Coding for SSD
Table of Contents
- http://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
- http://blog.jobbole.com/63520/ 非常棒的中文翻译
1. Structure of an SSD
1.1. NAND-flash memory cells
- 固态硬盘(SSD)是基于闪存的数据存储设备。每个数据位保存在由浮栅晶体管制成的闪存单元里。SSD整个都是由电子组件制成的,没有像硬盘那样的移动或者机械的部分。
- 在浮栅晶体管中,使用电压来实现每个位的读写和擦除。写晶体管有两个方法:NOR闪存和NAND闪存。
- NAND闪存模块的一个重要特征是,他们的闪存单元是损耗性的,因此它们有一个寿命。实际上,晶体管是通过保存电子来实现保存比特信息的。在每个P/E循环(Program/Erase,“Program”在这表示写)中电子可能被晶体管误捕,一段是时间以后,大量电子被捕获会使得闪存单元不可用。
- 目前业界中的闪存单元类型有:
- 单层单元(SLC),这种的晶体管只能存储一个比特但寿命很长。(也意味着成本更高)
- 多层单元(MLC),这种的晶体管可以存储3个比特,但是会导致增加延迟时间和相对于SLC减少寿命。
- 三层单元(TLC),这种的晶体管可以保存3个比特,但是会有更高的延迟时间和更短的寿命。
- 闪存的模块组织在被称为块(Block)的格子中,而块则组织成平面(Plane)。块中可以读写的最小单元称为页(Page)。页不能独立擦除,只能整块擦除。NAND闪存的页大小可能是不一样的,大多数硬盘的页大小是2KB, 4KB, 8KB 或 16KB。大多数SSD的块有128或256页,这即表示块的大小也可能是256KB和4MB之间不同的值。例如Samsung SSD 840 EVO的块大小是2048KB,而每个块有256个8KB的页。
1.2. Organization of an SSD
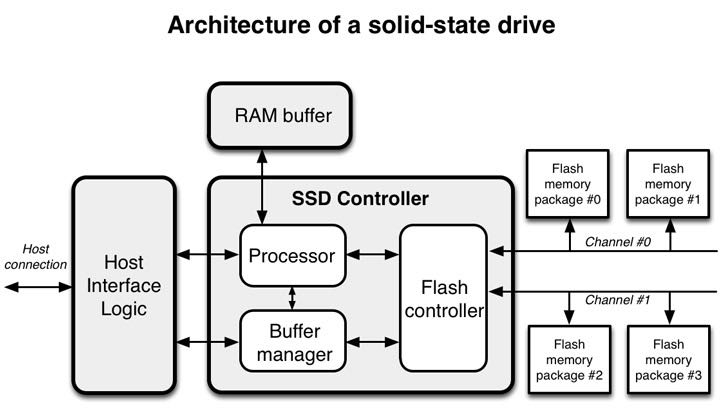
- 来自用户的命令是通过主机接口(Host Interface Logic)交换的。在我写这篇文章的时候,最新发布的SSD有两种最普遍的接口:SATA和PCIe
- SSD控制器中的处理器接收这些命令并将它们传递给闪存控制器(Flash controller)。
- SSD同样内嵌有RAM存储器(RAM buffer),通常是作为缓存和存储映射信息使用。
- NAND闪存芯片(flash memory package)通过多个通道(channel)组织在一起。
下图是the 512 GB version of the Samsung 840 Pro SSD, released in August 2013. As it can be seen on the circuit board, the main components are: # 和上面的架构图完全对应:)
- 1 SATA 3.0 interface
- 1 SSD controller (Samsung MDX S4LN021X01-8030)
- 1 RAM module (256 MB DDR2 Samsung K4P4G324EB-FGC2)
- 8 MLC NAND-flash modules, each offering 64 GB of storage (Samsung K9PHGY8U7A-CCK0)


下图是a Micron P420m Enterprise PCIe, released late 2013. The main components are:
- 8 lanes of a PCI Express 2.0 interface
- 1 SSD controller
- 1 RAM module (DRAM DDR3)
- 64 MLC NAND-flash modules over 32 channels, each module offering 32 GB of storage (Micron 31C12NQ314 25nm)
- The total memory is 2048 GB, but only 1.4 TB are available after over-provisioning.


