DBMS Introduction
Table of Contents
数据库系统基础教程(A First Course in Database Systems by Jeffrey D. Ullman)
1. 数据库系统世界
1.1. DBMS功能
DBMS需要有如下功能:
- 数据定义语言(data-definition language)建立数据库,它们的模式(schema)就是数据的逻辑结构。
- 数据操作语言(data-manipulation language)来查询(query)和更新(update)数据库。
- 支持超大数据量数据的长时间存储(GB,TB,PB),并且在数据查询和更新时支持数据的有效存取。
- 具有持久性,面对各种故障错误时,数据库的恢复保证数据的一致性。
- 控制多个用户对数据的同时存取,不允许一个用户的操作影响到另外一个用户(独立性,isolation),也不允许数据库的不完整操作(原子性,atomicity).
1.2. DBMS组成
组件概览
在书里面有"数据库管理系统组成"的一个架构图,但是因为不方便贴过来所以这里大致描述一下。不过倒也不用过于依赖这个架构图,架构图只不过是一个意思。
update@201509: 还是加上架构图吧, 一图胜千言. 那个时候没有智能手机, 不方便拍照. 科技进步了许多 ;)
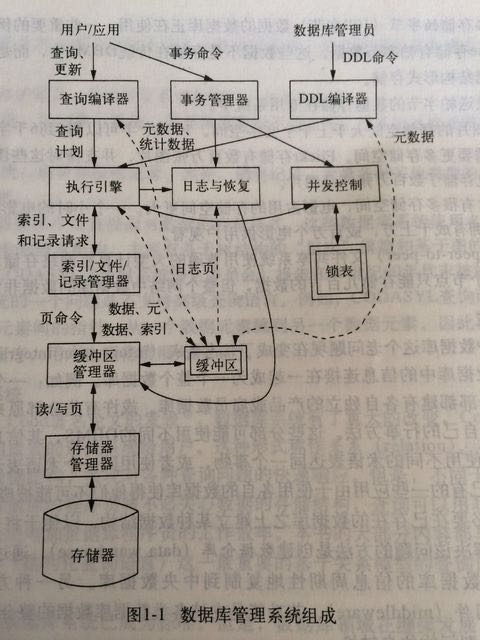
我觉得到没有必要从理解逻辑流的角度来看每个部件,而应该看看每个部件提供的功能分别是什么,然后反过来来看逻辑流。
- 查询编译器
- 事务管理器.接收事务命令来转换为执行引擎可以接收的plan.但是通常也需要并发控制,日志恢复的配合。
- DDL编译器.将DDL进行编译转换称为执行引擎可以接受的plan.
- 执行引擎.在执行plan的时候需要和日志(比如事务需要首先进行log)以及并发控制器(需要避免一些加锁的数据)之间交互.
- 日志与恢复.负责事务的持久性.在事务内部可以先将每一个变化都单独记录(log),如果中途失败或者是崩溃的话可以进行回滚,将数据库恢复到原来一直的状态.
- 并发控制调度器.保证事务的原子性和独立性.调度器可以保证多个事务的单个动作是按照某个次序执行,效果与系统一次只执行一个事务一样。
- 索引/文件/记录管理器.通过缓冲区管理器提供文件和记录的访问接口.同时它维护了一些索引和位置信息,通过这些信息可以查找到所需要的文件。
- 缓冲区管理器.通过存储管理器可以在上层进行buffer,实现上可能会包含若干个页面。
- 存储管理器.控制存储器行为,可以通过操作系统提供接口来完成,但是更加典型的是DBMS直接向磁盘控制器发出命令。
组件交互
各个组件之间可能需要的信息种类包括下面这些:
- 数据。数据库本身内容。
- 元数据。描述数据库结构以及约束的数据库模式。
- 日志记录。对数据库新近修改的信息,该信息支持数据库的持久性。
- 统计数据。DBMS收集和存储的关于数据特征的数据,比如数据库大小,数据库中的key range等.
