CMU DB Concurrency Control Theory
并发控制主要是为了实现事务,在实现上分为悲观和乐观控制两种方式:悲观假设所有的事务会相互冲突,实现出来支持的吞吐量不搞;乐观假设事务是不会相互冲突的,可以同时执行,直到发生实际冲突。
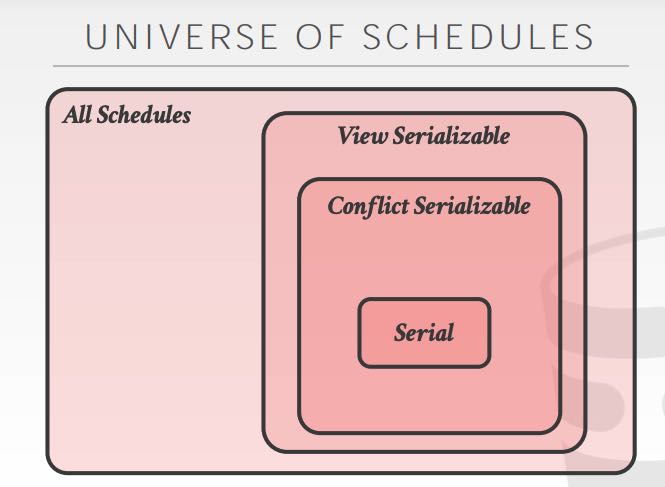
里面提到了调度的两种serializability: conflict & view. 好像课程上也没有谈到这两个的区别。看提纲里面的说明是,view sz除了满足conflict sz之外还允许blind write, 所以满足view sz的schedules数量会更多。但是鉴于事务管理其实不知道具体的操作的语义,所以现在大部分DBMS都是实现了conflict sz. conflict sz的意思是,对于每个tx里面的operations按照某种serial order执行,如果两个op存在冲突的话,可以尝试更换顺序,找到合理的schedules. 不过我的理解是,这些都是理论上的东西,都是在离线地寻找满足某种sz的schedules, 现实的OLTP可是在线系统,做不了这许多事情。
接下来就是CC的实现方式了:two-phase locking(两阶段锁,2PL,大部分DBMS都实现了), timestamp ordering(时间序,我理解spanner可能属于这个范畴),multi-version (多版本)。
2PL有两个阶段:growing & shrinking. 第一个阶段不断地拿到锁,第二个阶段不断地释放锁。基本的2PL实现可能会存在cascading aborts,tx1的abort会导致tx2 abort(考虑一下如果tx2 读取了 tx1的写入,但是tx1最终abort的情况)。cascading aborts回滚实现起来比较麻烦,所以为了避免它,可能对2PL施加更强的限制(strong strict 2PL),就是只在事务结束的时候释放锁。 2PL的最大问题就在于并发性不好。
2PL基本的锁有两个read/write lock,但是在事务里面通常叫做shared lock(S), exclusive lock(X). 但是仅仅有这两个lock还是不够的,设想起来如果要对table scan,那么我们要对上面所有的tuples做S-Lock,这个量有点大。我们需要有更大粒度的锁,所以就有了Intention lock:Intention-Shared(IS), Intention-Exclusive(IX), shared+intention-exclusive(SIX),关于这三个锁的用途可以看下面:增加了这些锁之后,锁的获取判断就复杂了,关于这点我还没有完全搞明白。
- Intention-Shared (IS): Indicates explicit locking at a lower level with shared locks.
- Intention-Exclusive (IX): Indicates explicit locking at a lower level with exclusive or shared locks.
- Shared+Intention-Exclusive (SIX): The sub-tree rooted at that node is locked explicitly in shared mode and explicit locking is being done at a lower level with exclusive-mode locks.
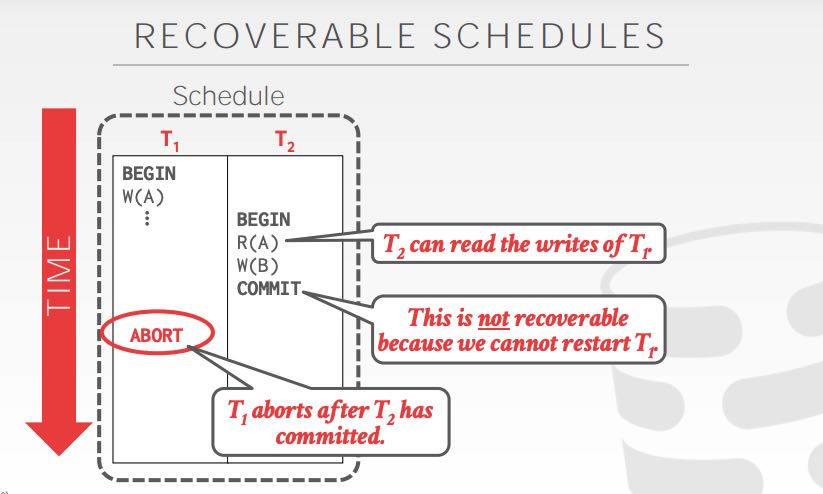
TO有两种实现:Basic和OCC的,先从Basic的开始说起。Basic的实现方式是,对于每个txn都会分配一个ts(timestamp),每次对对象读写都会更新这个时间戳(单调递增)。如果TS(t) < W-TS(x)的话,那么t是不允许去读取这个x对象的,那么t只能abort. 如果TS(t) < R-TS(x) 或者是 < W-TS(x)的话,那么t也不允许去更新这个对象。总之就是,如果有更高时间戳的txn更新了某个对象的话,那么旧的txn再想操作这个对象是不行的了。操作成功之后需要维护一个local copy以便执行repeat reads. Basic TO还有个优化,就是Thomas Write Rule, 就是如果Write不成功的话,其实完全可以忽略它,因为其他副本也不会读到这个Write值,而本身这个txn是有个local copy的。Basic TO还有个问题就是,就是schedule不是recoverable的,不过好像也不是什么大问题。以下图说明调度不是recoverable的:R(A)读取了T1的W(A),但是T1 abort了。想让T2成功,必须重启T1。可是如果重启T1的话,TS(T1)就变了导致W(A)也会失败。这种情况只能类似使用cascading abort,将T2去abort.