1.3. Manufacturing process
2. Benchmarking and performance metrics
2.1. Basic benchmarks
- 影响性能的一个重要因素是接口。最新发布的SSD最常使用的接口是SATA3.0和PCI Express 3.0
- 使用SATA3.0接口时,数据传输速度可以达到6 Gbit/s,而在实际上大概能够达到550MB/s
- 而使用PCIe 3.0可以达到每条8 GT/s,而实际上能达到大概1 GB/s(GT/s是指G次传输(Gigatransfers)每秒)。使用PCIe 3.0接口的SSD都会使用不止一条通道。使用4条通道的话(译注:PCIe 3.0 x4),PCIe 3.0可以提供最大4 GB/s,的带宽,相当于SATA3.0的八倍。
- 一些企业级的SSD同样提供串行SCSI接口(SAS),最新版本的SAS可以提供最高12 GBit/s的速度,但是现在SAS的市场占有量很小。
- 大部分近期的的SSD的内部速度可以满足550 MB/s的SATA3.0限制,因此接口是其速度瓶颈。使用PCI Express 3.0或者SAS的SSD可以提供巨大的性能提升。
2.2. Pre-conditioning(预处理)
正确评估SSD的性能并非易事。硬件评测博客上的很多文章都是在硬盘上随机写十分钟,便声称硬盘可以进行测试,并且测试结果是可信的。然而SSD性能只会在足够长时间的随机写工作负载下才会有性能降低,而所需的时间基于SSD的总大小会花费30分钟到3小时不等。这即是更多认真的基准性能测试开始于相当长时间的随机写负载(称为“预处理”)的原因。下图显示出在多个SSD上预处理的效果。可以看见在30分钟左右出现了明显的性能下降,所有硬盘都出现读写速度下降和延迟上升。之后的四个小时中,硬盘性能缓慢降低到一个最小的常量值。
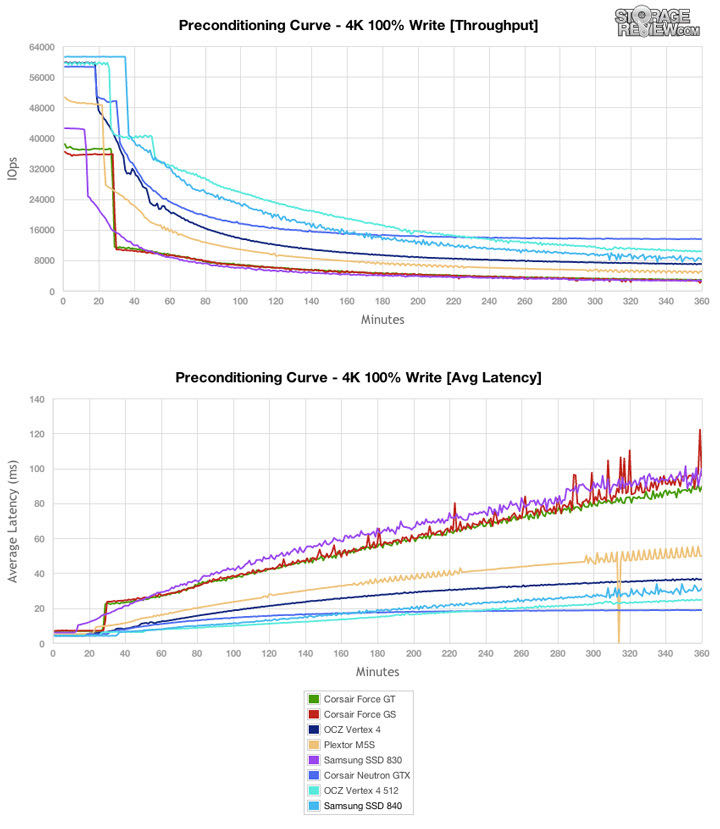
5.2节解释了图7中实际上发生的事情,随机写入的量太大并以这种持续的方式进行使得垃圾回收进程不能维持在后台。因为必须在写命令到达时擦除块,因此垃圾回收进程必须和来自主机的工作在前台的操作竞争。使用预处理的人声称基准测试可以代表硬盘在最坏的情况下的表现。这种方法在所有工作负载下是否都是好模型还是值得商榷。
为了比较不同制造商的各种产品,找到可以比较的共同点是必要的,而最坏的情况是一个有效的共同点。然而选择在最糟糕的工作负载下表现最好的硬盘并不能保证其在生产环境下所有的工作负载下都表现的最好。实际上大部分的生产环境下,SSD硬盘只会在唯一的一个系统下工作。因其内部特征,这个系统有一个特定的工作负载。因此比较不同硬盘的更好更精确的方法是在这些硬盘上运行完全相同的工作负载,然后比较他们表现的性能。 这就是为何,即使使用持续的随机写工作负载的预处理可以公平的比较不同SSD,但还是有一点需要注意,如果可以的话,运行一个内部的基于目标工作负载的基准测试。为了比较不同制造商的各种产品,找到可以比较的共同点是必要的,而最坏的情况是一个有效的共同点。然而选择在最糟糕的工作负载下表现最好的硬盘并不能保证其在生产环境下所有的工作负载下都表现的最好。实际上大部分的生产环境下,SSD硬盘只会在唯一的一个系统下工作。因其内部特征,这个系统有一个特定的工作负载。因此比较不同硬盘的更好更精确的方法是在这些硬盘上运行完全相同的工作负载,然后比较他们表现的性能。 这就是为何,即使使用持续的随机写工作负载的预处理可以公平的比较不同SSD,但还是有一点需要注意,如果可以的话,运行一个内部的基于目标工作负载的基准测试。