- 索引。支持对数据库中数据有效存取的数据结构。
查询编译器
对于查询编译器需要将查询转换称为查询计划(query plan)的内部形式(对于query plan我们可以使用关系代数来理解).主要由下面三个模块组成:
- 查询分析器(query parser).从查询的文本结构构造一个查询树状结构
- 查询预处理器(query preprocessor).对查询树状结构进行语义检查,并且将查询语法树转换称为表示初始查询计划的代数操作符树。
- 查询优化器(query optimizer).查询优化器将查询初始计划转换称为在实际数据中更有效的操作序列。使用关于数据的元数据和统计数据,来界定那种操作序列最快。
事务处理器
对于事务处理器来说一般会执行下面这些任务:
- 日志记录(logging).为了保证持久性,数据库的每一个变化都会单独地记录在磁盘上面。而日志管理器可以在事务失败的时候来完成回滚。
- 并发控制(concurrency control).事务必须单独执行(这点是由原子性的性质来保证的ACID),但是为了可以高效完成,就是并发控制器的工作。典型的并发控制器会通过在数据库的某个片段上面加锁,防止两个事务对同一个数据片进行存取。通过锁会保存在主存的<锁表>中,调度器通过阻止执行引擎对已加锁的数据库内容的存取来影响查询和其他数据库操作。
- 消除死锁(deadlock resolution).当事务通过调度器获取锁以竞争资源时,系统可能会陷入死锁的状态。事务管理器有责任调解并且删除(回滚或者是终止)一个或者是多个事务,以便其他事务可以继续运行。
1.3. 事务性质
正确的事务通常应该满足一下ACID性质:
- A(atomicity).事务的操作要么被全部执行,要么全部不被执行。A set of changes must all succeed or all fail
- C(consistency).所有数据库中数据之间的联系具有一致性约束,或者是满足一致性期望。所以期望事物能保持数据库的一致性。Changes to data must leave the data in a valid state when the full change set is applied
- I(isolation).每个事物必须如果没有其他事务在同时执行一样被执行。The effects of a transaction must not be visible until the entire transaction is complete
- D(durability).一旦事物已经完成,则该事务对数据库的影响永远不会丢失。 After a transaction has been committed successfully, the state change must be permanent.
1.4. 本书概览
书主要是分三个部分来讨论的:
- 关系数据库模型。包括函数依赖(functional dependencies)说明一类数据唯一地由另外一个数据确定的形式化描述方法。规范化(normalization)表示用函数依赖和其他形式的依赖改进关系数据库设计的过程。高级的数据库设计方法实体/关系(E/R)模型,统一模型语言(UML)和对象定义语言(ODL),其目的是在关系DBMS设计实现之前,非形式化地探讨有关设计问题。
- 关系数据库程序设计。介绍基于袋鼠和逻辑抽象程序设计语言(关系代数和Datalog).讨论关系数据库标准语言SQL包括约束声明,触发器,索引和其他增加性能的结构,事务,数据安全和私有性。
- 半结构化数据建模和程序设计。Web的无处不在已经使得层次结构数据管理重新获得重视,这是因为Web标准是基于嵌套的标记元素。因为XML和它的模式标记文档类型DTD以及XML模式.讨论XML三种查询语言XPath,XQuery和可扩展的样式表转换语言(XSLT).
2. 关系数据模型
2.1. 数据模型
数据模型(data model)是用于描述数据或信息的标记,通常由三个部分组成:
- 数据结构(data structure).
- 数据操作(data operation).
- 数据约束(data constraint).
现在来说数据库中比较重要和有效的两个数据模型是:
- 关系数据模型,包括对象关系模型的拓展。(与之相关的操作成为关系代数)
- 半结构化数据模型,包括XML和相关标准。
其他的数据模型包括:
- 对象关系模型(object-relational data model).是将面向对象的特征加入到关系模型中,是的数据可以具有结构(层次结构)以及相关联的方法。
- 层次模型(hierarchical model).类似于半结构化数据模型,是一个基于树结构的模型。缺点是不像现在数据模型那样,它是真正在物理层次上进行操作。
- 网状模型(network model).它是一种基于图的位于物理层次上的模型。缺陷和层次模型同样,开发者不能在一个较高的层次上写出代码。
2.2. 关系模型
关系模型中的一些重要概念包括下面这些:我们可以将关系(relation)理解为二维表
- 属性(attribute).关系的列命名。比如title,year
- 模式(schema).关系名和其属性集合的组成。比如Movies(title,year).
- 元组(tuple).记录.比如(Matrix,2000).
- 域(domain).可以认为是这个属性类型.比如(string,int).
