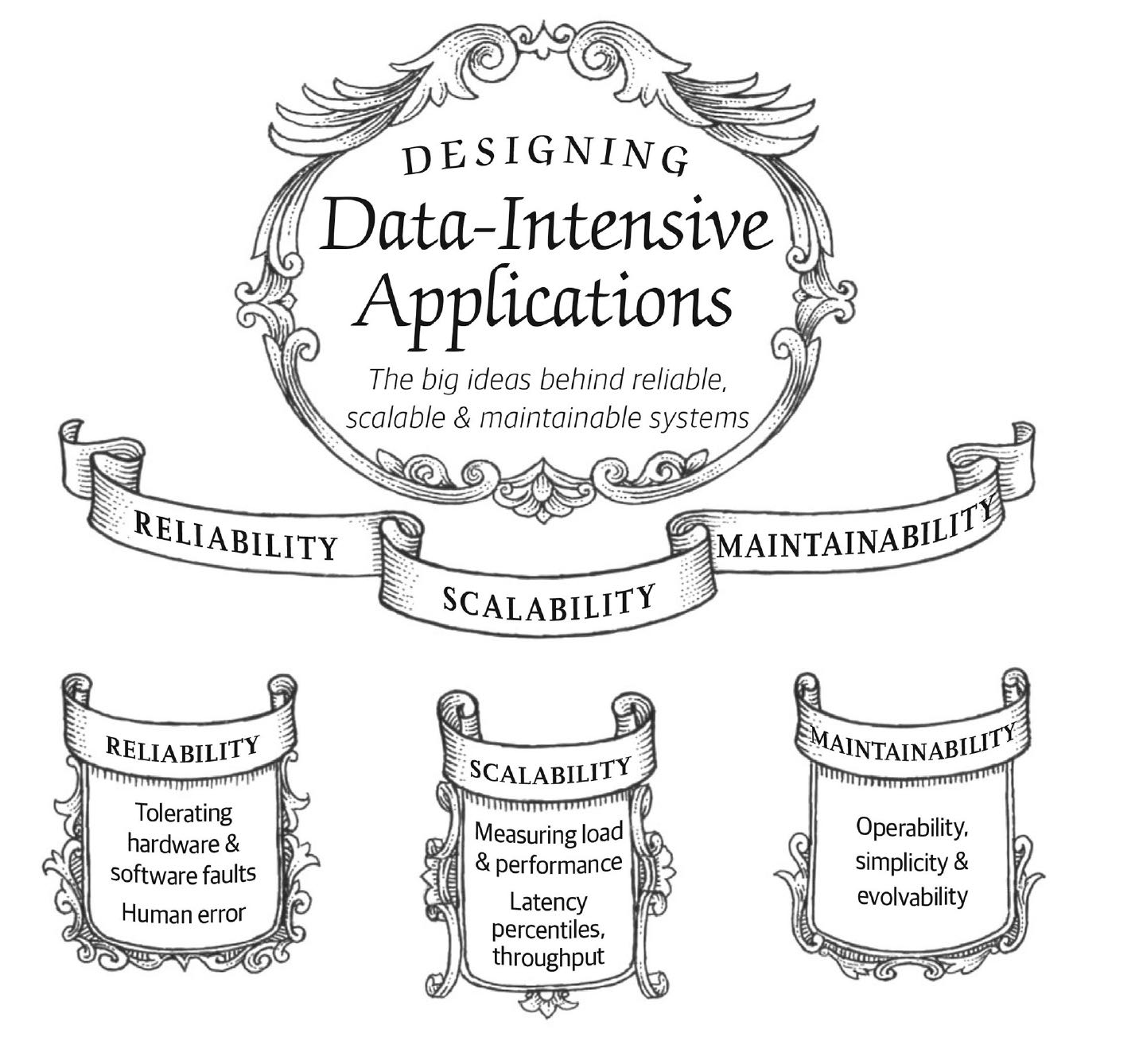
这章讨论了Data-Intensive应用在Reliability(可用性),Scalability(扩展性),Maintainability(可维护性)三个方面可能遇到的问题,这些问题的原因是什么,以及这些问题的解决办法。
为了减少系统的故障率,第一反应通常都是增加单个硬件的冗余度,例如:磁盘可以组建RAID,服务器可能有双路电源和热插拔CPU,数据中心可能有电池和柴油发电机作为后备电源,某个组件挂掉时冗余组件可以立刻接管。这种方法虽然不能完全防止由硬件问题导致的系统失效,但它简单易懂,通常也足以让机器不间断运行很多年。
直到最近,硬件冗余对于大多数应用来说已经足够了,它使单台机器完全失效变得相当罕见。只要你能快速地把备份恢复到新机器上,故障停机时间对大多数应用而言都算不上灾难性的。只有少量高可用性至关重要的应用才会要求有多套硬件冗余。
但是随着数据量和应用计算需求的增加,越来越多的应用开始大量使用机器,这会相应地增加硬件故障率。此外在一些云平台(如亚马逊网络服务(AWS, Amazon Web Services))中,虚拟机实例不可用却没有任何警告也是很常见的【7】,因为云平台的设计就是优先考虑灵活性(flexibility)和弹性(elasticity),而不是单机可靠性。
如果在硬件冗余的基础上进一步引入软件容错机制,那么系统在容忍整个(单台)机器故障的道路上就更进一步了。这样的系统也有运维上的便利,例如:如果需要重启机器(例如应用操作系统安全补丁),单服务器系统就需要计划停机。而允许机器失效的系统则可以一次修复一个节点,无需整个系统停机。
Chapter2 数据模型与查询语言
这章讨论了各种数据模型:关系模型(从层次化模型演化过来),文档模型,图模型。这三种是现在使用最多的三种通用模型,还有很多场景需要定制化的数据模型。另外还有一节讨论数据查询语言。
支持文档数据模型的主要论据是架构灵活性,因局部性而拥有更好的性能,以及对于某些应用程序而言更接近于应用程序使用的数据结构。关系模型通过为连接提供更好的支持以及支持多对一和多对多的关系来反击。
在历史上,数据最开始被表示为一棵大树(层次数据模型),但是这不利于表示多对多的关系,所以发明了关系模型来解决这个问题。最近,开发人员发现一些应用程序也不适合采用关系模型。新的非关系型“NoSQL”数据存储在两个主要方向上存在分歧:
- 文档数据库的应用场景是:数据通常是自我包含的,而且文档之间的关系非常稀少。
- 图形数据库用于相反的场景:任意事物都可能与任何事物相关联。
这三种模型(文档,关系和图形)在今天都被广泛使用,并且在各自的领域都发挥很好。一个模型可以用另一个模型来模拟 — 例如,图数据可以在关系数据库中表示 — 但结果往往是糟糕的。这就是为什么我们有着针对不同目的的不同系统,而不是一个单一的万能解决方案。
文档数据库和图数据库有一个共同点,那就是它们通常不会为存储的数据强制一个模式,这可以使应用程序更容易适应不断变化的需求。但是应用程序很可能仍会假定数据具有一定的结构;这只是模式是明确的(写入时强制)还是隐含的(读取时处理)的问题。
Chapter3 存储与检索
这章对于了解数据库系统非常有帮助。两种数据存储引擎实现方式:log-strucutred(LSM, SSTable) and page-oriented(BTree). LSM比较适合写多读少,而BTree适合写少读多,但是即便是短板性能上也还是可以的。OLTP和OLAP引擎和索引方式有很大的不同,使用列式存储(column-oriented storage).
LSM树相比B树的优缺点
LSM树的优点:
在写入繁重的应用程序中,性能瓶颈可能是数据库可以写入磁盘的速度。在这种情况下,写放大会导致直接的性能代价:存储引擎写入磁盘的次数越多,可用磁盘带宽内的每秒写入次数越少。
而且,LSM树通常能够比B树支持更高的写入吞吐量,部分原因是它们有时具有较低的写放大(尽管这取决于存储引擎配置和工作负载),部分是因为它们顺序地写入紧凑的SSTable文件而不是必须覆盖树中的几个页面【26】。这种差异在磁性硬盘驱动器上尤其重要,顺序写入比随机写入快得多。
LSM树可以被压缩得更好,因此经常比B树在磁盘上产生更小的文件。 B树存储引擎会由于分割而留下一些未使用的磁盘空间:当页面被拆分或某行不能放入现有页面时,页面中的某些空间仍未被使用。由于LSM树不是面向页面的,并且定期重写SSTables以去除碎片,所以它们具有较低的存储开销,特别是当使用平坦压缩时【27】。
LSM树的缺点:
压缩的另一个问题出现在高写入吞吐量:磁盘的有限写入带宽需要在初始写入(记录和刷新内存表到磁盘)和在后台运行的压缩线程之间共享。写入空数据库时,可以使用全磁盘带宽进行初始写入,但数据库越大,压缩所需的磁盘带宽就越多。
如果写入吞吐量很高,并且压缩没有仔细配置,压缩跟不上写入速率。在这种情况下,磁盘上未合并段的数量不断增加,直到磁盘空间用完,读取速度也会减慢,因为它们需要检查更多段文件。通常情况下,即使压缩无法跟上,基于SSTable的存储引擎也不会限制传入写入的速率,所以您需要进行明确的监控来检测这种情况【29,30】。
B树的优点:
B树的一个优点是每个键只存在于索引中的一个位置,而日志结构化的存储引擎可能在不同的段中有相同键的多个副本。这个方面使得B树在想要提供强大的事务语义的数据库中很有吸引力:在许多关系数据库中,事务隔离是通过在键范围上使用锁来实现的,在B树索引中,这些锁可以直接连接到树【5】。在第7章中,我们将更详细地讨论这一点。
B树在数据库体系结构中是非常根深蒂固的,为许多工作负载提供始终如一的良好性能,所以它们不可能很快就会消失。在新的数据存储中,日志结构化索引变得越来越流行。没有快速和容易的规则来确定哪种类型的存储引擎对你的场景更好,所以值得进行一些经验上的测试。
聚簇索引(聚集索引,clustered index), 非聚集索引(nonclustered index), 覆盖索引(covering index)
在某些情况下,从索引到堆文件的额外跳跃对读取来说性能损失太大,因此可能希望将索引行直接存储在索引中。这被称为聚集索引。例如,在MySQL的InnoDB存储引擎中,表的主键总是一个聚簇索引,二级索引用主键(而不是堆文件中的位置)【31】。在SQL Server中,可以为每个表指定一个聚簇索引【32】。
在 聚集索引(clustered index)(在索引中存储所有行数据)和非聚集索引(nonclustered index)(仅在索引中存储对数据的引用)之间的折衷被称为包含列的索引(index with included columns) 或 覆盖索引(covering index),其存储表的一部分在索引内【33】。这允许通过单独使用索引来回答一些查询(这种情况叫做:索引覆盖(cover)了查询)【32】。 与任何类型的数据重复一样,聚簇和覆盖索引可以加快读取速度,但是它们需要额外的存储空间,并且会增加写入开销。数据库还需要额外的努力来执行事务保证,因为应用程序不应该因为重复而导致不一致。
与任何类型的数据重复一样,聚簇和覆盖索引可以加快读取速度,但是它们需要额外的存储空间,并且会增加写入开销。数据库还需要额外的努力来执行事务保证,因为应用程序不应该因为重复而导致不一致。
多维索引(multi-dimensional index)
多维索引(multi-dimensional index)是一种查询多个列的更一般的方法,这对于地理空间数据尤为重要。例如,餐厅搜索网站可能有一个数据库,其中包含每个餐厅的经度和纬度。当用户在地图上查看餐馆时,网站需要搜索用户正在查看的矩形地图区域内的所有餐馆。这需要一个二维范围查询,如下所示:
SELECT * FROM restaurants WHERE latitude > 51.4946 AND latitude < 51.5079 AND longitude > -0.1162 AND longitude < -0.1004;
一个标准的B树或者LSM树索引不能够高效地响应这种查询:它可以返回一个纬度范围内的所有餐馆(但经度可能是任意值),或者返回在同一个经度范围内的所有餐馆(但纬度可能是北极和南极之间的任意地方),但不能同时满足。
一种选择是使用空间填充曲线将二维位置转换为单个数字,然后使用常规B树索引【34】。更普遍的是,使用特殊化的空间索引,例如R树。例如,PostGIS使用PostgreSQL的通用Gist工具【35】将地理空间索引实现为R树。这里我们没有足够的地方来描述R树,但是有大量的文献可供参考。
内存数据库的优势:1. 减少序列化和反序列化的开销 2. 支持更加适合内存内表示的数据结构
诸如VoltDB,MemSQL和Oracle TimesTen等产品是具有关系模型的内存数据库,供应商声称,通过消除与管理磁盘上的数据结构相关的所有开销,他们可以提供巨大的性能改进【41,42】。 RAM Cloud是一个开源的内存键值存储器,具有持久性(对存储器中的数据以及磁盘上的数据使用日志结构化方法)【43】。 Redis和Couchbase通过异步写入磁盘提供了较弱的持久性。
反直觉的是,内存数据库的性能优势并不是因为它们不需要从磁盘读取的事实。即使是基于磁盘的存储引擎也可能永远不需要从磁盘读取,因为操作系统缓存最近在内存中使用了磁盘块。相反,它们更快的原因在于省去了将内存数据结构编码为磁盘数据结构的开销。【44】。
除了性能,内存数据库的另一个有趣的领域是提供难以用基于磁盘的索引实现的数据模型。例如,Redis为各种数据结构(如优先级队列和集合)提供了类似数据库的接口。因为它将所有数据保存在内存中,所以它的实现相对简单。
OLTP vs. OLAP
属性 事务处理 OLTP 分析系统 OLAP 主要读取模式 查询少量记录,按键读取 在大批量记录上聚合 主要写入模式 随机访问,写入要求低延时 批量导入(ETL),事件流 主要用户 终端用户,通过Web应用 内部数据分析师,决策支持 处理的数据 数据的最新状态(当前时间点) 随时间推移的历史事件 数据集尺寸 GB ~ TB TB ~ PB 起初,相同的数据库用于事务处理和分析查询。 SQL在这方面证明是非常灵活的:对于OLTP类型的查询以及OLAP类型的查询来说效果很好。尽管如此,在二十世纪八十年代末和九十年代初期,公司有停止使用OLTP系统进行分析的趋势,而是在单独的数据库上运行分析。这个单独的数据库被称为数据仓库(data warehourse)
表面上,一个数据仓库和一个关系OLTP数据库看起来很相似,因为它们都有一个SQL查询接口。然而,系统的内部看起来可能完全不同,因为它们针对非常不同的查询模式进行了优化。现在许多数据库供应商都将重点放在支持事务处理或分析工作负载上,而不是两者都支持。
Chapter4 编码与演化
这章主要讨论数据通信以及序列化。encode/decode方面举例了json, xml, protobuf, thrift, avro. 在数据通信基本有三种方式:1. database 2. rpc 3. message queue. 里面介绍了Avro的设计和实现,并且分析了优缺点,我觉得这个序列化实现还挺不错的。
语言内置编码的安全隐患
为了恢复相同对象类型的数据,解码过程需要实例化任意类的能力,这通常是安全问题的一个来源【5】:如果攻击者可以让应用程序解码任意的字节序列,他们就能实例化任意的类,这会允许他们做可怕的事情,如远程执行任意代码【6,7】。
Avro Schema兼容的使用场景
到目前为止,我们已经讨论了一个重要的问题:读者如何知道作者的模式是哪一部分数据被编码的?我们不能只将整个模式包括在每个记录中,因为模式可能比编码的数据大得多,从而使二进制编码节省的所有空间都是徒劳的。 答案取决于Avro使用的上下文。举几个例子:
- 有很多记录的大文件. Avro的一个常见用途 - 尤其是在Hadoop环境中 - 用于存储包含数百万条记录的大文件,所有记录都使用相同的模式进行编码。 (我们将在第10章讨论这种情况。)在这种情况下,该文件的作者可以在文件的开头只包含一次作者的模式。 Avro指定一个文件格式(对象容器文件)来做到这一点。
- 支持独立写入的记录的数据库 在一个数据库中,不同的记录可能会在不同的时间点使用不同的作者的模式编写 - 你不能假定所有的记录都有相同的模式。最简单的解决方案是在每个编码记录的开始处包含一个版本号,并在数据库中保留一个模式版本列表。读者可以获取记录,提取版本号,然后从数据库中获取该版本号的作者模式。使用该作者的模式,它可以解码记录的其余部分。(例如Espresso 【23】就是这样工作的。)
- 通过网络连接发送记录 当两个进程通过双向网络连接进行通信时,他们可以在连接设置上协商模式版本,然后在连接的生命周期中使用该模式。 Avro RPC协议(参阅“通过服务的数据流:REST和RPC”)如此工作。
Avro Schema支持动态生成带来的灵活性:可以按照字段名称进行匹配,而不用维护字段名称到字段标签的映射(which is error-prone and non-automatic).