内部基准测试同样可以通过避免使用“最好的”SSD来避免过度调配资源,譬如当一个比较便宜的SSD型号已经足够并且能够省下一大笔钱的时候。
2.3. Workloads and metrics
性能基准都有相同的参数,并使用相同的度量。通常使用的参数如下:
- 工作负载类型:可以是基于用户控制数据的指定性能基准,或者只是顺序或者随机访问的性能基准(例:仅随机写)
- 读写百分比(例:30%读70%写)
- 队列长度:在硬盘上运行命令的并发执行线程的数量
- 访问的数据块大小(4KB, 8KB等)
通常使用的度量如下:
- 吞吐量:数据传输的速度,通常单位是KB/s或MB/s,表示千字节每秒和百万字节每秒。这个指标常用在顺序读写基准测试中。
- IOPS:每秒读写操作的数量,每个操作都是相同大小的数据块(通常是4KB/S)。这个指标通常用在随机读写基准测试中。
- 延迟:在发送完命令后设备的反应时间,通常是μs或ms,表示微秒或者毫秒。
3. Basic operations
3.1. Read, write, erase
- 读是以页大小对齐的。一次读取少于一页的内容是不可能的。操作系统当然可以只请求一字节,但是SSD会访问整个页,强制读取远超所需的数据。
- 写是以页大小对齐的。将数据写入SSD的时候,写入的增量也是页大小。因此即使一个写入操作只影响到一个字节,无论如何整个页都会写入。写入比所需更多的数据的行为被称为写入放大(amplification)。
- 页不能被复写。NAND闪存页只有在其“空闲”着的时候才能写入。当数据被修改时,这页的内容被拷贝到一个内部寄存器,此时数据更新而新版本的数据存储在一个“空闲”的页中,这被称为“读-改-写”操作。数据并非就地更新,因为“空闲”页与原来存储数据的页不是同一个页。一旦数据被硬盘保存,原先的页被标记为“stale(意为 腐败的 不新鲜的)”,直到其被擦除。(和OS删除文件不同。OS删除文件SSD是没有办法知道的,除非SSD支持TRIM指令。修改操作SSD是可以知道原来的page已经变为无效page)
- 擦除以块对齐。页不能被复写,而一旦其成为stale,让其重新空闲下来的唯一方法是擦除他们。但是对单个页进行擦除是不可能的,只能一次擦除整个块。在用户看来,访问数据的时候只有读和写命令。擦除命令则是当SSD控制器需要回收stale页来获取空闲空间的时候,由其垃圾回收进程触发。
3.2. Write amplification
因为写入是按页大小对齐的,任何没有对齐一个或者多个页大小的写操作都会写入大于所需的数据。写一个字节最终导致一整页都要写入,而一页的大小在某些型号的SSD中可能达到16KB,这是相当没有效率的。而这不是唯一的问题。除了写入过多的数据外,这些额外的写入也会触发更多不必要的内部操作。实际上,用未对齐的方法写入数据会导致在更改和写回硬盘之前需要页读到缓存(因为我们只是修改了部分内容,所以原来内容我们需要读上来,合并然后写入新页),这比直接写入硬盘要慢。这个操作被称为读-改-写,且应该尽可能的避免。 # 似乎唯一能做的就是将small writes聚合称为batch write.