- 实例(instance).给定关系中元组的集合。通常数据库系统仅仅是维护关系的一个版本,即关系的"当前"元素集合,称为当前实例(current instance).相对应的饿是维护数据历史版本的数据库,因为是已经过时存在的,所以被称为临时数据库(temporal database).
- 键(key).键有关系的一组属性集组成,通过定义键可以保证关系实例上面任何两个元组的值在定义键的属性集上取值不同。比如(title+year)作为键。键是一种非常基本的约束。
SQL区分三类关系:
- 存储的关系,称为表(table).它在数据库中存储,用户能够对其元组进行查询和更新。
- 通过计算来定义的关系,称为视图(view).这种关系不在数据库中存储,它只是在需要的时候被完整地或者部分地构造。
- 临时表.在执行数据查询和更新时由SQL处理程序临时构造。这些临时表会在处理结束后被删除而不会存在数据库里面。
2.3. 关系代数
代数查询语言使用的是关系代数。虽然关系代数没有C/Java强大,但是通过对于查询语言做出某些限制,可以获得两个极为有益的回报,非常方便地进行开发以及能够编译产生高度优化的代码。 我们这里看一下关系代数提供的操作。
- 并(union)
- 交(intersection)
- 差(difference)
- 投影(projection)
- 选择(selection).
- 积(product)
- 连接(join).自然链接(natural join),theta连接(theta join)
- 重命名(renameing)
2.4. 关系约束
约束(constraint)即关系模型对于存储在数据库中的数据具有的约束能力。之前提到了键就是一种非常基本的约束。 另外一种常见的约束就是引用完整性约束(referential integrity constraint).引用完整性约束,规定的就是在某个上下文中出现的值也必须在另外一个相关的上下文中出现。 当然还有更多的语义上(应用层面上)的约束,通常这些约束应该是可以在SQL上描述出来的。
3. 关系数据库设计理论
#todo:
4. 高级数据库模型
#todo:
5. 代数和逻辑查询语言
#todo:
6. 数据库语言SQL
6.1. SQL简单查询
简单查询形式为SELECT L FROM R WHERE C.
- 数据源 FROM R.
- 投影 SELECT L.
- 选择 WHERE C.(模式匹配)
当然后面可以根据字段或者是表达式进行排序ORDER BY expr [ASC|DESC]
关于选择部分的话,我们有必要说说NULL以及涉及NULL的操作和比较。对空值NULL有许多不同的解释,下面是一些最常见的解释:
- 未知值(value unknown).知道它有一个值但是不知道是什么,比如一个未知的生日。
- 不适用的值(value inapplicable).仅仅是占位符,这个值是没有意义的。
- 保留的值(value withheld).属于某个对象但是无权知道的值。比如未公布的电话号码phone属性为NULL.
对于NULL的操作和比较:
- NULL和任何值进行运算操作结果为NULL
- NULL和任意值进行比较返回UNKNOWN.(TRUE | FALSE).
对于UNKNOWN理解的话,我们可以讲这个值理解为1/2.TRUE==1,FALSE==0.AND之间取结果最小的值,OR之间取较大的值,而NOT为1-x.
6.2. 多关系查询
多关系查询相当于联合多个关系来做查询。如果遇到关系的字段同名的话,我们可以通过rename或者是显示地写上qualified name来消除歧义。see "关系连接"
对于多关系查询解释模型的话有下面三种:
- 嵌套循环
- 并行赋值
- 转换为关系代数
但是针对某些情况这几种解释模型都不能够很好地工作。
6.3. 关系代数操作
update@201509: 不常用
SQL提供了对应的包并(UNION),交(INTERSECT),差(EXCEPT)关系代数操作用在查询结果上面,条件是要求这些查询结果提供的关系具有相同的属性和属性类型列表。 比如(SELECT name,address FROM MovieStar) EXCEPT (SELECT name,address FROM MovieExec).
6.4. 子查询
update@201509: 不常用. 大部分应用都可以使用JOIN表来完成, 而可读性更好.
在SQL中,一个查询可以通过不同的方式被用来计算另外一个查询。当某个查询时另外一个查询的部分时,称之为子查询(subquery).
- 子查询可以返回单个常量,这个常量能在WHERE子句和另外一个常量进行比较。
- 子查询能返回关系,该关系可以在WHERE子句中以不同的方式使用。EXISTS,IN,ALL,ANY.