与Protocol Buffers和Thrift相比,Avro方法的一个优点是架构不包含任何标签号码。但为什么这很重要?在模式中保留一些数字有什么问题?
不同之处在于Avro对动态生成的模式更友善。例如,假如你有一个关系数据库,你想要把它的内容转储到一个文件中,并且你想使用二进制格式来避免前面提到的文本格式(JSON,CSV,SQL)的问题。如果你使用Avro,你可以很容易地从关系模式生成一个Avro模式(在我们之前看到的JSON表示中),并使用该模式对数据库内容进行编码,并将其全部转储到Avro对象容器文件【25】中。您为每个数据库表生成一个记录模式,每个列成为该记录中的一个字段。数据库中的列名称映射到Avro中的字段名称。
现在,如果数据库模式发生变化(例如,一个表中添加了一列,删除了一列),则可以从更新的数据库模式生成新的Avro模式,并在新的Avro模式中导出数据。数据导出过程不需要注意模式的改变 - 每次运行时都可以简单地进行模式转换。任何读取新数据文件的人都会看到记录的字段已经改变,但是由于字段是通过名字来标识的,所以更新的作者的模式仍然可以与旧的读者模式匹配。
相比之下,如果您为此使用Thrift或Protocol Buffers,则字段标记可能必须手动分配:每次数据库模式更改时,管理员都必须手动更新从数据库列名到字段标签。 (这可能会自动化,但模式生成器必须非常小心,不要分配以前使用的字段标记。)这种动态生成的模式根本不是Thrift或Protocol Buffers的设计目标,而是为Avro。
RESTful API vs. RPC
使用二进制编码格式的自定义RPC协议可以实现比通用的JSON over REST更好的性能。但是,RESTful API还有其他一些显着的优点:对于实验和调试(只需使用Web浏览器或命令行工具curl,无需任何代码生成或软件安装即可向其请求),它是受支持的所有的主流编程语言和平台,还有大量可用的工具(服务器,缓存,负载平衡器,代理,防火墙,监控,调试工具,测试工具等)的生态系统。由于这些原因,REST似乎是公共API的主要风格。 RPC框架的主要重点在于同一组织拥有的服务之间的请求,通常在同一数据中心内。
Chapter5 复制
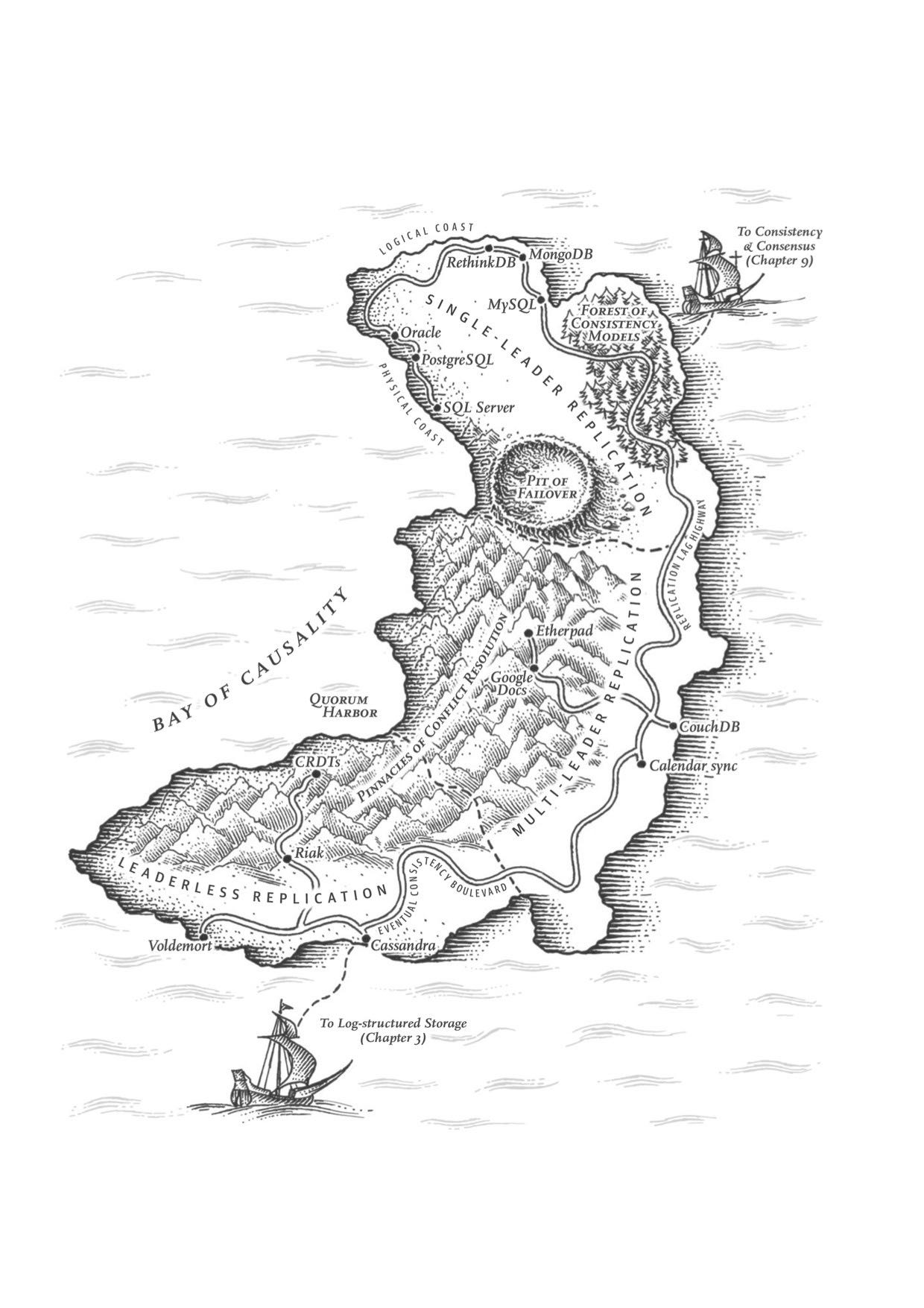
这章讨论replication的各种问题:single-leader/multi-leader/leaderless, sync/async/semi-async, replication log impl(stmt-based, wal, logical record, physical record), consistency(eventual, read-after-write/session, monotonic reads, consistent prefix reads/一致前缀读, strong)
基于语句复制(确定性函数,不存在副作用),基于WAL复制(和存储引擎绑定紧密),逻辑日志
基于语句的复制在5.1版本前的MySQL中使用。因为它相当紧凑,现在有时候也还在用。但现在在默认情况下,如果语句中存在任何不确定性,MySQL会切换到基于行的复制(稍后讨论)。 VoltDB使用了基于语句的复制,但要求事务必须是确定性的,以此来保证安全【15】。
(WAL复制) PostgreSQL和Oracle等使用这种复制方法【16】。主要缺点是日志记录的数据非常底层:WAL包含哪些磁盘块中的哪些字节发生了更改。这使复制与存储引擎紧密耦合。如果数据库将其存储格式从一个版本更改为另一个版本,通常不可能在主库和从库上运行不同版本的数据库软件。 看上去这可能只是一个微小的实现细节,但却可能对运维产生巨大的影响。如果复制协议允许从库使用比主库更新的软件版本,则可以先升级从库,然后执行故障切换,使升级后的节点之一成为新的主库,从而执行数据库软件的零停机升级。如果复制协议不允许版本不匹配(传输WAL经常出现这种情况),则此类升级需要停机。
(逻辑日志) 由于逻辑日志与存储引擎内部分离,因此可以更容易地保持向后兼容,从而使领导者和跟随者能够运行不同版本的数据库软件甚至不同的存储引擎。
对于外部应用程序来说,逻辑日志格式也更容易解析。如果要将数据库的内容发送到外部系统(如数据),这一点很有用,例如复制到数据仓库进行离线分析,或建立自定义索引和缓存【18】。 这种技术被称为捕获数据变更(change data capture),第11章将重新讲到它。
社交网络场景使用主从库的一个逻辑判断:看自己的信息用主库,看别人的信息用从库
读用户可能已经修改过的内容时,都从主库读;这就要求有一些方法,不用实际查询就可以知道用户是否修改了某些东西。举个例子,社交网络上的用户个人资料信息通常只能由用户本人编辑,而不能由其他人编辑。因此一个简单的规则是:从主库读取用户自己的档案,在从库读取其他用户的档案。
单调读(monotonic reads): 多次读取的值不能出现时间回退。用户在一个时间点看到数据后,他们不应该在某个早期时间点看到数据。
单调读(Monotonic reads)【23】是这种异常不会发生的保证。这是一个比强一致性(strong consistency)更弱,但比最终一致性(eventually consistency)更强的保证。当读取数据时,您可能会看到一个旧值;单调读取仅意味着如果一个用户顺序地进行多次读取,则他们不会看到时间后退,即,如果先前读取到较新的数据,后续读取不会得到更旧的数据。
实现单调读取的一种方式是确保每个用户总是从同一个副本进行读取(不同的用户可以从不同的副本读取)。例如,可以基于用户ID的散列来选择副本,而不是随机选择副本。但是,如果该副本失败,用户的查询将需要重新路由到另一个副本。
一致性读取确保读取的结果满足一定的因果性。用户应该将数据视为具有因果意义的状态:例如,按照正确的顺序查看问题及其答复。
第三个复制延迟例子违反了因果律。 想象一下Poons先生和Cake夫人之间的以下简短对话:
- Mr. Poons: Mrs. Cake,你能看到多远的未来?
- Mrs. Cake: 通常约十秒钟,Mr. Poons.
这两句话之间有因果关系:Cake夫人听到了Poons先生的问题并回答了这个问题。
现在,想象第三个人正在通过从库来听这个对话。 Cake夫人说的内容是从一个延迟很低的从库读取的,但Poons先生所说的内容,从库的延迟要大的多(见图5-5)。于是,这个观察者会听到以下内容:
- Mrs. Cake 通常约十秒钟,Mr. Poons.
- Mr. Poons Mrs. Cake,你能看到多远的未来?