- 绝不进行少于一页的写入。避免写入小于NAND闪存页大小的数据块来最小化写入放大和读-改-写操作。现在一页的大小最大的是16KB,因此这个值应作为缺省值使用。闪存页大小的值基于SSD型号并且在未来SSD发展中可能会增加。
- 对齐写入。以页大小对齐写入,并写入大小为数个页大小的数据块。#todo: 有办法控制吗???
- 缓存化小写入。为了最大化吞吐量,尽可能的将小数据写入RAM缓存中,当缓存满了之后执行一个大的写入来合并所有的小写入。
3.3. Wear leveling(损耗均衡)
想象一下我们有一个SSD,数据总是在同一个块上写入。这个块将很快达到其P/E循环限制、耗尽。而SSD控制器井标记其为不可用。这样硬盘的容量将减小。想象一下买了一个500GB的硬盘,过了几年还剩250G,这会非常恼火。因此,SSD控制器的一个主要目标是实现损耗均衡,即是将P/E循环在块间尽可能的平均分配。理想上,所有的块会在同一时间达到P/E循环上限并耗尽。
为了达到最好的全局损耗均衡,SSD控制器需要明智的选择要写入的块,且可能需要在数个块之间移动,其内部的进程会导致写入放大的增加。因此,块的管理是在最大化损耗均衡和最小话写入放大之间的权衡。因为NAND闪存单元会耗尽,FTL(Flash Translation Layer)的一个主要目标是尽可能平均的将工作分配给各个闪存单元,这样使得各个块将会在同一时间达到他们的P/E循环限制而耗尽。
4. Flash Translation Layer(FTL)
FTL有两个主要的作用:逻辑块寻址和垃圾回收
4.1. Logical block mapping
逻辑块映射将来自主机空间的逻辑块地址(LBA)转换为物理NAND闪存空间的物理块地址(PBA)。为了访问速度,这个映射表保存在SSD的RAM中,并保存在闪存中以防电源故障。当SSD启动后,这个表从闪存中读出并在SSD的RAM中重建。
一个比较简单的方法是使用页级映射来将主机的所有逻辑页映射为物理页。这个映射方法提供了很大的灵活性,然而主要的缺点是映射表需要大量的内存,这会显著地增加生产成本。一个解决方案是使用块级映射不再对页,而是对块进行映射。假设一个SSD硬盘每个块有256个页。这表示块级映射需要的内存是页级映射的256分之一,这是内存使用的巨大优化。然而这个映射仍然需要保存在硬盘上以防掉电。同时,以防大量小更新的工作负载,无论页是否是满的,全部闪存块都会写入。这会增加写入放大并使得块级映射普遍低效。
页级映射和块级映射的折中其实是在性能和空间之间折中的一个表现。一些研究者试着在两个方面都能够最佳化,得到了称为“hybrid(混合)”的方法。最普遍的是日志块映射,其使用了一种比较像日志结构文件系统的方法。输入的写操作按顺序写入日志块中。当一个日志块满了之后,将其和与其在相同逻辑块编号(LBN)的数据块合并到空块中。只需要维护少量的日志块,且允许以页粒度维护。而块级映射是以块粒度维护的。
(文章中给出了一个例子说明如何工作。日志块是在内存中的,详细记录了到page的映射关系。当这个日志块需要刷下去的时候,会和磁盘上记录对应的块做一个block merge, 然后磁盘上只记录block的映射关系)
4.2. Garbage collection