- 子查询形成的关系能出现在FROM子句中,并且后面紧跟该关系元组变量(相当于rename).
6.5. 关系连接
update@201509: 关系操作产生新的关系, 比如 `(A JOIN B ON A.id == B.id AND A.f1 > 100 AND B.f2 < 200) AS R`. 然后使用普通查询语句作用在关系R上如 `SELECT A.f1, B.f2 FROM R`.
- A CROSS JOIN B.等同于<笛卡尔积>
- A JOIN B ON <expr>. AB做theta连接满足expr这个表达式.
- A FULL OUTER JOIN B ON <expr>. AB做theta外连接.
- A LEFT OUTER JOIN B ON <expr>.
- A RIGHT OUTER JOIN B ON <expr>.
- A NATURAL JOIN B.对AB中具有相同名字的属性进行自然连接(属性类型必须相同).
- A NATURAL FULL OUTER JOIN B.对AB进行自然外连接.
- A NATURAL LEFT OUTER JOIN B.
- A NATURAL RIGHT OUTER JOIN B.
6.6. 全关系操作
所谓权关系操作指将关系作为一个整体而不是单个元组或者是一定数量的元组进行操作。
- 消除重复.SELECT DISTINCE X.实际上从关系中消除重复的代价非常昂贵.
- 并,交,差的重复。默认情况下面UNION,INTERSECT,EXCEPT是会自动去重的,如果阻止去重的话后面可以加上ALL.
- 聚集.AVG(x),SUM(x).通常和分组共同使用。
- 分组.GROUP BY X. 然后在select属性的话对于非分组属性必须添加聚集操作符.
- HAVING子句。对于HAVING表达式属性必须和分组SELECT属性满足相同性质,HAVING自己用于选择分组中的部分元组。(对群组做筛选)
这里在讨论一下空值对于分组和聚集的影响:
- 空值NULL在任何聚集操作中都被忽视。
- 在分组的时候,空值NULL被作为一般值对待。
- 除了计数之外,对于空包执行的聚集操作结果为NULL,而COUNT为0.这点和1相关,假设SUM([NULL])的话,因为NULL被忽视所以为空包,那么返回结果是NULL.
6.7. 数据库更新
数据库更新操作有三种:
- 插入元组到关系中去。INSERT INTO R(a,b,c) VALUES(u,v,w).当然VALUES部分也可以使用子查询来替换。
- 从关系中删除元组。DELETE FROM R WHERE C.
- 修改某个元组的某些字段的值。UPDATE R SET a=u,b=u WHERE C.
6.8. SQL中的事务
关于事务引入的原因在之前介绍了并且也介绍了事务性质。我们来看看事务使用:
- START TRANSACTION.开始执行事务。
- COMMIT.如果希望提交之前执行语句的话。
- ROLLBACK.如果希望回滚之前执行语句的话。
另外SQL允许我们告诉系统接下来执行的事务是只读事务,SQL系统可以利用这点提高并发。通常多个访问同一数据的只读事务可以并行执行, 但是多个写统一数据的事务不能并行执行。默认情况的话都是SET TRANSACTION READ WRITE(读写事务).SET TRANSACTION READ ONLY(只读事务).
6.9. 事务隔离层次
事务的隔离层次会影响到该事务可以看到的数据。如果事务T在串行化层次上面执行的话,那么T的执行必须看起来好像所有其他事务要么完全在T 之前运行,要么完全在T之后运行。但是如果一些事务正运行在其他的隔离层次上的话,可以看到的数据是不同的。首先看看几种隔离层次(isolation level):
- 可串行化(serializable).事务必须完全在另外一个事务之前或者之后运行。SET TRANSACTION ISOLATION LEVEL SERIALIZABLE.
- 读未提交(read-uncommited).事务能够读取到其他未提交事务写入的数据。SET TRANSACTION ISOLATION LEVEL READ UNCOMMITED.
- 读提交(read-commited).只有那些已经提交事务写入的元组才可以被这个事务看到。SET TRANSACTION ISOLATION LEVEL READ COMMITED.