对于观察者来说,看起来好像Cake夫人在Poons先生发问前就回答了这个问题。 这种超能力让人印象深刻,但也会把人搞糊涂。【25】。
防止这种异常,需要另一种类型的保证:一致前缀读(consistent prefix reads)【23】。 这个保证说:如果一系列写入按某个顺序发生,那么任何人读取这些写入时,也会看见它们以同样的顺序出现。
这是分区(partitioned) ( 分片(sharded))数据库中的一个特殊问题,将在第6章中讨论。如果数据库总是以相同的顺序应用写入,则读取总是会看到一致的前缀,所以这种异常不会发生。但是在许多分布式数据库中,不同的分区独立运行,因此不存在全局写入顺序:当用户从数据库中读取数据时,可能会看到数据库的某些部分处于较旧的状态,而某些处于较新的状态。
一种解决方案是,确保任何因果相关的写入都写入相同的分区。对于某些无法高效完成这种操作的应用,还有一些显式跟踪因果依赖关系的算法,本书将在“关系与并发”一节中返回这个主题。
因果性和并发问题:如果两个操作之间存在因果性,那么这两个操作就存在顺序问题,否则两个操作之间就是并发的。
“此前发生”的关系和并发 我们如何判断两个操作是否是并发的?为了建立一个直觉,让我们看看一些例子:
- 在 图5-9中,两个写入不是并发的:A的插入发生在B的增量之前,因为B递增的值是A插入的值。换句话说,B的操作建立在A的操作上,所以B的操作必须有后来发生。我们也可以说B是因果依赖(causally dependent) 于A
- 另一方面,图5-12中的两个写入是并发的:当每个客户端启动操作时,它不知道另一个客户端也正在执行操作同样的Key。因此,操作之间不存在因果关系。
如果操作B了解操作A,或者依赖于A,或者以某种方式构建于操作A之上,则操作A在另一个操作B之前发生。在另一个操作之前是否发生一个操作是定义什么并发的关键。事实上,我们可以简单地说,如果两个操作都不在另一个之前发生,那么两个操作是并发的(即,两个操作都不知道另一个)【54】。
因此,只要有两个操作A和B,就有三种可能性:A在B之前发生,或者B在A之前发生,或者A和B并发。我们需要的是一个算法来告诉我们两个操作是否是并发的。如果一个操作发生在另一个操作之前,则后面的操作应该覆盖较早的操作,但是如果这些操作是并发的,则存在需要解决的冲突。
CRDT这种数据结构可以安全有效地实现冲突合并
因为在应用程序代码中合并兄弟是复杂且容易出错的,所以有一些数据结构被设计出来用于自动执行这种合并,如“自动冲突解决”中讨论的。例如,Riak的数据类型支持使用称为CRDT的数据结构家族【38,39,55】可以以合理的方式自动合并兄弟,包括保留删除。
Chapter6 分区
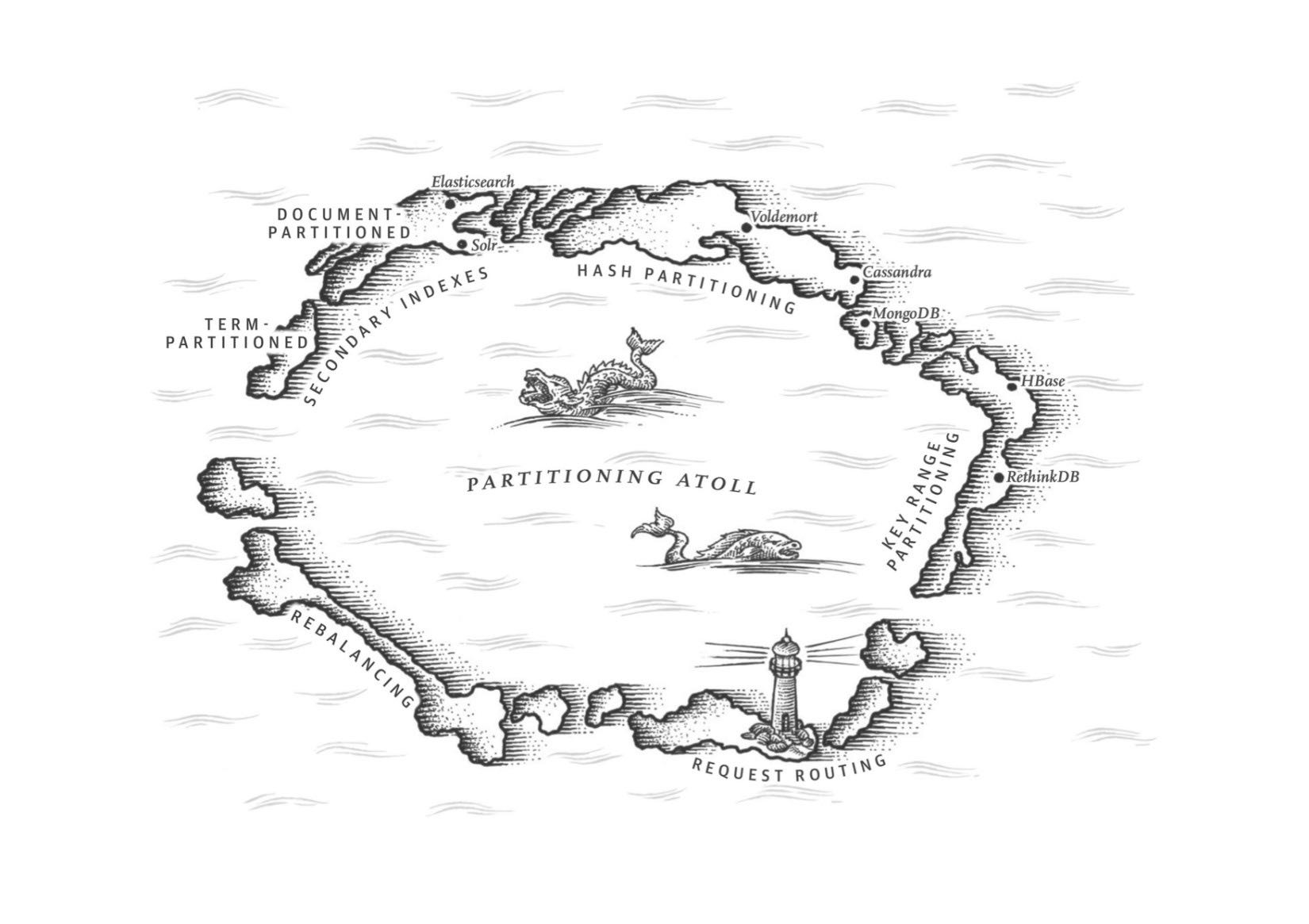
这章主要讨论partition的各种问题:primary index, global vs local secondary index. secondary index最大的问题是没有办法和partitioning关联起来,所以导致要不在每个partition上做index, 要不就在做个global index(索引相当于是一个新的数据库)
几种确定分区数量的办法:1. 动态分区 2. 固定数量的分区(通常几倍于当前节点的数量,做分区到节点映射) 3. 和节点数量正比的分区数量(虚拟节点和一致性哈希)
通过动态分区,分区的数量与数据集的大小成正比,因为拆分和合并过程将每个分区的大小保持在固定的最小值和最大值之间。另一方面,对于固定数量的分区,每个分区的大小与数据集的大小成正比。在这两种情况下,分区的数量都与节点的数量无关。
Cassandra和Ketama使用的第三种方法是使分区数与节点数成正比——换句话说,每个节点具有固定数量的分区【23,27,28】。在这种情况下,每个分区的大小与数据集大小成比例地增长,而节点数量保持不变,但是当增加节点数时,分区将再次变小。由于较大的数据量通常需要较大数量的节点进行存储,因此这种方法也使每个分区的大小较为稳定。
运维:手动还是自动平衡
关于再平衡有一个重要问题:自动还是手动进行? 在全自动重新平衡(系统自动决定何时将分区从一个节点移动到另一个节点,无须人工干预)和完全手动(分区指派给节点由管理员明确配置,仅在管理员明确重新配置时才会更改)之间有一个权衡。例如,Couchbase,Riak和Voldemort会自动生成建议的分区分配,但需要管理员提交才能生效。
全自动重新平衡可以很方便,因为正常维护的操作工作较少。但是,这可能是不可预测的。再平衡是一个昂贵的操作,因为它需要重新路由请求并将大量数据从一个节点移动到另一个节点。如果没有做好,这个过程可能会使网络或节点负载过重,降低其他请求的性能。
这种自动化与自动故障检测相结合可能十分危险。例如,假设一个节点过载,并且对请求的响应暂时很慢。其他节点得出结论:过载的节点已经死亡,并自动重新平衡集群,使负载离开它。这会对已经超负荷的节点,其他节点和网络造成额外的负载,从而使情况变得更糟,并可能导致级联失败。
出于这个原因,再平衡的过程中有人参与是一件好事。这比完全自动的过程慢,但可以帮助防止运维意外。
Chapter7 事务
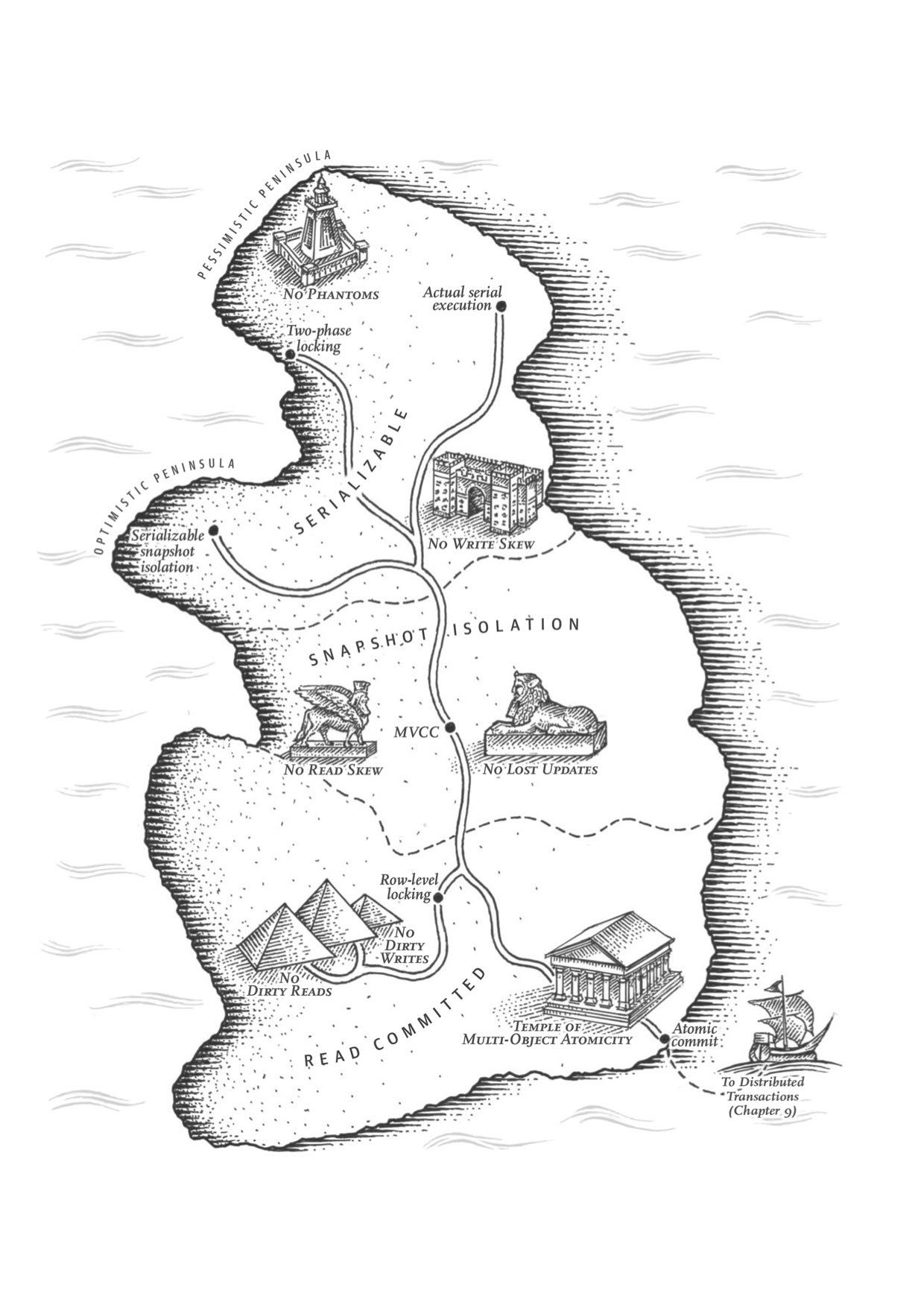
这章讨论事务方面的问题:ACID的真实含义,事务的原子性,以及事务的隔离性。如何实现Read-Committed, Repeatable-Read, 如何避免lost updates(避免写丢失), write skew and phantom read, 如何实现最高隔离性serializable(actual serial execution, two phase locking and SSI)
ACID其实主体只有原子性,事务隔离性,持久性,这三个概念是数据库的属性,而一致性是应用程序的概念(应用程序保证数据上是一致的,数据库不用管理这点)
To recap, in ACID, atomicity and isolation describe what the database should do if a client makes several writes within the same transaction:
- Atomicity. If an error occurs halfway through a sequence of writes, the transaction should be aborted, and the writes made up to that point should be discarded. In other words, the database saves you from having to worry about partial failure, by giving an all-or-nothing guarantee.
- Isolation. Concurrently running transactions shouldn't interfere with each other. For example, if one transaction makes several writes, then another transaction should see either all or none of those writes, but not some subset.
ACID的各个字符的含义:一致性其实不属于数据库概念,持久性只需要数据库正确保存到磁盘即可,原子性可以通过redo log来实现,所以后面主要讨论的就是事务隔离性。
ACID原子性的定义特征是:能够在错误时中止事务,丢弃该事务进行的所有写入变更的能力。 或许 可中止性(abortability) 是更好的术语,但本书将继续使用原子性,因为这是惯用词。
ACID一致性的概念是,对数据的一组特定陈述必须始终成立。即不变量(invariants)。例如,在会计系统中,所有账户整体上必须借贷相抵。如果一个事务开始于一个满足这些不变量的有效数据库,且在事务处理期间的任何写入操作都保持这种有效性,那么可以确定,不变量总是满足的。
但是,一致性的这种概念取决于应用程序对不变量的观念,应用程序负责正确定义它的事务,并保持一致性。这并不是数据库可以保证的事情:如果你写入违反不变量的脏数据,数据库也无法阻止你。所以原子性,隔离性和持久性是数据库的属性,而一致性(在ACID意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母C不属于ACID.