如第一节中所说,擦除命令需要1500-3500 μs,写入命令需要250-1500 μs。因为擦除比写入需要更高的延迟,额外的擦除步骤导致一个延迟使得写入更慢。因此,一些控制器实现了后台垃圾回收进程,或者被称为闲置垃圾回收,其充分利用空闲时间并经常在后台运行以回收stale页并确保将来的前台操作具有足够的空页来实现最高性能。其他的实现使用并行垃圾回收方法,其在来自主机的写入操作的同时,以并行方式进行垃圾回收操作。
遇到写入工作负载重到垃圾回收需要在主机来了命令之后实时运行的情况并非罕见。在这种情况下,本应运行在后台的垃圾回收进程可能会干预到前台命令。TRIM命令和预留空间是减少这种影响的很好的方法。块需要移动的一个不太重要的原因是read disturb(读取扰乱)。读取可能改变临近单元的状态,因此需要在一定数量的读取之后移动块数据。
数据改变率是一个很重要的影响因素。有些数据很少变化,称为冷数据或者静态数据,而其他一些数据更新的很频繁,称为热数据或者动态数据。如果一个页一部分储存冷数据,另一部分储存热数据,这样冷数据会随着热数据一起在垃圾回收以损耗均衡的过程中拷贝,冷数据的存在增加了写入放大。这可以通过将冷数据从热数据之中分离出来,存储到另外的页中来避免。缺点是这样会使保存冷数据的页更少擦除,因此必须将保存冷数据和热数据的块经常交换以确保损耗均衡。因为数据的热度是在应用级确定的,FTL没法知道一个页中有多少冷数据和热数据。改进SSD性能的一个办法是尽可能将冷热数据分到不同的页中,使垃圾回收的工作更简单。(应用上可能应该就是尽可能地将冷热数据存储在不同文件里)
- 分开冷热数据。热数据是经常改变的数据,而冷数据是不经常改变的数据。如果一些热数据和冷数据一起保存到同一个页中,冷数据会随着热数据的读-改-写操作一起复制很多次,并在为了损耗均衡进行垃圾回收过程中一起移动。尽可能的将冷热数据分到不同的页中是垃圾回收的工作更简单。
- 缓存热数据。极其热的数据应该尽可能多的缓存,并尽可能的少的写入到硬盘中。
- 以较大的量废除旧数据。当一些数据不再需要或者需要删除的时候,最好等其它的数据一起,在一个操作中废除一大批数据。这会使垃圾回收进程一次处理更大的区域而最小化内部碎片。
5. Advanced functionalities
5.1. TRIM
让我们假设一个程序向SSD所有的逻辑块地址都写入文件,这个SSD当然会被装满。然后删除这些文件。文件系统会报告所有的地方都是空的,尽管硬盘实际上还是满的,因为SSD主控没法知道逻辑数据是什么时候被主机删掉的。SSD主控只会在这些逻辑块地址被复写的时候才知道这些是空闲空间。此时,垃圾回收进程将会擦除与这些文件相关的块,为进来的写操作提供空的页。其结果就是,擦除操作并非在知道保存有无用数据之后立刻执行,而是被延迟了,这将严重影响性能。
另一个值得关心的是,既然SDD主控不知道这些页保存有已删除的文件,垃圾回收机制仍然会为了损耗均衡而移动这些页上的数据。这增加了写入放大,并毫无意义地影响了来自主机的前台工作负载。
延迟擦除问题的一个解决方法是TRIM命令,这个命令由操作系统发送,通知SSD控制器逻辑空间中的这些页不会再使用了。有了这个信息,垃圾回收进程就会知道自己不必再移动这些页,并可以在任何需要的时间擦除它们。TRIM命令只会在当SSD、操作系统和文件系统都支持的时候才起作用。