- 可重复读(repeatable-read).查询得到的每个元组如果在此查询再次执行时必须重现。SET TRANSACTION ISOLATION LEVEL REPEATABLE READ.
| 隔离级别 | 脏读 | 不可重复读取 | 幻影数据行 |
|---|---|---|---|
| READ UNCOMMITED | Y | Y | Y |
| READ COMMITED | N | Y | Y |
| REPEATABLE READ | N | N | Y |
| SERIALIZABLE | N | N | N |
update@201509: sqlite中的事务级别和这里说的事务隔离级别还有点区别. sqlite事务级别是按照实现而不是语义来定义的.
http://www.sqlite.org/lang_transaction.html
在sqlite里面存在三种级别事务:
- begin <description> transcation
- deferred
- immediate
- exclusive
Transactions can be deferred, immediate, or exclusive. The default transaction behavior is deferred. Deferred means that no locks are acquired on the database until the database is first accessed. Thus with a deferred transaction, the BEGIN statement itself does nothing to the filesystem. Locks are not acquired until the first read or write operation. The first read operation against a database creates a SHARED lock and the first write operation creates a RESERVED lock. Because the acquisition of locks is deferred until they are needed, it is possible that another thread or process could create a separate transaction and write to the database after the BEGIN on the current thread has executed. If the transaction is immediate, then RESERVED locks are acquired on all databases as soon as the BEGIN command is executed, without waiting for the database to be used. After a BEGIN IMMEDIATE, no other database connection will be able to write to the database or do a BEGIN IMMEDIATE or BEGIN EXCLUSIVE. Other processes can continue to read from the database, however. An exclusive transaction causes EXCLUSIVE locks to be acquired on all databases. After a BEGIN EXCLUSIVE, no other database connection except for read_uncommitted connections will be able to read the database and no other connection without exception will be able to write the database until the transaction is complete.
区别还是非常简单的:
- deferred 延迟上锁。在begin transcation之后其他的连接还可以发起begin transaction. 某个连接发起读操作就创建SHARED lock(之后只是可读,并且必须比RESERVED lock先释放), 发起写操作就创建RESERVED lock(之后可读可写,但是必须等待其他链接全部释放)
- immediate 立刻上锁。相当立刻占用RESERVED lock,其他链接可以发起begin trasnaction但是只能够获得SHARED lock,并且和之前一样,必须等待shared lock释放,requoted lock才能够释放。 note:这点非常实际,因为对于发起SHARED lock而言,肯定希望期间读取的数据不会发生变化 note:似乎如果直接执行SQL语句相当加上immediate transaction
- exclusive 排斥上锁。排斥其他连接发起任何transaction,相当于lock table.
7. 约束与触发器
在SQL中允许创建"主动"元素的相关内容。主动(active)元素是一个表达式或者语句,该表达式或语句只需要编写一次存储在数据库中,然后在适当的时间执行。主动元素的执行可以是由于某个特定时间引发,如对关系插入元组,或者是当修改数据库的值引起某个逻辑值为真等。在SQL中存在两种"主动"元素分别是约束(完整性约束,integrity constraint)与处触发器。
- 键约束.如果两个元组键相同的话那么元组必须相同。
- 外键约束(foreign-key constraint).指一个关系中出现的一个属性或一组属性也必须在另外一个关系中出现。
- CHECK约束(check constraint).属性或者是元组上的约束。
- 断言(assertion).关系之间的约束。
- 触发器(trigger).触发器是主动元素的一种,它在某个特定事件发生时被调用,例如对一个特定关系的插入事件。
7.1. 约束命名
对于任何约束的话我们都可以为其命名,方式是CONSTRAINT <name<> <constraint-content>.比如
name CHAR(30) CONSTRAINT hello nameIsKey PRIMARY KEY.
这样hello就是这个CONSTRAINT.我们对约束指定检查时机.默认是立即检查。
- SET CONSTRAINT hello NOT DEFERRABLE.立即检查.
- SET CONSTRAINT hello DEFERRABLE INITIALLY DEFERRED.检查被仅仅被推迟到事务提交之前执行。
- SET CONSTRAINT hello DEFERRABLE INITIALLY IMMEDIAtE.检查在事务每条语句之后都立即执行。
我们允许在ALTER TABLE里面来修改约束包括ADD,DROP.