ACID意义上的隔离性意味着,同时执行的事务是相互隔离的:它们不能相互冒犯。传统的数据库教科书将隔离性形式化为可序列化(Serializability),这意味着每个事务可以假装它是唯一在整个数据库上运行的事务。数据库确保当事务已经提交时,结果与它们按顺序运行(一个接一个)是一样的,尽管实际上它们可能是并发运行的【10】。
数据库系统的目的是,提供一个安全的地方存储数据,而不用担心丢失。持久性是一个承诺,即一旦事务成功完成,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。如“可靠性”一节所述,完美的持久性是不存在的 :如果所有硬盘和所有备份同时被销毁,那显然没有任何数据库能救得了你。
读已提交隔离级别(read committed):防止脏写可以使用行级锁实现,防止脏读也可以使用锁但是这样会增加冲突,另外一个办法是保存旧值,只有当其他事务提交之后才更新该值。
最基本的事务隔离级别是读已提交(Read Committed)v,它提供了两个保证:
- 从数据库读时,只能看到已提交的数据(没有脏读(dirty reads))。(如果更新多个对象的话,可能会看到部分更新;或者是如果其他事务写回滚的话,会看到实际从未提交给数据库的数据)
- 写入数据库时,只会覆盖已经写入的数据(没有脏写(dirty writes))(如果两个事务更新同一个对象的话,那么第二个事务的更新必须等待第一个事务更新完成才能写入。否则如果两个事务更新A,B的话,那么最终的A,B值可能是不一致的)
读已提交是一个非常流行的隔离级别。这是Oracle 11g,PostgreSQL,SQL Server 2012,MemSQL和其他许多数据库的默认设置【8】。 最常见的情况是,数据库通过使用行锁(row-level lock) 来防止脏写:当事务想要修改特定对象(行或文档)时,它必须首先获得该对象的锁。然后必须持有该锁直到事务被提交或中止。一次只有一个事务可持有任何给定对象的锁;如果另一个事务要写入同一个对象,则必须等到第一个事务提交或中止后,才能获取该锁并继续。这种锁定是读已提交模式(或更强的隔离级别)的数据库自动完成的。
如何防止脏读?一种选择是使用相同的锁,并要求任何想要读取对象的事务来简单地获取该锁,然后在读取之后立即再次释放该锁。这能确保不会读取进行时,对象不会在脏的状态,有未提交的值(因为在那段时间锁会被写入该对象的事务持有)。
但是要求读锁的办法在实践中效果并不好。因为一个长时间运行的写入事务会迫使许多只读事务等到这个慢写入事务完成。这会损失只读事务的响应时间,并且不利于可操作性:因为等待锁,应用某个部分的迟缓可能由于连锁效应,导致其他部分出现问题。
出于这个原因,大多数数据库使用图7-4的方式防止脏读:对于写入的每个对象,数据库都会记住旧的已提交值,和由当前持有写入锁的事务设置的新值。 当事务正在进行时,任何其他读取对象的事务都会拿到旧值。 只有当新值提交后,事务才会切换到读取新值。
快照隔离(snapshot isolation)和可重复读(repeatable read): 在一个事务内触发多次读取返回相同的值。使用MVCC技术实现快照隔离,每个对象存在多个版本。对RR隔离级别来说,在一个事务期间只能看到这个对象某个版本之前已经提交的值。
快照隔离(snapshot isolation)【28】是这个问题最常见的解决方案。想法是,每个事务都从数据库的一致快照(consistent snapshot) 中读取——也就是说,事务可以看到事务开始时在数据库中提交的所有数据。即使这些数据随后被另一个事务更改,每个事务也只能看到该特定时间点的旧数据。
快照隔离对长时间运行的只读查询(如备份和分析)非常有用。如果查询的数据在查询执行的同时发生变化,则很难理解查询的含义。当一个事务可以看到数据库在某个特定时间点冻结时的一致快照,理解起来就很容易了。
快照隔离是一个流行的功能:PostgreSQL,使用InnoDB引擎的MySQL,Oracle,SQL Server等都支持【23,31,32】。
为了实现快照隔离,数据库使用了我们看到的用于防止图7-4中的脏读的机制的一般化。数据库必须可能保留一个对象的几个不同的提交版本,因为各种正在进行的事务可能需要看到数据库在不同的时间点的状态。因为它并排维护着多个版本的对象,所以这种技术被称为多版本并发控制(MVCC, multi-version concurrentcy control) 。
如果一个数据库只需要提供读已提交的隔离级别,而不提供快照隔离,那么保留一个对象的两个版本就足够了:提交的版本和被覆盖但尚未提交的版本。支持快照隔离的存储引擎通常也使用MVCC来实现读已提交隔离级别。一种典型的方法是读已提交为每个查询使用单独的快照,而快照隔离对整个事务使用相同的快照。
防止丢失更新(lost update): 读已经提交级别里面虽然防止了脏写,但是并没有防止事务的写丢失(一个事务吧另外一个事务的修改覆盖了)。一旦发现可能出现丢失更新的话,那么要立刻终止事务。 有三种方法来防止丢失更新:1. 原子操作(CAS) 2. 显式锁定(select … for update) 3. 自动检测丢失的更新。
原子操作和锁是通过强制读取-修改-写入序列按顺序发生,来防止丢失更新的方法。另一种方法是允许它们并行执行,如果事务管理器检测到丢失更新,则中止事务并强制它们重试其读取-修改-写入序列。
这种方法的一个优点是,数据库可以结合快照隔离高效地执行此检查。事实上,PostgreSQL的可重复读,Oracle的可串行化和SQL Server的快照隔离级别,都会自动检测到丢失更新,并中止惹麻烦的事务。但是,MySQL/InnoDB的可重复读并不会检测丢失更新【23】。一些作者【28,30】认为,数据库必须能防止丢失更新才称得上是提供了快照隔离,所以在这个定义下,MySQL下不提供快照隔离。
丢失更新检测是一个很好的功能,因为它不需要应用代码使用任何特殊的数据库功能,你可能会忘记使用锁或原子操作,从而引入错误;但丢失更新的检测是自动发生的,因此不太容易出错。
写入偏差(write skew)和幻读(phantom read). 写入偏差与丢失更新不同:写入偏差是更新两个不同对象,而丢失更新是更新同一个对象。 写入偏差的根本原始是因为,在读取-修改-写入这个序列中,写入的数据和读取的数据存在某种一致性。如果在写入的时候,读取的数据和之前假设不同的话,那么就会出现写入偏差。
这种异常称为写偏差【28】。它既不是脏写,也不是丢失更新,因为这两个事务正在更新两个不同的对象(Alice和Bob各自的待命记录)。在这里发生的冲突并不是那么明显,但是这显然是一个竞争条件:如果两个事务一个接一个地运行,那么第二个医生就不能歇班了。异常行为只有在事务并发进行时才有可能。
可以将写入偏差视为丢失更新问题的一般化。如果两个事务读取相同的对象,然后更新其中一些对象(不同的事务可能更新不同的对象),则可能发生写入偏差。在多个事务更新同一个对象的特殊情况下,就会发生脏写或丢失更新(取决于时机)。
这种效应:一个事务中的写入改变另一个事务的搜索查询的结果,被称为幻读【3】。快照隔离避免了只读查询中幻读,但是在像我们讨论的例子那样的读写事务中,幻影会导致特别棘手的写歪斜情况。
可序列化(serializability)隔离和实几种实现方式
可序列化(Serializability)隔离通常被认为是最强的隔离级别。它保证即使事务可以并行执行,最终的结果也是一样的,就好像它们没有任何并发性,连续挨个执行一样。因此数据库保证,如果事务在单独运行时正常运行,则它们在并发运行时继续保持正确—— 换句话说,数据库可以防止所有可能的竞争条件。 但如果可序列化隔离级别比弱隔离级别的烂摊子要好得多,那为什么没有人见人爱?为了回答这个问题,我们需要看看实现可序列化的选项,以及它们如何执行。目前大多数提供可序列化的数据库都使用了三种技术之一,本章的剩余部分将会介绍这些技术。
- 字面意义上地串行顺序执行事务(参见“真的串行执行”)
- 两相锁定(2PL, two-phase locking),几十年来唯一可行的选择。(参见“两相锁定(2PL)”)
- 乐观并发控制技术,例如可序列化的快照隔离(serializable snapshot isolation)(参阅“可序列化的快照隔离(SSI)”
两阶段锁定(2PL, two-phase locking)的原理和实现
大约30年来,在数据库中只有一种广泛使用的序列化算法:两阶段锁定(2PL,two-phase locking)
两阶段锁定定类似,但使锁的要求更强。只要没有写入,就允许多个事务同时读取同一个对象。但对象只要有写入(修改或删除),就需要独占访问(exclusive access) 权限:
- 如果事务A读取了一个对象,并且事务B想要写入该对象,那么B必须等到A提交或中止才能继续。 (这确保B不能在A底下意外地改变对象。)
- 如果事务A写入了一个对象,并且事务B想要读取该对象,则B必须等到A提交或中止才能继续。
在2PL中,写入不仅会阻塞其他写入,也会阻塞读,反之亦然。快照隔离使得读不阻塞写,写也不阻塞读(参阅“实现快照隔离”),这是2PL和快照隔离之间的关键区别。另一方面,因为2PL提供了可序列化的性质,它可以防止早先讨论的所有竞争条件,包括丢失更新和写入偏差。
2PL用于MySQL(InnoDB)和SQL Server中的可序列化隔离级别,以及DB2中的可重复读隔离级别【23,36】。
读与写的阻塞是通过为数据库中每个对象添加锁来实现的。锁可以处于共享模式(shared mode) 或 独占模式(exclusive mode)。锁使用如下:
- 若事务要读取对象,则须先以共享模式获取锁。允许多个事务同时持有共享锁。但如果另一个事务已经在对象上持有排它锁,则这些事务必须等待。
- 若事务要写入一个对象,它必须首先以独占模式获取该锁。没有其他事务可以同时持有锁(无论是共享模式还是独占模式),所以如果对象上存在任何锁,该事务必须等待。
- 如果事务先读取再写入对象,则它可能会将其共享锁升级为独占锁。升级锁的工作与直接获得排他锁相同。
- 事务获得锁之后,必须继续持有锁直到事务结束(提交或中止)。就是“两阶段”这个名字的来源:第一阶段(当事务正在执行时)获取锁,第二阶段(在事务结束时)释放所有的锁。
由于使用了这么多的锁,因此很可能会发生:事务A等待事务B释放它的锁,反之亦然。这种情况叫做死锁(Deadlock)。数据库会自动检测事务之间的死锁,并中止其中一个,以便另一个继续执行。被中止的事务需要由应用程序重试。
两阶段锁定2PL的性能问题集中在锁冲突导致的事务等待,回滚和重试上。
两阶段锁定的巨大缺点,以及70年代以来没有被所有人使用的原因,是其性能问题。两阶段锁定下的事务吞吐量与查询响应时间要比弱隔离级别下要差得多。
这一部分是由于获取和释放所有这些锁的开销,但更重要的是由于并发性的降低。按照设计,如果两个并发事务试图做任何可能导致竞争条件的事情,那么必须等待另一个完成。
因此,运行2PL的数据库可能具有相当不稳定的延迟,如果在工作负载中存在争用,那么可能高百分位点处的响应会非常的慢(参阅“描述性能”)。可能只需要一个缓慢的事务,或者一个访问大量数据并获取许多锁的事务,就能把系统的其他部分拖慢,甚至迫使系统停机。当需要稳健的操作时,这种不稳定性是有问题的。
基于锁实现的读已提交隔离级别可能发生死锁,但在基于2PL实现的可序列化隔离级别中,它们会出现的频繁的多(取决于事务的访问模式)。这可能是一个额外的性能问题:当事务由于死锁而被中止并被重试时,它需要从头重做它的工作。如果死锁很频繁,这可能意味着巨大的浪费。
因为2PL的性能问题,提出了另外几种锁定方式:1. 谓词锁(predicate lock) 2. 索引范围锁/间隙所(next-key locking) 3. 序列化快照隔离(ssi, 从名字上看就是快照隔离的优化版本,支持序列化隔离保证)
- 谓词锁是查询条件的对应数据集合的锁,凡是可能改变这个数据集合的更新,都需要申请这个锁。
- 间隙锁是谓词锁的近似版本,只针对查询条件中的某几个索引加锁。间隙锁会多锁住某些对象,但是是安全的。
谓词锁限制访问,如下所示:
- 如果事务A想要读取匹配某些条件的对象,就像在这个 SELECT 查询中那样,它必须获取查询条件上的共享谓词锁(shared-mode predicate lock)。如果另一个事务B持有任何满足这一查询条件对象的排它锁,那么A必须等到B释放它的锁之后才允许进行查询。
