Java核心技术卷2-高级特性
Table of Contents
1. 对象序列化
对象的序列化涉及的接口有:
- implements Serializable,方法 readObject/writeObject 来实现对象本身的序列化
- implements Externalizable,方法readExternal/writeExternal 来实现包括超类的序列化
- readResolve 在读取对象上来之后可以做必要的二次处理
在序列化的过程中会产生对象的唯一ID,这个ID根据类的属性和方法描述通过SHA生成。也就是说,如果class A序列化生成data之后,如果class A改变了定义的话,那么唯一ID则对应不上data则没有办法读取上来。不过有时候我们希望可以向后兼容,解决办法就是自己指定唯一ID。我们只需要在类里面增加一个 `public static final long serialVersionUID = 1L` 就行,这样写入data里面的唯一ID用的就是这个数值。 对于不识别的字段就直接丢弃,对于新增的字段则使用默认值来填充。
public class SerialTester {
@ToString
public static class A implements Serializable {
public static final long serialVersionUID = 100L;
String name;
int value;
// added later
int value_ex1;
String value_ex2;
}
public static void writeA() {
try {
A x = new A();
x.name = "hello";
x.value = 99178;
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("A.data"));
oos.writeObject(x);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void readA() {
try {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("A.data"));
A x = (A) ois.readObject();
// SerialTester.A(name=hello, value=99178, value_ex1=0, value_ex2=null)
System.out.println(x.toString());
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// writeA();
readA();
}
}
2. 类加载器和字节码校验
虚拟机只加载程序执行所需要的类文件,比如程序从MyProgram.class开始运行的话:
- 虚拟机有一个用于加载类文件的机制,比如从本地磁盘或者是网络上拿到。
- 如果MyProgram引用到其他类型的对象的话(包括继承和组合),那么这些类也会被加载
- 然后执行MyProgram中的main方法,在运行过程中使用到的类也会被不断地加载进来。
但是类加载机制并非只有一个类加载器,至少拥有3个:
- 引导类加载器,C语言编写的加载器,加载rt.jar
- 扩展类加载器,从jre/lib/ext目录加载标准的扩展jar
- 系统类加载器,也称应用加载器,加载CLASSPATH里面的jar
public class ClassLoaderTester {
public static void printLoader(Class cls) {
System.out.println("print loader of class " + cls.getCanonicalName());
ClassLoader loader = cls.getClassLoader();
while (loader != null) {
System.out.println("---> " + loader.toString());
loader = loader.getParent();
}
System.out.println();
}
public static void main(String[] args) {
printLoader(ClassLoaderTester.class);
printLoader(EventID.class);
printLoader(ArrayList.class);
}
}
输出如下
print loader of class org.aap.examples.ClassLoaderTester ---> sun.misc.Launcher$AppClassLoader@2a139a55 ---> sun.misc.Launcher$ExtClassLoader@7852e922 print loader of class com.sun.java.accessibility.util.EventID ---> sun.misc.Launcher$ExtClassLoader@7852e922 print loader of class java.util.ArrayList
类加载器是存在层次结构的,从上向下查找,父类失败了才会使用子类加载器。利用类加载器,我们可以很容易地实现插件机制,比如我们可以指定某个plugin.jar里面某个特殊的类为插件入口。 此外不同的类加载器的名字空间是分开的,也就是说两个同名(包括package名称)相同的类,可以存在于两个类加载器中(或者是plugin.jar中)而不冲突。
下面是一个加载插件的示例代码,有两点需要注意:
- 因为类加载器的顺序从从上向下,所以如果你的代码里面有某个类的话,那么就不回去plugin.jar里面查找。
- 这里调用静态非常非常tricky, 如果是null的话一定要强转成为Object类型。
public static void main(String[] args) {
try {
URL url = new URL("file:///Users/zhyanzy/plugin.jar");
URLClassLoader loader = new URLClassLoader(new URL[]{url});
Class cls = loader.loadClass("com.ooo.xxx.Test");
System.out.println(cls.getClassLoader().toString());
for (Method m : cls.getMethods()) {
System.out.println(m.getName() + ": pc = " + m.getParameterCount());
}
Method m2 = cls.getDeclaredMethod("main", String[].class);
System.out.println(m2.toString());
// note: so tricky
m2.invoke(null, (Object) null);
} catch (Throwable e) {
e.printStackTrace();
}
最后你可以编写自己的类加载器,而不只是使用URLClassLoader.
- 继承ClassLoader, 实现 `findClass` 方法。这个方法是父类无法加载的时候才会去被调用。
- `findClass` 要求输入一个name, 然后返回Class.
- 但实际上你还可以使用 `defineClass` 这个方法,你只需要传入一个字节流,就会返回Class.