TRIM命令的维基百科页面列出了支持TRIM的操作系统和文件系统。Linux下,ATA TRIM的支持是在2.6.33版本加入的。尽管ext2和ext3 文件系统不支持TRIM,ext4 和XFS以及其他的一些是支持的。在MacOSX 10.6.8下,HFS+支持TRIM操作。Windows 7则只支持使用SATA接口的SSD的TRIM,使用PCI-Express的则不支持。
现在大部分的硬盘都支持TRIM,确实,允许垃圾回收尽早的工作显著地提升了将来的性能。因此强烈建议使用支持TRIM的SSD,并确保操作系统和文件系统级都启用了TRIM功能。(但是事实上,如何使用TRIM功能还值得讨论,比如是实时还是批量TRIM。对于Linux内核来说实时TRIM会影响性能,所以推荐批量TRIM,比如每天进行一次TRIM)
5.2. Over-provisioning(预留空间)
预留空间只是简单的使物理块比逻辑块多,即为主控保留一定比例的,用户不可见的物理块。大多专业级SSD生产商已经包括了一些预留空间,通常是7~25%。用户可以简单的通过创建比最大物理容量小的逻辑容量分区来创建更多的预留空间。例如,你可以在100G的硬盘上创建一个90G的分区,而把剩下的10G作为预留空间。即使预留空间在操作系统级是不可见的,但SSD主控仍然是可以看见的。生产商提供预留空间的主要原因是为了对付NAND闪存单元固有的寿命限制。不可见的预留空间的块将无缝的替换可见空间上的已耗损殆尽的块。
AnandTech有一篇有意思的文章显示出预留空间对SSD寿命和性能的影响。在他们研究的硬盘上,结果显示出仅通过保证25%的预留空间(把所有的预留空间加在一起)就可以使性能极大地提升。在Percona的一篇文章中有另外一个有意思的结果,在他们测试了一块Intel 320 SSD,显示出当硬盘逐渐填满时,写入吞吐量将随之下降。
对这些实验结果我的解释是这样的。垃圾回收是使用空闲时间在后台擦除页上不再使用的数据的。但既然擦除操作比写入操作的延迟更久,或者说擦除要的时间比写入长,在持续的重随机写入工作负载下的SSD将会在垃圾回收有机会擦除之前用尽所有的空块。此时,FTL将不能跟上前台的随机写入工作负载,而垃圾回收进程将必须在写入命令进来的同时擦除块。这就是在基准测试中SSD性能下降的厉害,而SSD显得性能超差的时候,如下图7所示。因此,预留空间可以吸收高吞吐量写入负载,起到缓冲的作用,为垃圾回收跟上写入操作并重新开始擦除无用块留够时间。预留空间需要多少大部分基于SSD使用环境的工作负载,和其需要的承受的写入操作的量。作为参考,持续随机写入的工作负载比较推荐使用大约25%的预留空间。如果工作负载不是很重,大概10~15%估计够大的了。
5.3. Secure Erase
5.4. Native Command Queueing(NCQ)
5.5. Power-loss protection
6. Internal Parallelism in SSDs
6.1. Limited I/O bus bandwidth
内部并行是指在SSD内部,数个层次的并行允许一次将数个块写入到不同的NAND闪存芯片中,这些块称为簇(clustered block)。
因为物理限制的存在,异步NAND闪存I/O总线无法提供32-40MB/s以上的带宽。SSD生产商提升性能的唯一办法是以某种方法让他们的硬盘中的多个存储芯片可以并行或者交错。