- 如果事务A想要插入,更新或删除任何对象,则必须首先检查旧值或新值是否与任何现有的谓词锁匹配。如果事务B持有匹配的谓词锁,那么A必须等到B已经提交或中止后才能继续。
这里的关键思想是,谓词锁甚至适用于数据库中尚不存在,但将来可能会添加的对象(幻象)。如果两阶段锁定包含谓词锁,则数据库将阻止所有形式的写入偏差和其他竞争条件,因此其隔离实现了可串行化。
不幸的是谓词锁性能不佳:如果活跃事务持有很多锁,检查匹配的锁会非常耗时。因此,大多数使用2PL的数据库实际上实现了索引范围锁(也称为间隙锁(next-key locking)),这是一个简化的近似版谓词锁【41,50】。通过使谓词匹配到一个更大的集合来简化谓词锁是安全的。例如,如果你有在中午和下午1点之间预订123号房间的谓词锁,则锁定123号房间的所有时间段,或者锁定12:00~13:00时间段的所有房间(不只是123号房间)是一个安全的近似,因为任何满足原始谓词的写入也一定会满足这种更松散的近似。无论哪种方式,搜索条件的近似值都附加到其中一个索引上。现在,如果另一个事务想要插入,更新或删除同一个房间和/或重叠时间段的预订,则它将不得不更新索引的相同部分。在这样做的过程中,它会遇到共享锁,它将被迫等到锁被释放。
这种方法能够有效防止幻读和写入偏差。索引范围锁并不像谓词锁那样精确(它们可能会锁定更大范围的对象,而不是维持可串行化所必需的范围),但是由于它们的开销较低,所以是一个很好的折衷。 如果没有可以挂载间隙锁的索引,数据库可以退化到使用整个表上的共享锁。这对性能不利,因为它会阻止所有其他事务写入表格,但这是一个安全的回退位置。
关于序列化快照隔离(SSI)的原理
顾名思义,SSI基于快照隔离——也就是说,事务中的所有读取都是来自数据库的一致性快照(参见“快照隔离和可重复读取”)。与早期的乐观并发控制技术相比这是主要的区别。在快照隔离的基础上,SSI添加了一种算法来检测写入之间的序列化冲突,并确定要中止哪些事务。
先前讨论了快照隔离中的写入偏差(参阅“写入偏差和幻像”)时,我们观察到一个循环模式:事务从数据库读取一些数据,检查查询的结果,并根据它看到的结果决定采取一些操作(写入数据库)。但是,在快照隔离的情况下,原始查询的结果在事务提交时可能不再是最新的,因为数据可能在同一时间被修改。
数据库如何知道查询结果是否可能已经改变?有两种情况需要考虑:
- 检测对旧MVCC对象版本的读取(读之前存在未提交的写入)
- 检测影响先前读取的写入(读之后发生写入)
Chapter8 分布式系统的麻烦
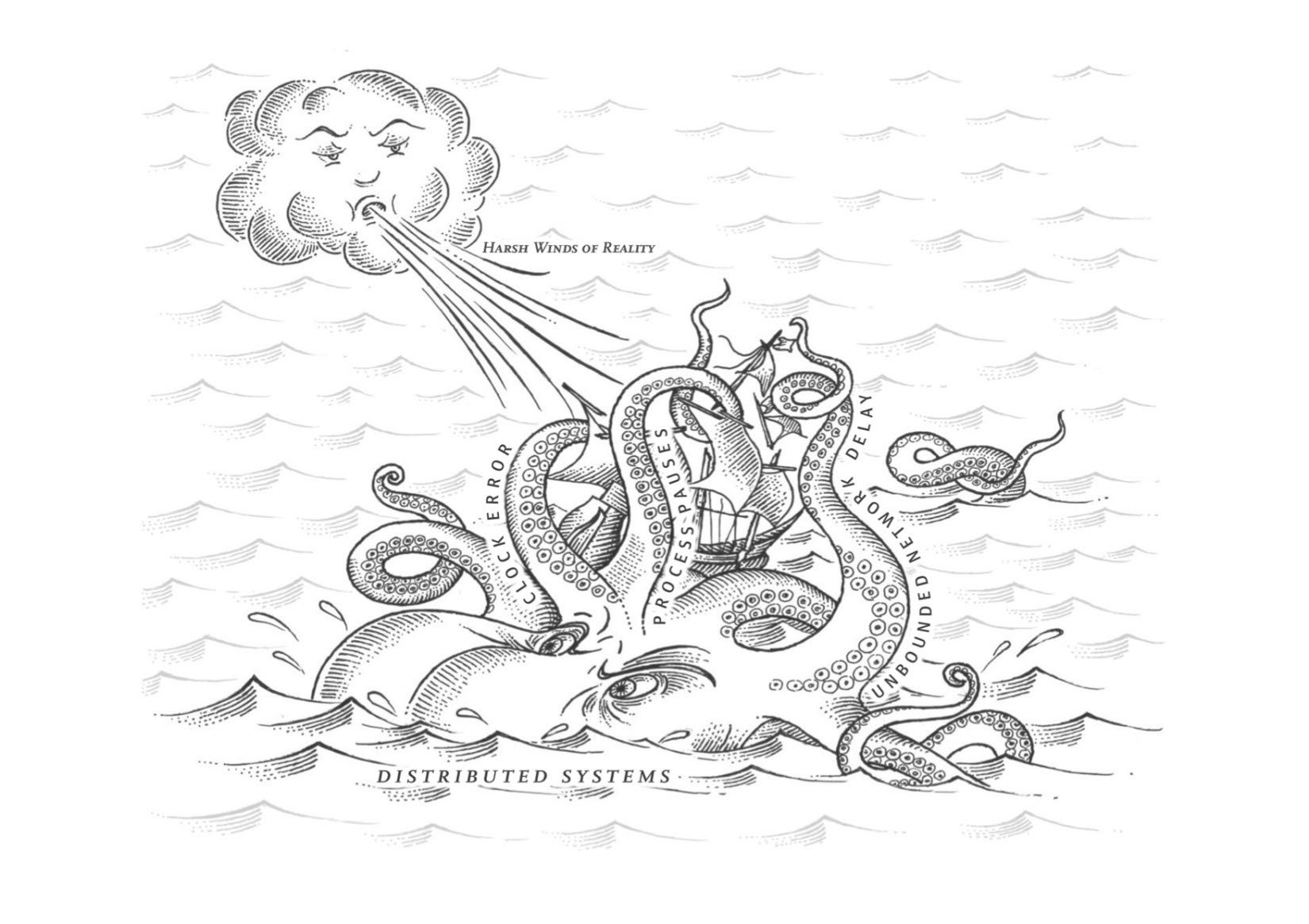
这章讨论了分布式系统里面几个和人们假设想去甚远的问题,比如网络延迟的不可控性,时钟的不可靠性,以及进程会被挂起很长时间,以及这些问题带来的新的问题和解决办法。大部分分布式系统可以不用考虑Byzantine问题,因为客户端和服务端都是可信的。
分布式系统需要容忍部分失效,并且这种部分失效是不确定性的。
单个计算机上的软件没有根本性的不可靠原因:当硬件正常工作时,相同的操作总是产生相同的结果(这是确定性的)。如果存在硬件问题(例如,内存损坏或连接器松动),其后果通常是整个系统故障(例如,内核恐慌,“蓝屏死机”,启动失败)。装有良好软件的个人计算机通常要么功能完好,要么完全失效,而不是介于两者之间。
这是计算机设计中的一个慎重的选择:如果发生内部错误,我们宁愿电脑完全崩溃,而不是返回错误的结果,因为错误的结果很难处理。因为计算机隐藏了模糊不清的物理实现,并呈现出一个理想化的系统模型,并以数学一样的完美的方式运作。 CPU指令总是做同样的事情;如果您将一些数据写入内存或磁盘,那么这些数据将保持不变,并且不会被随机破坏。从第一台数字计算机开始,始终正确地计算这个设计目标贯穿始终【3】。
当你编写运行在多台计算机上的软件时,情况有本质上的区别。在分布式系统中,我们不再处于理想化的系统模型中,我们别无选择,只能面对现实世界的混乱现实。而在现实世界中,各种各样的事情都可能会出现问题【4】,如下面的轶事所述:
在我有限的经验中,我已经和很多东西打过交道:单个数据中心(DC)中长期存在的网络分区,配电单元PDU故障,开关故障,整个机架意外的电源短路,全直流主干故障,全直流电源故障,以及一个低血糖的司机把他的福特皮卡撞碎在数据中心的HVAC(加热,通风和空气)系统上。而且我甚至不是一个运维。 ——柯达黑尔
在分布式系统中,尽管系统的其他部分工作正常,但系统的某些部分可能会以某种不可预知的方式被破坏。这被称为部分失效(partial failure)。难点在于部分失效是不确定性的(nonderterministic):如果你试图做任何涉及多个节点和网络的事情,它有时可能会工作,有时会出现不可预知的失败。正如我们将要看到的,你甚至不知道是否成功了,因为消息通过网络传播的时间也是不确定的!
这种不确定性和部分失效的可能性,使得分布式系统难以工作【5】。
构建大型计算系统有一系列的哲学,不同的哲学导致不同的故障处理方式。
关于如何构建大型计算系统有一系列的哲学:
- 规模的一端是高性能计算(HPC)领域。具有数千个CPU的超级计算机通常用于计算密集型科学计算任务,如天气预报或分子动力学(模拟原子和分子的运动)。
- 另一个极端是云计算(cloud computing),云计算并不是一个良好定义的概念【6】,但通常与多租户数据中心,连接IP网络的商品计算机(通常是以太网),弹性/按需资源分配以及计量计费等相关联。
- 传统企业数据中心位于这两个极端之间。
不同的哲学会导致不同的故障处理方式。在超级计算机中,作业通常会不时地会将计算的状态存盘到持久存储中。如果一个节点出现故障,通常的解决方案是简单地停止整个集群的工作负载。故障节点修复后,计算从上一个检查点重新开始【7,8】。因此,超级计算机更像是一个单节点计算机而不是分布式系统:通过让部分失败升级为完全失败来处理部分失败——如果系统的任何部分发生故障,只是让所有的东西都崩溃(就像单台机器上的内核恐慌一样)。
在本书中,我们将重点放在实现互联网服务的系统上,这些系统通常与超级计算机看起来有很大不同:
- 许多与互联网有关的应用程序都是在线(online)的,因为它们需要能够随时以低延迟服务用户。使服务不可用(例如,停止群集以进行修复)是不可接受的。相比之下,像天气模拟这样的离线(批处理)工作可以停止并重新启动,影响相当小。
- 超级计算机通常由专用硬件构建而成,每个节点相当可靠,节点通过共享内存和远程直接内存访问(RDMA)进行通信。另一方面,云服务中的节点是由商品机器构建而成的,由于规模经济,可以以较低的成本提供相同的性能,而且具有较高的故障率。
- 大型数据中心网络通常基于IP和以太网,以闭合拓扑排列,以提供更高的二等分带宽【9】。超级计算机通常使用专门的网络拓扑结构,例如多维网格和环面 【10】,这为具有已知通信模式的HPC工作负载提供了更好的性能。
- 如果系统可以容忍发生故障的节点,并继续保持整体工作状态,那么这对于操作和维护非常有用:例如,可以执行滚动升级(参阅第4章),一次重新启动一个节点,而服务继续服务用户不中断。在云环境中,如果一台虚拟机运行不佳,可以杀死它并请求一台新的虚拟机(希望新的虚拟机速度更快)。
- 在地理位置分散的部署中(保持数据在地理位置上接近用户以减少访问延迟),通信很可能通过互联网进行,与本地网络相比,通信速度缓慢且不可靠。超级计算机通常假设它们的所有节点都靠近在一起。
关于CPU单调钟(monotonic clock)以及使用单调钟而非NTP来做为超时依据。
在具有多个CPU插槽的服务器上,每个CPU可能有一个单独的计时器,但不一定与其他CPU同步。操作系统会补偿所有的差异,并尝试向应用线程表现出单调钟的样子,即使这些线程被调度到不同的CPU上。当然,明智的做法是不要太把这种单调性保证当回事【40】。
如果NTP协议检测到计算机的本地石英钟比NTP服务器要更快或更慢,则可以调整单调钟向前走的频率(这称为偏移(skewing)时钟)。默认情况下,NTP允许时钟速率增加或减慢最高至0.05%,但NTP不能使单调时钟向前或向后跳转。单调时钟的分辨率通常相当好:在大多数系统中,它们能在几微秒或更短的时间内测量时间间隔。
在分布式系统中,使用单调钟测量经过时间(elapsed time)(比如超时)通常很好,因为它不假定不同节点的时钟之间存在任何同步,并且对测量的轻微不准确性不敏感。
时钟的准确性是件很难保证的事情。为了达到要求的准确性需要投入大量资源。
计算机中的石英钟不够精确:它会漂移(drifts)(运行速度快于或慢于预期)。时钟漂移取决于机器的温度。 Google假设其服务器时钟漂移为200 ppm(百万分之一)【41】,相当于每30秒与服务器重新同步一次的时钟漂移为6毫秒,或者每天重新同步的时钟漂移为17秒。即使一切工作正常,此漂移也会限制可以达到的最佳准确度。
在虚拟机中,硬件时钟被虚拟化,这对于需要精确计时的应用程序提出了额外的挑战【50】。当一个CPU核心在虚拟机之间共享时,每个虚拟机都会暂停几十毫秒,而另一个虚拟机正在运行。从应用程序的角度来看,这种停顿表现为时钟突然向前跳跃【26】。
如果你足够关心这件事并投入大量资源,就可以达到非常好的时钟精度。例如,针对金融机构的欧洲法规草案MiFID II要求所有高频率交易基金在UTC时间100微秒内同步时钟,以便调试“闪崩”等市场异常现象,并帮助检测市场操纵【51】。
使用GPS接收机,精确时间协议(PTP)【52】以及仔细的部署和监测可以实现这种精确度。然而,这需要很多努力和专业知识,而且有很多东西都会导致时钟同步错误。如果你的NTP守护进程配置错误,或者防火墙阻止了NTP通信,由漂移引起的时钟误差可能很快就会变大。
将时间看做是某种置信区间而非绝对值,这个置信区间需要考虑所有时间同步过程中可能出现的延迟。
您可能能够以微秒或甚至纳秒的分辨率读取机器的时钟。但即使可以得到如此细致的测量结果,这并不意味着这个值对于这样的精度实际上是准确的。实际上,如前所述,即使您每分钟与本地网络上的NTP服务器进行同步,很可能也不会像前面提到的那样,在不精确的石英时钟上漂移几毫秒。使用公共互联网上的NTP服务器,最好的准确度可能达到几十毫秒,而且当网络拥塞时,误差可能会超过100毫秒【57】。
因此,将时钟读数视为一个时间点是没有意义的——它更像是一段时间范围:例如,一个系统可能以95%的置信度认为当前时间处于本分钟内的第10.3秒和10.5秒之间,它可能没法比这更精确了【58】。如果我们只知道±100毫秒的时间,那么时间戳中的微秒数字部分基本上是没有意义的。
不确定性界限可以根据你的时间源来计算。如果您的GPS接收器或原子(铯)时钟直接连接到您的计算机上,预期的错误范围由制造商报告。如果从服务器获得时间,则不确定性取决于自上次与服务器同步以来的石英钟漂移的期望值,加上NTP服务器的不确定性,再加上到服务器的网络往返时间(只是获取粗略近似值,并假设服务器是可信的)。
一个有趣的例外是Spanner中的Google TrueTime API 【41】,它明确地报告了本地时钟的置信区间。当你询问当前时间时,你会得到两个值:[最早,最晚],这是最早可能的时间戳和最晚可能的时间戳。在不确定性估计的基础上,时钟知道当前的实际时间落在该区间内。间隔的宽度取决于自从本地石英钟最后与更精确的时钟源同步以来已经过了多长时间。
可以使用”置信区间“的时间来作为事务ID.
我们可以使用同步时钟的时间戳作为事务ID吗?如果我们能够获得足够好的同步性,那么这种方法将具有很合适的属性:更晚的事务会有更大的时间戳。当然,问题在于时钟精度的不确定性。
为了确保事务时间戳反映因果关系,在提交读写事务之前,Spanner在提交读写事务时,会故意等待置信区间长度的时间。通过这样,它可以确保任何可能读取数据的事务处于足够晚的时间,因此它们的置信区间不会重叠。为了保持尽可能短的等待时间,Spanner需要保持尽可能小的时钟不确定性,为此,Google在每个数据中心都部署了一个GPS接收器或原子钟,允许时钟在大约7毫秒内同步【41】。
对分布式事务语义使用时钟同步是一个活跃的研究领域【57,61,62】。这些想法很有趣,但是它们还没有在谷歌之外的主流数据库中实现。
什么情况下要考虑拜占庭容错处理?