连接Java语言和平台之间的纽带是统一的类文件(即.class文件)格式定义。认真研究类文件的定义能让你获益匪浅,这是优秀Java程序员向伟大Java程序员转变的一个途径。图1-1展示了产生和使用Java代码的整个过程。
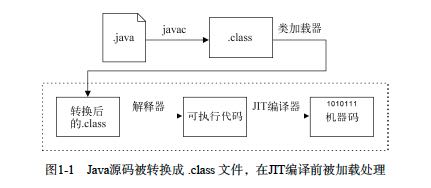
如图所示,Java代码的演进过程从我们可以看懂的Java源码开始,然后由javac编译成.class文件,变成可以加载到JVM中的形式。值得注意的是,类文件在加载过程中通常都会被处理和修改。大多数流行框架(特别是打着“企业级”旗号的)都会在类加载过程中对类进行改造。
3. 编译/运行时/字节码注解
注解是那些插入到源代码中用于某种工具处理的标签。这些标签可以在源码层次上操作,或者可以请求编译器将它们纳入到直接类文件中。
注解不会改变对编写的程序的编译方式,Java编译器对于包含注解和不包含注解会生成相同的虚拟机指令。
既然注解不会影响到虚拟机指令的生成,那么注解到底有什么用途呢?我觉得可以从3类注解入手:
- 编译时注解,典型的就如Lombok这类插件。本质上它就是可以帮你生成扩展的Java文件。这类注解编译成为class之后就会被丢弃。
- 运行时注解。因为注解被留在了class上面,那么我们可以通过反射功能来动态生成某些代码或者是逻辑。 JVM在加载class的时候不会丢弃这些注解。
- 字节码注解。通过分析class以及上面的注解,我们可以增加或者删除部分字节码,来改变这个class的行为。JVM在加载class的时候会丢弃这些注解。
上面3类注解对应的就是 @Retention 保留策略:
- SOURCE 对应的就是编译时注解,不包含在类文件中。
- CLASS 对应的就是字节码注解,类文件中保留,但是虚拟机不需要。
- RUNTIME 对应的是运行时注解,虚拟机在加载的时候也要保留。
很长一段时间我对编译时注解很困惑,知道看了这本书才搞明白。原来javac提供了某种机制,可以让你在基本编译完成Java文件之后,将这些Class文件喂给注解处理器。 这个注解处理器可以定义“我关注那些注解”,然后javac会将含有这类注解的类/字段传给注解处理器来处理,注解处理器可以选择性地生成新的Java文件。如果javac发现 注解处理器如果生成了新的文件,那么又会继续上面的过程,知道没有任何Java文件产生。
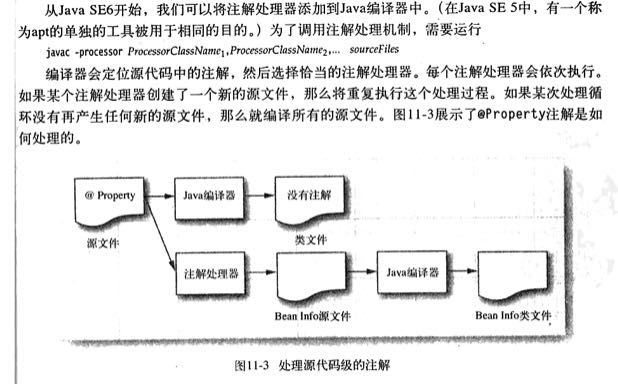
下面是我写的一个示例代码,它会收集含有 @APTData 的注解,并且将包含这些注解的class名称收集到一个类 `APTDataCollector` 里面去。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.SOURCE)
public @interface APTData {
}
@SupportedAnnotationTypes("org.aap.examples.APTData")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class APTDataProcessor extends AbstractProcessor {
@Override
public boolean process(final Set<? extends TypeElement> annotations, final RoundEnvironment roundEnv) {
ArrayList<String> names = new ArrayList<>();
for (TypeElement t : annotations) {
for (Element e : roundEnv.getElementsAnnotatedWith(t)) {
names.add(((TypeElement) e).getQualifiedName().toString());
}
}
if (names.size() == 0) {
return false;
}
try {
JavaFileObject sourceFile = processingEnv.getFiler().createSourceFile("org.aap.examples.APTDataCollector");
PrintWriter out = new PrintWriter(sourceFile.openWriter());
out.print("package org.aap.examples;\n");
out.print("public class APTDataCollector {\n");
out.print("public static final String[] names = {\n");
for (String n : names) {
out.print("\"" + n + "\",\n");
}
out.print("};\n}\n");
out.close();
} catch (IOException e) {
e.printStackTrace();
return false;
}
return true;
}
}