7.2. 外键约束
外键约束用于判定一个关系中出现的值也必须在另外一个关系的主键中出现,在SQL中可以将关系中的一个属性或者是属性组声明外键(foreign key),该 外键引用另外一个关系(也可以是同一个关系)的属性(组)(必须是主键).创建外键约束有两种方式
- 在定义属性时在该属性后面加上REFERENCES <table> (field)
- 在CREATE TABLE末尾追加声明FOREIGN KEY (field1,field2) REFERNECES <table>(field1,field2).
我们来考虑在进行数据库更新时如果发生外键约束失败情况下面DBMS的处理。<注意这种修改仅仅发生在键所在关系上面,如果发生在引用的关系上面的话,那么全部拒绝>.DBMS有下面几种处理方式:
- 缺省原则(the default policy),即拒绝违法更新(reject violating modification).即阻止这个更新的发生。
- 级联原则(the cascade policy). 在该原则下面,被引用属性(组)的改变被仿造到外键上面。CASCADE.
- 置空置原则(the set-null policy). 在该原则下面将外键置空。SET NULL
然后也可以选择时机ON DELETE以及ON UPDATE.通常来说,ON DELETE SET NULL ON UPDATE CASCADE.对于外键约束来说的话也可以延迟约束的检查。
7.3. CHECK约束
CHECK约束包括基于属性的约束(attributed-based CHECK constraint)以及基于元组的约束(tuple-based CHECK constraint).基于属性的约束首先 有一个非NULL约束,使用很简单就是name CHAR(30) NOT NULL.而除此之外,基于属性和基于元组的约束表达上非常相似。比如下面
#基于元组约束 CREATE TABLE R( name CHAR(30) PRIMARY KEY, gender CHAR(1), CHECK (gender='F' or name NOT LIKE 'Ms.%')) #基于属性约束 CREATE TABLE R( name CHAR(30) PRIMARY KEY, gender CHAR(1), CHECK (gender='F'))
注意CHECK约束仅仅是在这个关系的元组发生变化时候才会触发检查,如果其他关系而造成这个CHECK约束失败的话是不会触发检查的。也就是说 CHECK约束仅仅是针对某一个关系的而不是针对于数据库的。如果需要针对数据库进行检查的话,那么可以使用断言。
7.4. 断言
公平地说触发器可以完成断言的功能,因为触发器是DBMS作为通用目的主动元素,可以说断言是触发器的特化。但是断言非常便于程序员使用, 然后而断言的有效实现非常地困难。断言就是SQL逻辑表达式,并且总是为真。
- CREATE ASSERTION <name> CHECK <condition>
- DROP ASSERTION <name>
下面是CHECK约束和断言的差异
| 约束类型 | 声明位置 | 动作时间 | 确保成立 |
|---|---|---|---|
| 基于属性CHECK | 属性 | 对关系插入元组或者是属性修改 | 如果是子查询则不能确保 |
| 基于元组CHECK | 关系模式元素 | 对关系插入或者是属性修改 | 如果是子查询则不能确保 |
| 断言 | 数据库模式元组 | 对任何提及的关系做改变时 | 是 |
7.5. 触发器
触发器有时候也被称为事件-条件-动作规则(event-condition-action rule)或者是ECA规则。程序员可以选择动作执行的方式:
- 一次只针对一个更新元组(row-level trigger,行级触发器)
- 一次针对在数据库操作中被改变的所有元组(statement-level trigger,语句级触发器).通过一个SQL更新语句影响多个元组。
通过一个例子来稍微分析一下吧.