当一个系统在部分节点发生故障、不遵守协议、甚至恶意攻击、扰乱网络时仍然能继续正确工作,称之为拜占庭容错(Byzantine fault-tolerant)的,在特定场景下,这种担忧在是有意义的:
- 在航空航天环境中,计算机内存或CPU寄存器中的数据可能被辐射破坏,导致其以任意不可预知的方式响应其他节点。由于系统故障将非常昂贵(例如,飞机撞毁和炸死船上所有人员,或火箭与国际空间站相撞),飞行控制系统必须容忍拜占庭故障【81,82】。
- 在多个参与组织的系统中,一些参与者可能会试图欺骗或欺骗他人。在这种情况下,节点仅仅信任另一个节点的消息是不安全的,因为它们可能是出于恶意的目的而被发送的。例如,像比特币和其他区块链一样的对等网络可以被认为是让互不信任的各方同意交易是否发生的一种方式,而不依赖于中央当局【83】。
然而,在本书讨论的那些系统中,我们通常可以安全地假设没有拜占庭式的错误。在你的数据中心里,所有的节点都是由你的组织控制的(所以他们可以信任),辐射水平足够低,内存损坏不是一个大问题。制作拜占庭容错系统的协议相当复杂【84】,而容错嵌入式系统依赖于硬件层面的支持【81】。在大多数服务器端数据系统中,部署拜占庭容错解决方案的成本使其变得不切实际。
软件中的一个错误可能被认为是拜占庭式的错误,但是如果您将相同的软件部署到所有节点上,那么拜占庭式的容错算法不能为您节省。大多数拜占庭式容错算法要求超过三分之二的节点能够正常工作(即,如果有四个节点,最多只能有一个故障)。要使用这种方法对付bug,你必须有四个独立的相同软件的实现,并希望一个bug只出现在四个实现之一中。
Chapter9 一致性与共识
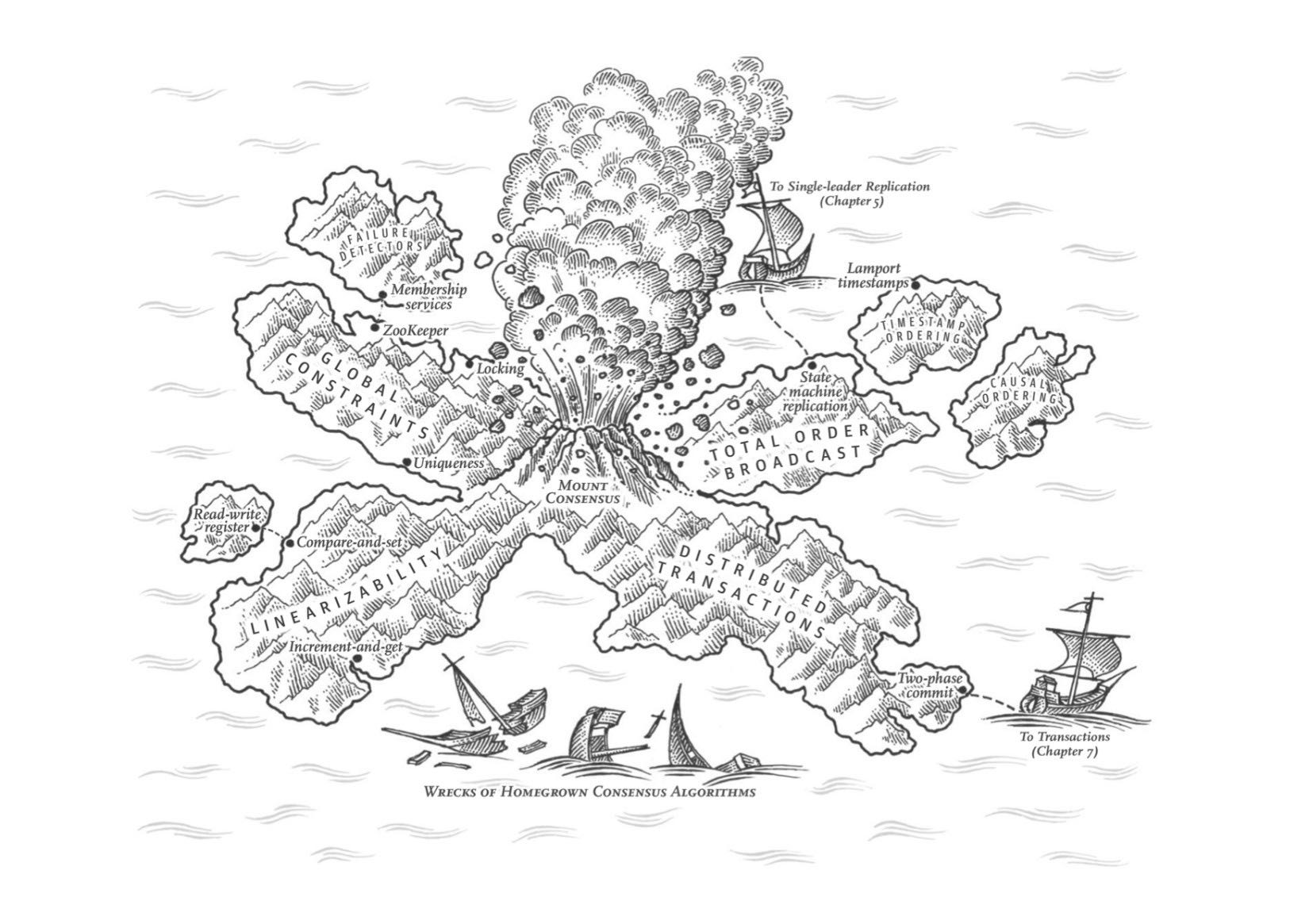
这章看的有点晕,主要讨论如何实现各种一致性(consistency), 主要是strong consistency/linearizability.
我们之所以关注linearizability,本质上是因为我们更关心因果性,所以先从实现casual consistency/casuality(而且大部分情况下也是我们需要的)(lz/linearizability ~ total order, cc/casual consistency ~ casual order)入手。Lamport论文给出了一种为操作之间定序的方法,但是这种方法给出的序是一种偏序不是全序,也就是某些操作之间存在顺序关系,但是另外一些操作之间可能不存在顺序关系。因为cc本质上给出的就是偏序而非全序,lz(全序)实际上是要强于cc的。
在实际系统中,我们希望所有操作之间存在顺序关系,并且需要被所有节点确认(total order broadcast). 事实上当我们可以做到total order broadcast的时候,我们就实现了lz. total order broadcast和consensus algorithm是等价的。 如何实现分布式事务(2PC)和共识算法(paxos, raft, zookeeper). 感觉这章难度比较大,如果相对分布式系统和理论深入学习的话,可以先把这个部分吃透。
这章感觉理论东西比较多(比如证明lz, total order bropadcast, consensus algorithm是等价的),但是如果忽略也不会太有影响。总之为了达到线性一致性,我们就要实现共识算法,两者是等价的。
如何简单地理解线性一致性(Linearizability)
在最终一致的数据库,如果你在同一时刻问两个不同副本相同的问题,可能会得到两个不同的答案。这很让人困惑。如果数据库可以提供只有一个副本的假象(即,只有一个数据副本),那么事情就简单太多了。那么每个客户端都会有相同的数据视图,且不必担心复制滞后了。
这就是线性一致性(linearizability)背后的想法【6】(也称为原子一致性(atomic consistency)【7】,强一致性(strong consistency) , 立即一致性(immediate consistency) 或 外部一致性(external consistency ) 【8】)。线性一致性的精确定义相当微妙,我们将在本节的剩余部分探讨它。但是基本的想法是让一个系统看起来好像只有一个数据副本,而且所有的操作都是原子性的。有了这个保证,即使实际中可能有多个副本,应用也不需要担心它们。
区分线性一致性(linearizaibility,lz)和可序列化(serializability,sz). 一个简单的例子是,如果操作A, B涉及到读取和更新多个相同对象的时候,lz关注的是所有节点上看到AB的顺序是否一致,而sz关注的是在执行A,B操作的时候之间的事务隔离性如何以及最后结果如何。
线性一致性容易和可序列化相混淆,因为两个词似乎都是类似“可以按顺序排列”的东西。但它们是两种完全不同的保证,区分两者非常重要:
可序列化(Serializability)是事务的隔离属性,每个事务可以读写多个对象(行,文档,记录)——参阅“单对象和多对象操作”。它确保事务的行为,与它们按照某种顺序依次执行的结果相同(每个事务在下一个事务开始之前运行完成)。这种执行顺序可以与事务实际执行的顺序不同。【12】。
线性一致性(Linearizability)是读取和写入寄存器(单个对象)的新鲜度保证。它不会将操作组合为事务,因此它也不会阻止写偏差等问题(参阅“写偏差和幻读”),除非采取其他措施(例如物化冲突)。
一个数据库可以提供可串行性和线性一致性,这种组合被称为严格的可串行性或强的单副本强可串行性(strong-1SR)【4,13】。基于两阶段锁定的可串行化实现(参见“两阶段锁定(2PL)”一节)或实际串行执行(参见第“实际串行执行”)通常是线性一致性的。
但是,可序列化的快照隔离(参见“可序列化的快照隔离(SSI)”)不是线性一致性的:按照设计,它可以从一致的快照中进行读取,以避免锁定读者和写者之间的争用。一致性快照的要点就在于它不会包括比快照更新的写入,因此从快照读取不是线性一致性的。
CAP定理没有帮助
CAP有时以这种面目出现:一致性,可用性和分区容忍:三者只能择其二。不幸的是这种说法很有误导性【32】,因为网络分区是一种错误,所以它并不是一个选项:不管你喜不喜欢它都会发生【38】。
在网络正常工作的时候,系统可以提供一致性(线性一致性)和整体可用性。发生网络故障时,你必须在线性一致性和整体可用性之间做出选择。因此,一个更好的表达CAP的方法可以是一致的,或者在分区时可用【39】。一个更可靠的网络需要减少这个选择,但是在某些时候选择是不可避免的。
CAP定理的正式定义仅限于很狭隘的范围【30】,它只考虑了一个一致性模型(即线性一致性)和一种故障(网络分区vi,或活跃但彼此断开的节点)。它没有讨论任何关于网络延迟,死亡节点或其他权衡的事。 因此,尽管CAP在历史上有一些影响力,但对于设计系统而言并没有实际价值【9,40】。
在分布式系统中有更多有趣的“不可能”的结果【41】,且CAP定理现在已经被更精确的结果取代【2,42】,所以它现在基本上成了历史古迹了。
牺牲线性一致性是为了提高性能而不是为了做容错
虽然线性一致是一个很有用的保证,但实际上,线性一致的系统惊人的少。例如,现代多核CPU上的内存甚至都不是线性一致的【43】:如果一个CPU核上运行的线程写入某个内存地址,而另一个CPU核上运行的线程不久之后读取相同的地址,并没有保证一定能一定读到第一个线程写入的值(除非使用了内存屏障(memory barrier) 或 围栏(fence)【44】)。
这种行为的原因是每个CPU核都有自己的内存缓存和存储缓冲区。默认情况下,内存访问首先走缓存,任何变更会异步写入主存。因为缓存访问比主存要快得多【45】,所以这个特性对于现代CPU的良好性能表现至关重要。但是现在就有几个数据副本(一个在主存中,也许还有几个在不同缓存中的其他副本),而且这些副本是异步更新的,所以就失去了线性一致性。
为什么要做这个权衡?对多核内存一致性模型而言,CAP定理是没有意义的:在同一台计算机中,我们通常假定通信都是可靠的。并且我们并不指望一个CPU核能在脱离计算机其他部分的条件下继续正常工作。牺牲线性一致性的原因是性能(performance),而不是容错。
许多分布式数据库也是如此:它们是为了提高性能而选择了牺牲线性一致性,而不是为了容错【46】。线性一致的速度很慢——这始终是事实,而不仅仅是网络故障期间。
除了通过lz来捕获因果性之外,还有其他办法捕获因果关系,比如事务级别的SSI实现。这种捕获因果关系本质上都是对数据依赖图做分析。
为了维持因果性,你需要知道哪个操作发生在哪个其他操作之前(happened before)。这是一个偏序:并发操作可以以任意顺序进行,但如果一个操作发生在另一个操作之前,那它们必须在所有副本上以那个顺序被处理。因此,当一个副本处理一个操作时,它必须确保所有因果前驱的操作(之前发生的所有操作)已经被处理;如果前面的某个操作丢失了,后面的操作必须等待,直到前面的操作被处理完毕。
实践中处于性能考虑大家很少使用分布式事务,但是事实上分布式事务是绕不开的,最终大家都会用自己的方式实现分布式事务。 某些数据库内置分布式事务,虽然性能不好,但是总比自己实现好。真实系统中,我们需要将很多子系统连接起来,如何在这些子系统之间实现事务,我们就需要比较好的分布式事务服务了。
分 布式事务的名声毁誉参半,尤其是那些通过两阶段提交实现的。一方面,它被视作提供了一个难以实现的重要的安全性保证;另一方面,它们因为导致运维问题,造成性能下降,做出超过能力范围的承诺而饱受批评【81,82,83,84】。许多云服务由于其导致的运维问题,而选择不实现分布式事务【85,86】。
分布式事务的某些实现会带来严重的性能损失 —— 例如据报告称,MySQL中的分布式事务比单节点事务慢10倍以上【87】,所以当人们建议不要使用它们时就不足为奇了。两阶段提交所固有的性能成本,大部分是由于崩溃恢复所需的额外强制刷盘( fsync )【88】以及额外的网络往返。
但我们不应该直接忽视分布式事务,而应当更加仔细地审视这些事务,因为从中可以汲取重要的经验教训。首先,我们应该精确地说明“分布式事务”的含义。两种截然不同的分布式事务类型经常被混淆:
数据库内部的分布式事务:一些分布式数据库(即在其标准配置中使用复制和分区的数据库)支持数据库节点之间的内部事务。例如,VoltDB和MySQL Cluster的NDB存储引擎就有这样的内部事务支持。在这种情况下,所有参与事务的节点都运行相同的数据库软件。