6.2. Multiple levels of parallelism
下图展示了NAND闪存芯片的内部,其组织为一种分级的结构。这些级别包括通道、封装、芯片、面、块和页。这些不同的层通过下边的方法提供并行
- 通道级并行 闪存主控和闪存封装之间的通信通过数个通道。这些通道可以独立或者同时访问。每个独立通道被数个封装(package)共享。(也就是说,一个封装可以用过多个channel来操作)
- 封装级并行 一个通道中的不同封装可以独立访问。交错可以使命令同时在同一个通道中的不同封装中运行。(即使一个channel也可以通过交错方式操作多个package)
- 芯片级并行 一个封装包含两个或者更多的芯片,芯片可以并行独立访问。注:芯片通常也被称为核心(chips are also called “dies”)
- 面级并行 一个芯片包含两个或者更多的面。相同的操作(读、写或者擦除)可以在芯片中多个面上同时运行。面包含了块,块包含了页。面也包含了寄存器(小RAM缓存),其用在面级操作上。
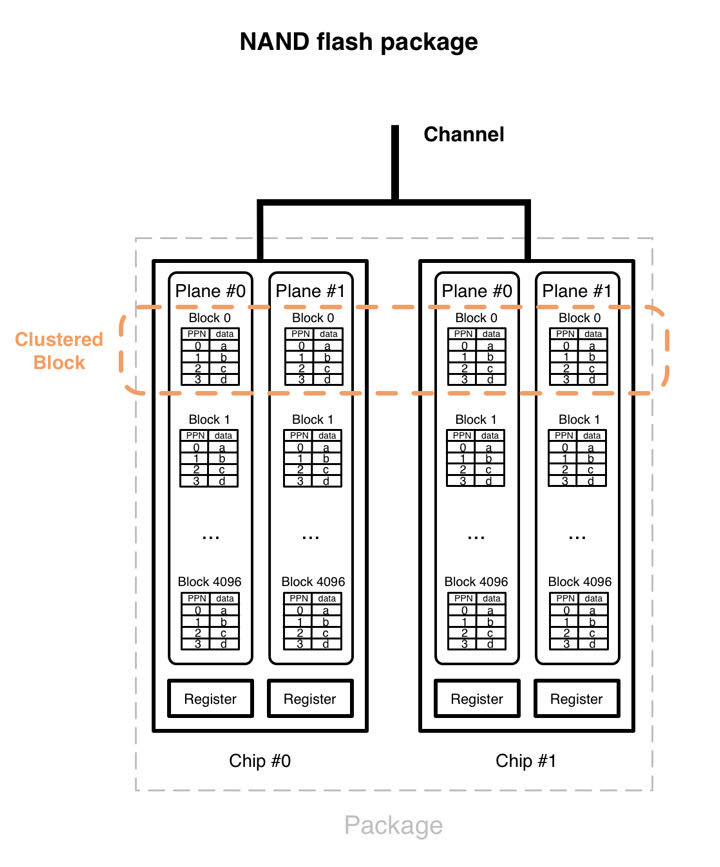
6.3. Clustered blocks
一次访问的逻辑块地址被分到不同SSD闪存封装中的不同芯片上。这归功于FTL的映射算法,并且这与这些地址是否连续无关。分割块允许同时使用多个通道来整合其带宽,并同样可以并行执行多个读、写和擦除操作。这即表示I/O操作按簇大小对齐来确保SSD中多个级别的内部并行所提供的性能能够被最大程度的利用。
7. Access patterns
7.1. Defining sequential and random I/O operations
如果I/O操作开始的逻辑块地址(LBA)直接跟着前一个I/O操作的最后LBA,则称值为顺序访问。如果不是这样,那这个I/O操作称为随机访问。这很一点重要,因为FTL执行动态映射,相邻的逻辑空间地址可能被应用于不相邻的物理空间地址上。
7.2. Writes
基准测试和生产商提供的数据表显示出,随机写入比序列写入要慢,但这并不总是对的,因为随机写入的速度实际上取决于工作负载的类型。如果写入比较小,小是说小于簇(译注:关于簇的翻译请见上一篇文章)大小(就是说 <32MB),那么是的,随机写入比顺序写入慢。然而,如果随机写入是按照簇大小对齐的,其性能将会和顺序写入一样。
解释如下。如第六节所说,SSD的内部并行机制通过并行和交错,允许簇中的块同时访问。因此,无论是随机或者序列写入,都会同样将数据写入到多个通道和芯片上,从而执行簇大小的写入可以确保全部的内部并行都用上了。当基准测试写入缓存和簇大小(大部分SSD是16或32MB)相同或者更大时,随机写入达到和顺序写入同样高的吞吐量。然而,如果是小写入——小是指比NAND闪存页小(就是说<16KB),主控需要做更多的工作以维护用来做块映射的元数据上。确实,一些SSD使用树形的数据结构来实现逻辑块地址和物理块地址之间的映射,而大量小随机写入将转换成RAM中映射的大量更新。因为这个映射表需要在闪存中维护,这将导致闪存上的大量写入(参看FTL一节)。而顺序工作负载只会导致少量元数据的更新,因此闪存的写入较少。另外一个原因是,如果随机写入很小,其将在块中引起大量的复制-擦除-写入操作。另一方面,大于等于块大小的顺序写入可以使用更快的交换合并优化操作。再者,小随机写入显然会有随机的无效数据。大量的块将只有一页是无效的,而非只有几个块全部无效,这样会导致作废的页将遍布物理空间而非集中在一起。这种现象被称为内部碎片,并导致清除效率下降,垃圾回收进程通过请求大量的擦除操作才能创建空页。