CREATE TRIGGER X # 创建触发器 AFTER UPDATE OF y ON R #这里可以是AFTER,BEFORE以及INSTEAD OF(视图里面会提及到). 可以是UPDATE OF(可以指定属性)/INSERT/DELETE(只能和元组相关) REFERENCING OLD ROW AS OldTuple # 如果是UPDATE可以有前后的ROW.如果是INSERT那么只有NEW ROW.如果是DELETE那么只有OLD ROW. NEW ROW AS NewTuple FOR EACH ROW # 如果是FOR_EACH STATEMENT那么就是语句级触发。对于语句触发的话可以使用OLD TABLE和NEW TABLE来引用。 WHEN (OldTuple.y > NewTuple.y) # 如果想执行多条语句的话那么需要使用BEGIN/END来包括,语句之间使用;来分隔。 UPDATE R SET y = OldTuple.y WHERE z = '007'
注意触发器的动作也算是事务本身的一部分。事务的范围可能由于数据库模式中存在触发器或者其他主动元素而受到影响。 如果事务中包括修改动作,而这个动作导致一个或者是多个触发器被激发的话,那么触发器的动作也是事务的一部分。 在某些系统中,触发器可以级联,其结果是一个触发器激发另外一个触发器。如果这样,那么所有这些动作都成为那些触发 这一系列触发器的事务的一部分。
8. 视图与索引
8.1. 虚拟视图
虚拟视图是由其他关系上的查询所定义的一种关系。虚拟视图并不在数据库中进行存储,但是可以对其进行查询,就好像它确实被存在数据库中一样。查询处理器也会在执行查询时用视图的定义来替换视图。CREATE VIEW <name> AS <视图定义>可以用来创建视图(删除视图DROP VIEW <name>)。视图看上去像是table所以用户可能想进行insert/update/delete. 不过因为视图本身就是一个虚拟table, 所以进行更新操作陷阱会比较多. 但是我觉得为了简化我们的理解以及使用最好就先定视图只允许查询。如果我们确实想更新视图的话,我们可以使用触发器INSTEAD OF来截获对于视图本身的修改。
8.2. 物化视图
对于虚拟视图而言,每次查询底层查询解释器都会翻译称为子查询,效率无疑很低。如果我们可以将这个虚拟视图存储下来,并且维护好这个视图和原始table之间的关系,那么就能够提高效率了。所谓的物化(materialized)就是在任何时间都保存它的值,当基本表发生变化时,每次必须重新计算部分物化视图,因此维护物化视图也需要一定的代价。对于某些场景我们可以选择不去立即更新物化视图, 可以推迟积累一段时间变化batch地更新.
8.3. 索引
update@201509: 区分索引的键和关系的键. 索引键是用来指定索引的, 而关系的键是用作唯一标识的.
索引就是一种特殊的物化视图,使用索引可以使得查询速度加快。但是不像普通的物化视图一样我们需要显式地区使用,DBMS会自动使用索引。创建索引非常简单CREATE INDEX <name> ON R(f1,f2). 删除索引DROP INDEX <name>. 通常来说我们倾向于在关系的键上面创建索引。使用索引方面,我们需要考虑到索引带来的性价比,因为索引本身通常也会存放在磁盘上面,占用磁盘空间,并且随着数据变化也需要不断更新. 正确地选择索引对于优化查询是非常重要的。
9. 服务器环境下的SQL
#todo:
10. 关系数据库的新课题
#todo:
11. 半结构化数据模型
半结构化数据(semistructured-data)模型在数据库系统中有独特的地位:
- 它是一种适于数据库集成(integration)的数据模型,也就是说,适用于描述包含在两个或者多个数据库(这些数据库含有不同模式的相似数据)中的数据。
- 它是一种标记服务的基础模型,用于在Web上共享信息。
半数据化结构相对于固定模型来说响应查询性能较差,但是我们对其感兴趣的动机在于它的灵活性。因为半数据化是自描述的(self-describing). 它自身携带了关于其模式的信息,并且这样的模式可以随时间在单一数据库内任意改变。
半结构化最典型的例子就是XML(Extensible Markup Language).我们这里对XML不打算更进一步地进行描述。为了让计算机能够自动处理XML文档, 让文档有类似于模式的信息则非常有帮助,比如每个标签的元素类型是什么以及标签之间是如何相互嵌套的。而这个模式的描述则成为文档类型定义 DTD(Document Type Definition).而XML模式(XML Schema)则是另外一种为XML文档提供模式的方法,它的功能比DTD更加强大,给模式设计者提供更多的功能。
12. XML程序设计语言
对于数据模型的话除了数据结构之外,还需要提供数据定义以及数据查询的功能。因为半结构化数据模型本身就是自描述的,所以没有特殊的数据定义。 所以我们这里看看在半结构化数据模型上的数据查询。同样我们以XML为例来了解几种数据查询与操作方法:
- XPath.XPath是一种通过路径表达的方式来获取数据(可以得到一个元素,或者是一个子XML文档).路径表示内部提供了丰富的功能。
- XQuery.XQuery可以说是XPath的超集,在XPath上面定义了更多的逻辑表达能力,支持变量,循环控制等,应该是turing-complete的。
- XLST(Extensible Stylesheet Language Transformations)允许对XML文档进行转换。