异构分布式事务:在 异构(heterogeneous)事务中,参与者是两种或以上不同技术:例如来自不同供应商的两个数据库,甚至是非数据库系统(如消息代理)。跨系统的分布式事务必须确保原子提交,尽管系统可能完全不同。 数据库内部事务不必与任何其他系统兼容,因此它们可以使用任何协议,并能针对特定技术进行特定的优化。因此数据库内部的分布式事务通常工作地很好。另一方面,跨异构技术的事务则更有挑战性。
为什么2PC中协调者挂掉(coordinator)挂掉是非常严重的问题?因为参与者这个时候正在等待执行/终止事务,会潜在地block其他事务的执行
为什么我们这么关心存疑事务?系统的其他部分就不能继续正常工作,无视那些终将被清理的存疑事务吗? 问题在于锁(locking)。正如在“读已提交”中所讨论的那样,数据库事务通常获取待修改的行上的行级排他锁,以防止脏写。此外,如果要使用可序列化的隔离等级,则使用两阶段锁定的数据库也必须为事务所读取的行加上共享锁(参见“两阶段锁定(2PL)”)。
在事务提交或中止之前,数据库不能释放这些锁(如图9-9中的阴影区域所示)。因此,在使用两阶段提交时,事务必须在整个存疑期间持有这些锁。如果协调者已经崩溃,需要20分钟才能重启,那么这些锁将会被持有20分钟。如果协调者的日志由于某种原因彻底丢失,这些锁将被永久持有–或至少在管理员手动解决该情况之前。
当这些锁被持有时,其他事务不能修改这些行。根据数据库的不同,其他事务甚至可能因为读取这些行而被阻塞。因此,其他事务没法儿简单地继续它们的业务了 —— 如果它们要访问同样的数据,就会被阻塞。这可能会导致应用大面积进入不可用状态,直到存疑事务被解决。
著名的容错共识算法有下面这些。为什么要强调容错呢?容错就是少数节点发生故障的时候依然可以达成共识。如果不强调容错的话,那么直接让管理员指定一个节点是leader也是一种共识算法。 有些共识算法是直接支持全序广播的,paxos不是,改进的multi-paxos才是。
最著名的容错共识算法是视图戳复制(VSR, viewstamped replication)【94,95】,Paxos 【96,97,98,99】,Raft 【22,100,101】以及 Zab 【15,21,102】 。这些算法之间有不少相似之处,但它们并不相同【103】。在本书中我们不会介绍各种算法的详细细节:了解一些它们共通的高级思想通常已经足够了,除非你准备自己实现一个共识系统。(可能并不明智,相当难【98,104】)
请记住,全序广播要求将消息按照相同的顺序,恰好传递一次,准确传送到所有节点。如果仔细思考,这相当于进行了几轮共识:在每一轮中,节点提议下一条要发送的消息,然后决定在全序中下一条要发送的消息【67】。
所以,全序广播相当于重复进行多轮共识(每次共识决定与一次消息传递相对应):
- 由于一致同意属性,所有节点决定以相同的顺序传递相同的消息。
- 由于完整性属性,消息不会重复。
- 由于有效性属性,消息不会被损坏,也不能凭空编造。
- 由于终止属性,消息不会丢失。
视图戳复制,Raft和Zab直接实现了全序广播,因为这样做比重复一次一值(one value a time)的共识更高效。在Paxos的情况下,这种优化被称为Multi-Paxos。
所有共识算法的保证和大致框架:保证在一个时间段内只有一个leader,成员都可以发起一次选举。流程上先让大家选择leader, 然后在给leader投票(先让大家充分知情交换意见,然后使用相同算法,由多数人选举)。
迄今为止所讨论的所有共识协议,在内部都以某种形式使用一个领导者,但它们并不能保证领导者是独一无二的。相反,它们可以做出更弱的保证:协议定义了一个时代编号(epoch number)(在Paxos中称为投票编号(ballot number),视图戳复制中的视图编号(view number),以及Raft中的任期号码(term number)),并确保在每个时代中,领导者都是唯一的。
因此,我们有两轮投票:第一次是为了选出一位领导者,第二次是对领导者的提议进行表决。关键的洞察在于,这两次投票的法定人群必须相互重叠(overlap):如果一个提案的表决通过,则至少得有一个参与投票的节点也必须参加过最近的领导者选举【105】。因此,如果在一个提案的表决过程中没有出现更高的时代编号。那么现任领导者就可以得出这样的结论:没有发生过更高时代的领导选举,因此可以确定自己仍然在领导。然后它就可以安全地对提议值做出决定。
Chapter10 批处理
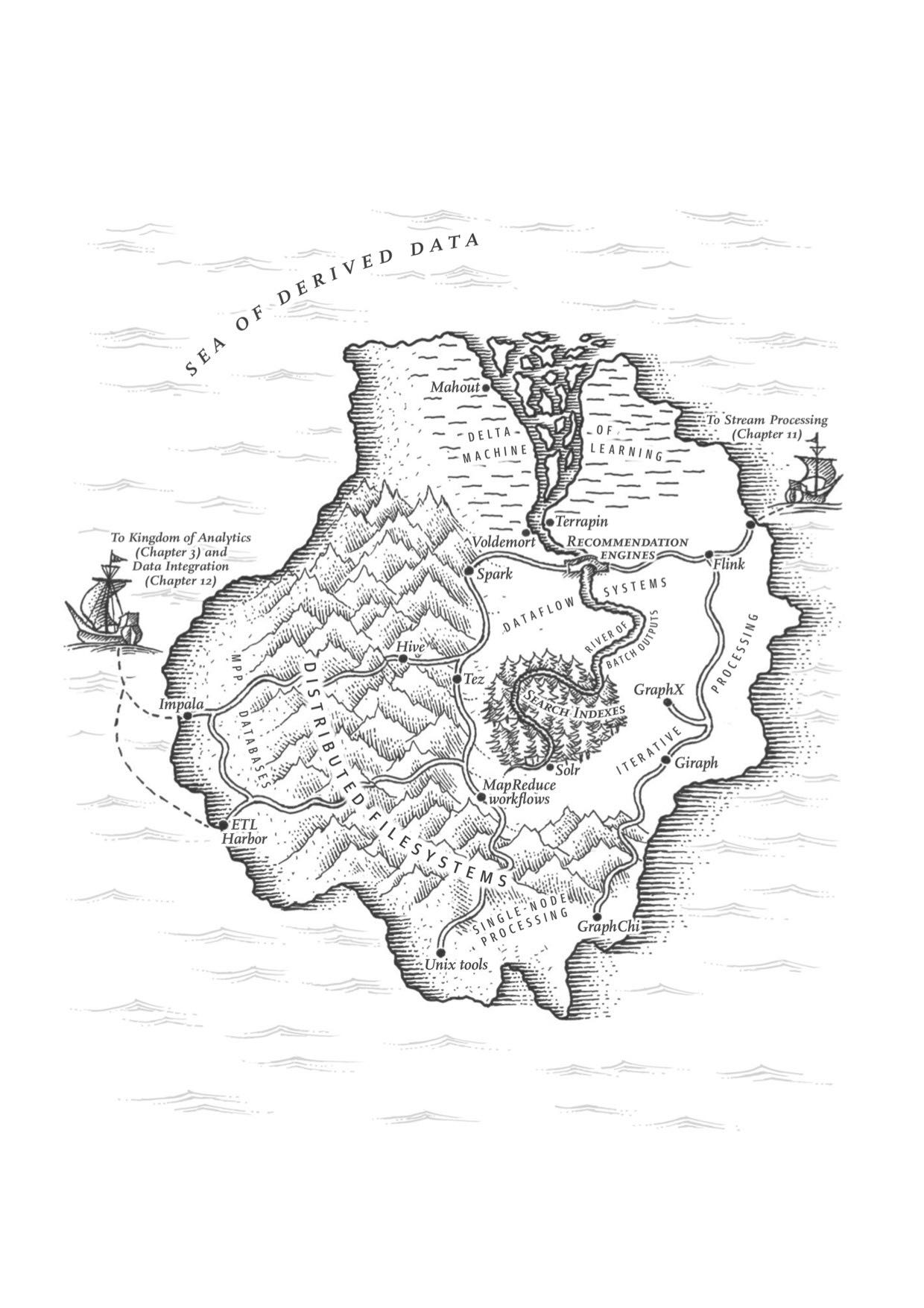
这章讨论了批处理系统的发展历史(和Unix Tools的对比),MapReduce/Graph编程模型,MR和MPP之间的对比,以及未来发展的趋势(operators, high-level API, graph iterative processing, machine learning capability etc)。
MapReduce和MPP之间的差别:MPP专注于在数据库上并行执行SQL,而MapReduce更像是某种基础设施,你需要做更高层次的抽象。
当MapReduce论文发表时【1】,它从某种意义上来说 —— 并不新鲜。我们在前几节中讨论的所有处理和并行连接算法已经在十多年前所谓的大规模并行处理(MPP, massively parallel processing)数据库中实现了【3,40】。比如Gamma database machine,Teradata和Tandem NonStop SQL就是这方面的先驱【52】。
最大的区别是,MPP数据库专注于在一组机器上并行执行分析SQL查询,而MapReduce和分布式文件系统【19】的组合则更像是一个可以运行任意程序的通用操作系统。
MR和MPP在存储多样性上的差别:MPP要求专有数据格式,而MR对数据格式没有特殊要求,而这在大数据时期可能是个优势。
数据库要求你根据特定的模型(例如关系或文档)来构造数据,而分布式文件系统中的文件只是字节序列,可以使用任何数据模型和编码来编写。它们可能是数据库记录的集合,但同样可以是文本,图像,视频,传感器读数,稀疏矩阵,特征向量,基因组序列或任何其他类型的数据。
说白了,Hadoop开放了将数据不加区分地转储到HDFS的可能性,允许后续再研究如何进一步处理【53】。相比之下,在将数据导入数据库专有存储格式之前,MPP数据库通常需要对数据和查询模式进行仔细的前期建模。
在纯粹主义者看来,这种仔细的建模和导入似乎是可取的,因为这意味着数据库的用户有更高质量的数据来处理。然而实践经验表明,简单地使数据快速可用 —— 即使它很古怪,难以使用,使用原始格式 —— 也通常要比事先决定理想数据模型要更有价值【54】。
这个想法与数据仓库类似(参阅“数据仓库”):将大型组织的各个部分的数据集中在一起是很有价值的,因为它可以跨越以前相分离的数据集进行连接。 MPP数据库所要求的谨慎模式设计拖慢了集中式数据收集速度;以原始形式收集数据,稍后再操心模式的设计,能使数据收集速度加快(有时被称为“数据湖(data lake)”或“企业数据中心(enterprise data hub)”【55】)。
不加区分的数据转储转移了解释数据的负担:数据集的生产者不再需要强制将其转化为标准格式,数据的解释成为消费者的问题(读时模式方法【56】;参阅“文档模型中的架构灵活性”)。如果生产者和消费者是不同优先级的不同团队,这可能是一种优势。甚至可能不存在一个理想的数据模型,对于不同目的有不同的合适视角。以原始形式简单地转储数据,可以允许多种这样的转换。这种方法被称为寿司原则(sushi principle):“原始数据更好”【57】。
MR和MPP在处理模型多样性上差别:MPP处理模型相对比较单一,虽然SQL能做UDF扩展,但是能力依然优先;MR在这方面也做的不太好,所以会有更多的处理模型出来比如Spark, Pregel等。
MPP数据库是单体的,紧密集成的软件,负责磁盘上的存储布局,查询计划,调度和执行。由于这些组件都可以针对数据库的特定需求进行调整和优化,因此整个系统可以在其设计针对的查询类型上取得非常好的性能。而且,SQL查询语言允许以优雅的语法表达查询,而无需编写代码,使业务分析师用来做商业分析的可视化工具(例如Tableau)能够访问。
另一方面,并非所有类型的处理都可以合理地表达为SQL查询。例如,如果要构建机器学习和推荐系统,或者使用相关性排名模型的全文搜索索引,或者执行图像分析,则很可能需要更一般的数据处理模型。这些类型的处理通常是特别针对特定应用的(例如机器学习的特征工程,机器翻译的自然语言模型,欺诈预测的风险评估函数),因此它们不可避免地需要编写代码,而不仅仅是查询。
MapReduce使工程师能够轻松地在大型数据集上运行自己的代码。如果你有HDFS和MapReduce,那么你可以在它之上建立一个SQL查询执行引擎,事实上这正是Hive项目所做的【31】。但是,你也可以编写许多其他形式的批处理,这些批处理不必非要用SQL查询表示。
随后,人们发现MapReduce对于某些类型的处理而言局限性很大,表现很差,因此在Hadoop之上其他各种处理模型也被开发出来(我们将在“MapReduce之后”中看到其中一些)。有两种处理模型,SQL和MapReduce,还不够,需要更多不同的模型!而且由于Hadoop平台的开放性,实施一整套方法是可行的,而这在单体MPP数据库的范畴内是不可能的【58】。
MR和MPP在针对频繁故障设计上处理方式不同:如果某个节点查询是崩溃,MPP会终止查询,而MapReduce则有更强的容错机制。
当比较MapReduce和MPP数据库时,两种不同的设计思路出现了:处理故障和使用内存与磁盘的方式。与在线系统相比,批处理对故障不太敏感,因为就算失败也不会立即影响到用户,而且它们总是能再次运行。
如果一个节点在执行查询时崩溃,大多数MPP数据库会中止整个查询,并让用户重新提交查询或自动重新运行它【3】。由于查询通常最多运行几秒钟或几分钟,所以这种错误处理的方法是可以接受的,因为重试的代价不是太大。 MPP数据库还倾向于在内存中保留尽可能多的数据(例如,使用散列连接)以避免从磁盘读取的开销。
另一方面,MapReduce可以容忍单个Map或Reduce任务的失败,而不会影响作业的整体,通过以单个任务的粒度重试工作。它也会非常急切地将数据写入磁盘,一方面是为了容错,另一部分是因为假设数据集太大而不能适应内存。
MapReduce之所以考虑容错机制,容错硬件故障是一方面,另一方面则是因为Google任务是运行在共享资源的由抢占式调度器调度的环境下的,所以task被杀掉释放资源并不是低概率的事件。这也是为什么开源的资源调度器抢占式的使用较少的原因。
但是这些假设有多么现实呢?在大多数集群中,机器故障确实会发生,但是它们不是很频繁 —— 可能少到绝大多数作业都不会经历机器故障。为了容错,真的值得带来这么大的额外开销吗?
