C-Store: A Column-oriented DBMS
C-Store按照列进行存储,但是为了加速分析,对列进行了replication. 多个列可以归为到一个projection下面,然后可以存储多种projection. 这种方式的好处是,一方面可以提高数据的可靠性,另外一方面如果query正好只需要查询这几列,那么data footprint就非常少,相应的overhead也就非常少。
读和写是两个不同的Store. 读是RS(read-optimized store), 写是WS(writable store). 我的理解是,WS是按照行进行存储的(LSM),而RS则是按照列进行存储的,转换的过程是经过一个叫做Tuple Mover的东西。Tuple Mover会将行拆分成为列,并且在列上会存储 RowId (论文里面是segment id + segment key,本质上就是定位一条行记录)。我在想既然存储了RowId,那么可能C-Store会使用late-materialzation,在查询的过程中会进行回表。
projection表示一系列columns的聚合,于此同时在上面指定了columns的排序方式。比如下面EMP1是name + age两列,按照按照age进行排序。这种写法是C-Store的写法,之后涉及到C-Store的论文估计估计都会这么写。
EMP1(name, age| age) EMP2(dept, age, DEPT.floor| DEPT.floor) EMP3(name, salary| salary) DEPT1(dname, floor| floor)
projection在存储的时候也被进行了水平拆分成为多个partition, 拆分依据是使用sort key range. 每个partition被成为一个segment, 就是之前提到的segment id. 然后在segment里面会被分配到单调递增的key. sid + sk就可以唯一确定行。WS和RS数量是相同并且是一一对应的,WS那边分配segment key, 然后直接写入到RS里面。
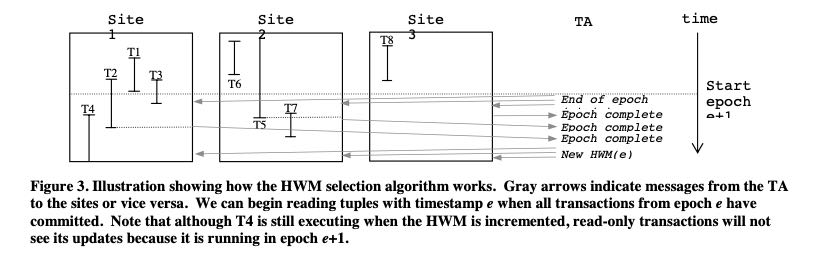
C-Store实现快照隔离。为了了解当前最新的tiemstamp, 有个TA(timestamp authority)来分配time epoch. 每隔一段时间TA会给所有的WS发送当前time epoch. 此时WS可以将当前积累的数据以这个time epoch写入,然后通知TA. TA等待所有的WS返回成功之后,然后告诉所有WS这个time epoch是可以visiable.
在查询优化上,C-Store还提到在compressed data上进行查询。这个和我之前理解的在compressed data上查询不同,我以为是在general compressed data比如snappy,lz4这种压缩数据上操作,而实际是在RLE, bitmap, bit-packing这类压缩数据上做查询。后面还有一篇文章《Integrating Compression and Execution in Column-Oriented Database Systems, 2006》讲关于如何在这些压缩数据上操作。