OCC TO实现和Basic TO实现非常类似,差别在于txn每次更新并不是去更新global table,而是更新每个txn内部的local table. 然后在最后提交的时候,进行validate & write. 只有在最后validate & write阶段是串行的,期间每个txn都是各自进行自己的工作,不会类似Basic TO一样去看global table上的TS. TS分配也从txn开始阶段,后移到了validate阶段。validate阶段主要就是进行冲突处理,有好几种情况,这样就不写了。
前面提到的都是已经存在的tuple的read/write. 我们可以对这些tuple进行local copy,或者是在table上增加intention lock. 可是如果txn里面包含了insert/delete的话,允许对tuple进行增加和删除,那么可能就会看到某个之前不存在的值,这就是phantom problem. 这个问题出现的本质,还是因为锁的粒度不够引起的,如果对整个table加一个大锁,肯定不会出现phantom problem.
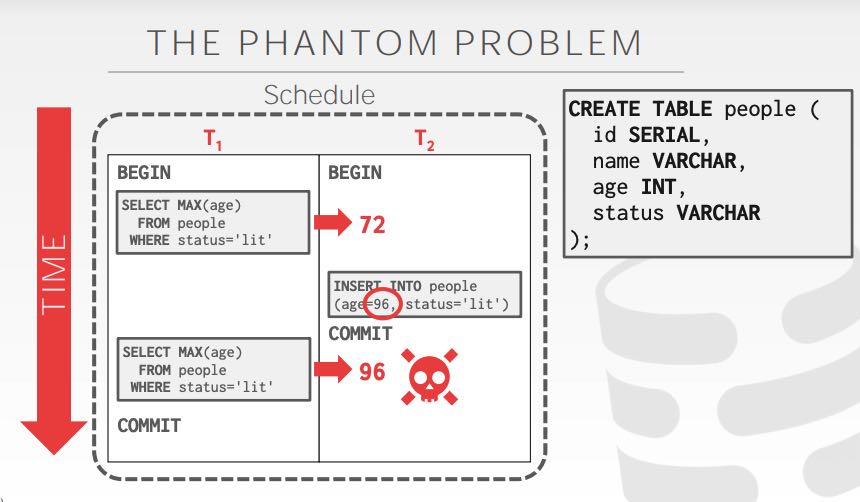
有好几种办法解决phantom problem: re-scan(cost太高), predicate locking(cost也太高,需要判断insert/delete是否会落在predicate上), index locking(cost还能接受,如果没有index的话,就只能回退到table lock)上。
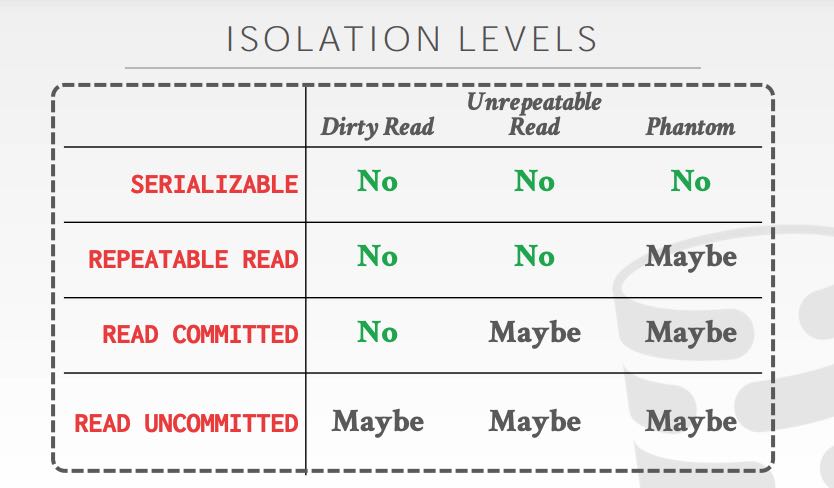
根据读数据的几种情况,可以得到下面几种隔离级别:
- 如果允许脏读,那么就是read uncommitted,否则就要read committed
- 如果读值之后不能改变,那么就要使用repeatable read
- 如果不能出现phantom value, 那么只能选择serializable