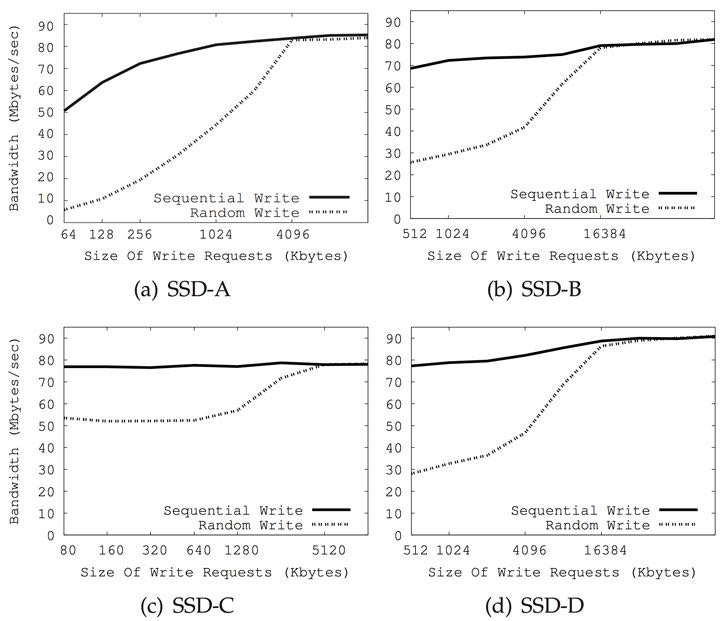
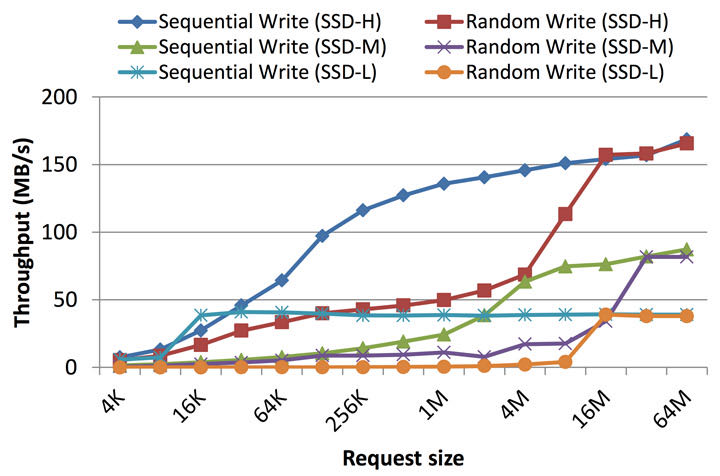
>>> 如果写入很小(就是说比簇大小要小),随机写入将比顺序写入慢。如果写入是按簇大小对齐,随机写入将使用所有可用层级上的内部并行,并显示出和随机写入相同的性能。
>>> 单一的大写入请求和很多小并发写入请求相比,表现出相同的吞吐量,但会导致延迟。单一的大写入比并发写入在响应时间上表现的更好。因此,只要可能,最好使用大写入,
>>> 很多并发的小写入请求将比单一的小写入请求提供更好的吞吐量。因此如果I/O比较小并不能整合到一起,最好是使用多线程。
7.3. Reads
读取比写入要快。无论是顺序读取还是随机读取,都是这样。FTL是逻辑块到物理块地址的动态映射,并且将写入分布到各个通道上。这个方法有时候被称为“基于写入顺序的”映射。如果数据是以和原本写入的顺序完全不相关,完全随机读取的,那就无法保证连续的读取分布在不同的通道。甚至有可能连续的随机读取访问的是同一个通道中的不同块,因此无法从内部并行中获取任何优势。
>>> 所以为了提升读取性能,将相关数据写在一起。读取性能由写入模式决定。当大块数据一次性写入时,其将被分散到不同的NAND闪存芯片上。因此你应该将相关的数据写在相同的页、块、或者簇上,这样稍后你可以利用内部并行的优势,用一个I/O访问较快的读取。
内部并行的一个直接结果是,使用多线程同时读取数据不是提升性能所必须的。实际上,如果这些并不知道内部映射的线程访问这些地址,将无法利用内部并行的优势,其可能导致访问相同的通道。同时,并发读取线程可能影响SSD预读能力(预读缓存)。
>>> 所以一个单一的大读取比很多小的并发读取要好,并发随机读取不能完全使用预读机制。并且,多个逻辑块地址可能被映射到相同的芯片上,不能利用内部并行的优势。再者,一个大的读取操作会访问连续的地址,因此能够使用预读缓存(如果有的话)。因此,进行大读取请求更加可取。
7.4. Concurrent reads and writes
小的读和写交错会导致性能下降。其主要原因是对于同一个内部资源来说读写是相互竞争的,而这种混合阻止了诸如预读取机制的完全利用。
>>> 分离读写请求。混合了小读取和小写入的工作负载将会阻止内部缓存和预读取机制的正常工作,并导致吞吐量下降。最好是能够避免同时的读写,并以一个一个的较大的数据块来进行,最好是簇的大小。
8. System optimizations
8.1. Partition alignment(分区对齐)
8.2. Filesystem parameters
使用TRIM指令以及设置noatime.
8.3. Operating system I/O scheduler
我个人从中学到的是,除非工作负载十分特殊并且特定应用的基准测试显示出某个调度器确实比另一个好,CFQ是一个比较安全的选择。
8.4. Swap
vm.swappiness=0 来尽可能地避免在SSD上做页交换