要了解MapReduce节约使用内存和在任务的层次进行恢复的原因,了解最初设计MapReduce的环境是很有帮助的。 Google有着混用的数据中心,在线生产服务和离线批处理作业在同样机器上运行。每个任务都有一个通过容器强制执行的资源配给(CPU核心,RAM,磁盘空间等)。每个任务也具有优先级,如果优先级较高的任务需要更多的资源,则可以终止(抢占)同一台机器上较低优先级的任务以释放资源。优先级还决定了计算资源的定价:团队必须为他们使用的资源付费,而优先级更高的进程花费更多【59】。
这种架构允许非生产(低优先级)计算资源被过量使用(overcommitted),因为系统知道必要时它可以回收资源。与分离生产和非生产任务的系统相比,过量使用资源可以更好地利用机器并提高效率。但由于MapReduce作业以低优先级运行,它们随时都有被抢占的风险,因为优先级较高的进程可能需要其资源。在高优先级进程拿走所需资源后,批量作业能有效地“捡面包屑”,利用剩下的任何计算资源。
在谷歌,运行一个小时的MapReduce任务有大约有5%的风险被终止,为了给更高优先级的进程挪地方。这一概率比硬件问题,机器重启或其他原因的概率高了一个数量级【59】。按照这种抢占率,如果一个作业有100个任务,每个任务运行10分钟,那么至少有一个任务在完成之前被终止的风险大于50%。
这就是MapReduce被设计为容忍频繁意外任务终止的原因:不是因为硬件很不可靠,而是因为任意终止进程的自由有利于提高计算集群中的资源利用率。
图算法有效地并行执行是个很难的问题,节点之间通信代价很快就会超过并行执行本身带来的效率。所以如果图规模不大的话,放在单集上跑是更有效的,尤其是运行通信很密集的图算法。
因此,图算法通常会有很多跨机器通信的额外开销,而中间状态(节点之间发送的消息)往往比原始图大。通过网络发送消息的开销会显着拖慢分布式图算法的速度。
出于这个原因,如果你的图可以放入一台计算机的内存中,那么单机(甚至可能是单线程)算法很可能会超越分布式批处理【73,74】。图比内存大也没关系,只要能放入单台计算机的磁盘,使用GraphChi等框架进行单机处理是就一个可行的选择【75】。如果图太大,不适合单机处理,那么像Pregel这样的分布式方法是不可避免的。高效的并行图算法是一个进行中的研究领域【76】。
Chapter11 流处理
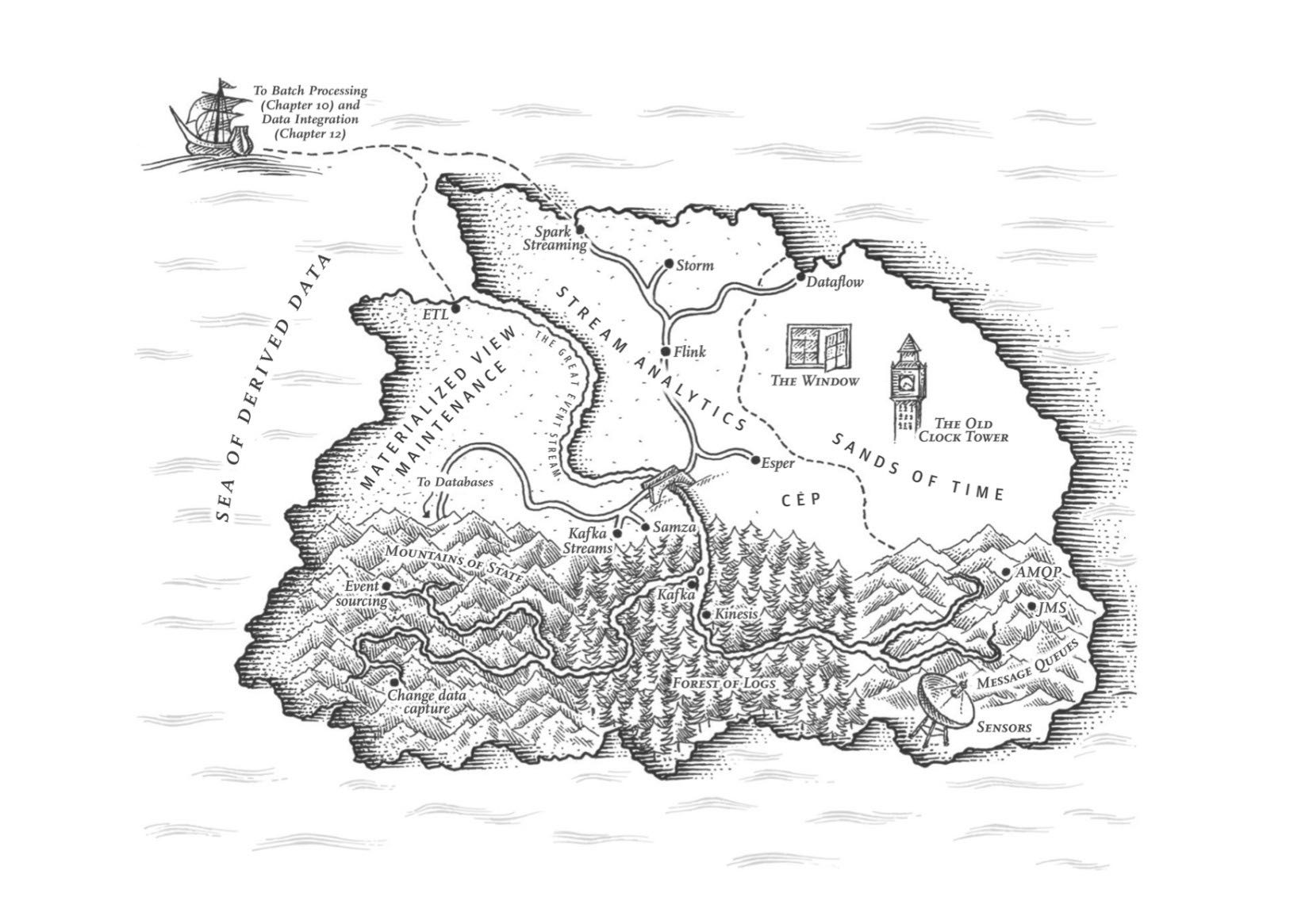
这章讨论流式处理系统,包括message broker(JMS-style游标维护在服务器没有办法定序,以及log-based游标维护在客户端), 如何有效地使用log来让多个数据系统进行同步(change data capture), 以及流式消息系统的join和容错处理。
日志与传统消息相比
基于日志的方法天然支持扇出式消息传递,因为多个消费者可以独立读取日志,而不会相互影响 —— 读取消息不会将其从日志中删除。为了在一组消费者之间实现负载平衡,代理可以将整个分区分配给消费者组中的节点,而不是将单条消息分配给消费者客户端。
每个客户端消费指派分区中的所有消息。然后使用分配的分区中的所有消息。通常情况下,当一个用户被指派了一个日志分区时,它会以简单的单线程方式顺序地读取分区中的消息。这种粗粒度的负载均衡方法有一些缺点:
- 共享消费主题工作的节点数,最多为该主题中的日志分区数,因为同一个分区内的所有消息被递送到同一个节点。
- 如果某条消息处理缓慢,则它会阻塞该分区中后续消息的处理(一种行首阻塞的形式;请参阅“描述性能”)。
因此在消息处理代价高昂,希望逐条并行处理,以及消息的顺序并没有那么重要的情况下,JMS/AMQP风格的消息代理是可取的。另一方面,在消息吞吐量很高,处理迅速,顺序很重要的情况下,基于日志的方法表现得非常好。
数据变更捕获技术(CDC, changed data capture)
大多数数据库的复制日志的问题在于,它们一直被当做数据库的内部实现细节,而不是公开的API。客户端应该通过其数据模型和查询语言来查询数据库,而不是解析复制日志并尝试从中提取数据。
数十年来,许多数据库根本没有记录在档的,获取变更日志的方式。由于这个原因,捕获数据库中所有的变更,然后将其复制到其他存储技术(搜索索引,缓存,数据仓库)中是相当困难的。
最近,人们对变更数据捕获(change data capture, CDC)越来越感兴趣,这是一种观察写入数据库的所有数据变更,并将其提取并转换为可以复制到其他系统中的形式的过程。 CDC是非常有意思的,尤其是当变更能在被写入后立刻用于流时。
复合事件处理(complex event processing, CEP): 内部需要维护某种状态机,在接收到某类事件之后进行状态转换。
复合事件处理(complex, event processing, CEP)是20世纪90年代为分析事件流而开发出的一种方法,尤其适用于需要搜索某些事件模式的应用【65,66】。与正则表达式允许你在字符串中搜索特定字符模式的方式类似,CEP允许你指定规则以在流中搜索某些事件模式。
CEP系统通常使用高层次的声明式查询语言,比如SQL,或者图形用户界面,来描述应该检测到的事件模式。这些查询被提交给处理引擎,该引擎消费输入流,并在内部维护一个执行所需匹配的状态机。当发现匹配时,引擎发出一个复合事件(complex event)(因此得名),并附有检测到的事件模式详情【67】。
在这些系统中,查询和数据之间的关系与普通数据库相比是颠倒的。通常情况下,数据库会持久存储数据,并将查询视为临时的:当查询进入时,数据库搜索与查询匹配的数据,然后在查询完成时丢掉查询。 CEP引擎反转了角色:查询是长期存储的,来自输入流的事件不断流过它们,搜索匹配事件模式的查询【68】。
CEP的实现包括Esper 【69】,IBM InfoSphere Streams 【70】,Apama,TIBCO StreamBase和SQLstream。像Samza这样的分布式流处理组件,支持使用SQL在流上进行声明式查询【71】。
校正客户端时间方法。时间变动对于流处理系统更加敏感。
要校正不正确的设备时钟,一种方法是记录三个时间戳【82】:
- 事件发生的时间,取决于设备时钟
- 事件发送往服务器的时间,取决于设备时钟
- 事件被服务器接收的时间,取决于服务器时钟
通过从第三个时间戳中减去第二个时间戳,可以估算设备时钟和服务器时钟之间的偏移(假设网络延迟与所需的时间戳精度相比可忽略不计)。然后可以将该偏移应用于事件时间戳,从而估计事件实际发生的真实时间(假设设备时钟偏移在事件发生时与送往服务器之间没有变化)。
这并不是流处理独有的问题,批处理有着完全一样的时间推理问题。只是在流处理的上下文中,我们更容易意识到时间的流逝。
在搜索-点击这种流-流连接状态中,我们不能只处理点击事件。因为如果没有任何点击事件的话,你是没有办法知道哪些链接是没有被点击的。
请注意,在点击事件中嵌入搜索详情与事件连接并不一样:这样做的话,只有当用户点击了一个搜索结果时你才能知道,而那些没有点击的搜索就无能为力了。为了衡量搜索质量,你需要准确的点击率,为此搜索事件和点击事件两者都是必要的。
为了实现这种类型的连接,流处理器需要维护状态:例如,按会话ID索引最近一小时内发生的所有事件。无论何时发生搜索事件或点击事件,都会被添加到合适的索引中,而流处理器也会检查另一个索引是否有具有相同会话ID的事件到达。如果有匹配事件就会发出一个表示搜索结果被点击的事件;如果搜索事件直到过期都没看见有匹配的点击事件,就会发出一个表示搜索结果未被点击的事件。
Chapter12 数据系统的未来
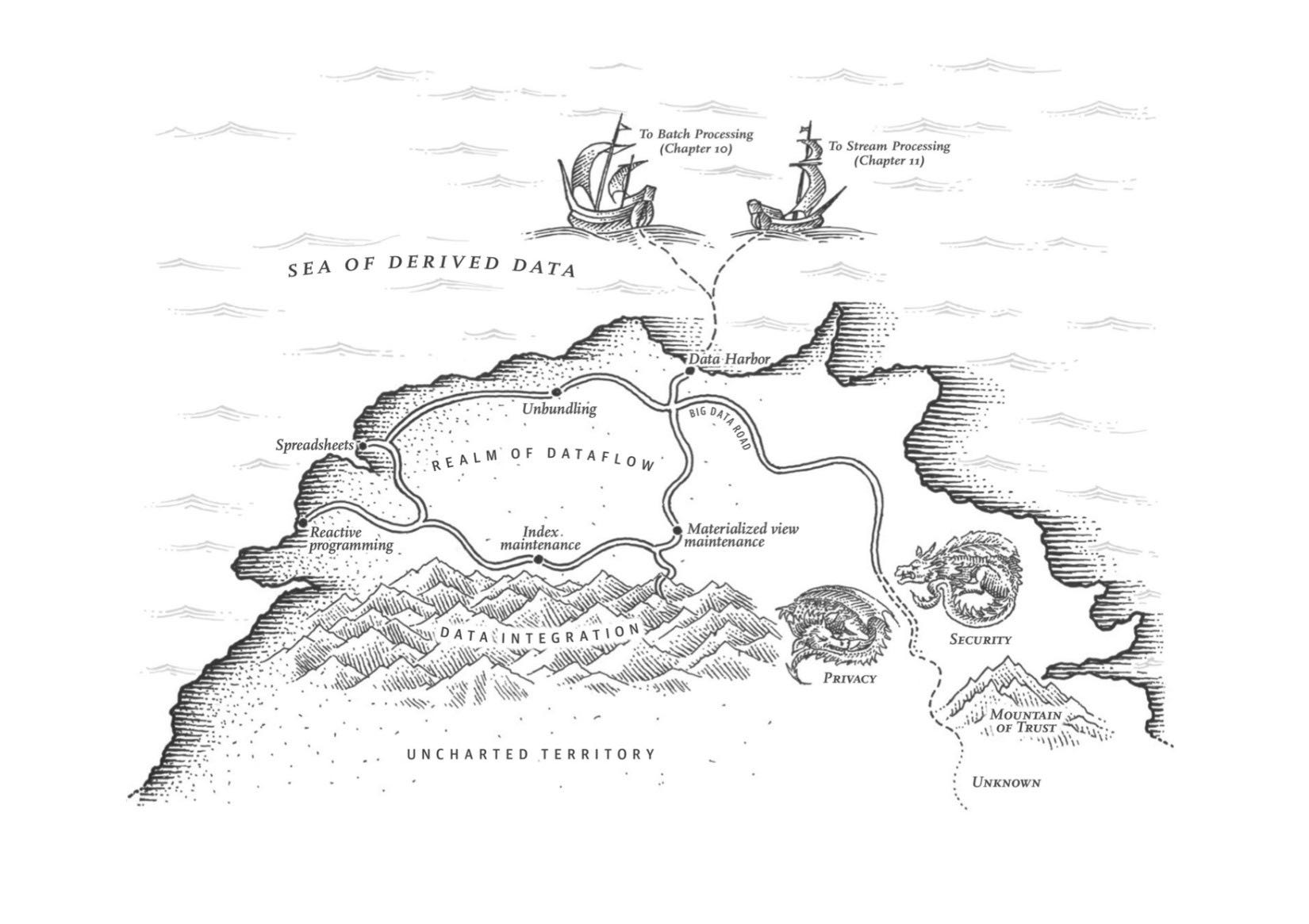
这章讨论数据系统的未来发展,如何多个数据系统如何整合起来:将公司当做一个大数据库的话,内部各种数据系统就有点像各种索引,每种索引适合不同的场景。为了充分发挥作用,这个大数据库在读取时候会将各种数据系统组合起来,而在写入的时候又需要拆分开来保持数据同步。最后一节从社会角度讨论了如何正确地利用数据,数据和工具应该被我们所利用,而不应该成为我们的主人。
统一批处理和流处理。通过在流处理系统里面提供批处理的功能,可以统一两者。
最近的工作使得Lambda架构的优点在没有其缺点的情况下得以实现,允许批处理计算(重新处理历史数据)和流计算(处理事件到达时)在同一个系统中实现【15】。
在一个系统中统一批处理和流处理需要以下功能,这些功能越来越广泛:
- 通过处理最近事件流的相同处理引擎来重放历史事件的能力。例如,基于日志的消息代理可以重放消息(参阅“重放旧消息”),某些流处理器可以从HDFS等分布式文件系统读取输入。
- 对于流处理器来说,恰好一次语义 —— 即确保输出与未发生故障的输出相同,即使事实上发生故障(参阅“故障容错”)。与批处理一样,这需要丢弃任何失败任务的部分输出。
- 按事件时间进行窗口化的工具,而不是按处理时间进行窗口化,因为处理历史事件时,处理时间毫无意义(参阅“时间推理”)。例如,Apache Beam提供了用于表达这种计算的API,然后可以使用Apache Flink或Google Cloud Dataflow运行。