Certificate Transparency
https://www.certificate-transparency.org/what-is-ct https://www.certificate-transparency.org/how-ct-works https://research.swtch.com/tlog
我理解CT这个技术要解决的问题是,如何确保CA颁发的证书是真实的而没有被伪造。如果某个CA被攻击的话,理论上可以将某个域名microsoft.com的公钥进行修改,然后浏览器访问microsoft.com被导引某个钓鱼网站,而这个网站使用的则是对应的私钥。解决的方法就是,证书不会被某个CA认证(可以被一个CA办法),而是被多个CA进行认证,多个CA同时被攻击的概率应该是足够小的。
CT实现上需要有三个部分:
- Certificate Logs. CA操作成为log被追加写入到Logs里面,并且只有追加写操作。Logs可以被任何人读取,并且可以很容易地与其他CA上的Logs进行对比,观察是否被篡改。
- Monitors.它不断地区多个CA上获取Logs,检查Logs之间是否有不一致的情况。它的作用有点像是报警器,一旦出现Logs不一致的话,可以认为某个CA可能遭受了攻击。通常Monitor上面也会存有Logs copy.
- Auditors. 它则检查某个记录是否出现在Logs里面,以及Logs之间是否有不一致的情况。它的作用更像是客户端上的检查器,请求某个域名之前会验证一下这个域名是否被正确记录在Logs里面。
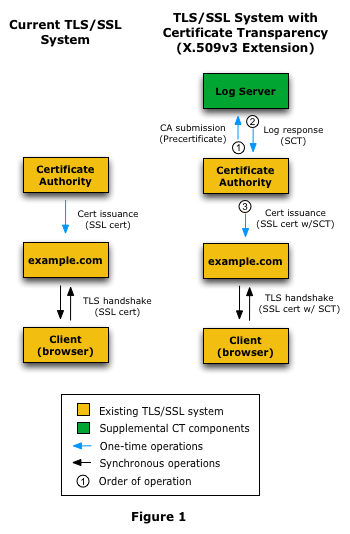
CT可以在现在的TSL/SSL系统上改进得到,下图是三种方式:
- X509v3 ext. 这个在办法证书的是否,就将log写入到LOGS里面,并且返回一个SCT(signed certificate timestamp). 你可以认为这个SCT就是这个log block的id. 可以通过这个SCT找到颁发记录。SCT同时被嵌入到了私钥里面,浏览器在请求CA的时候也会将SCT放在公钥里面一并返回。这个是直接在证书上进行扩展。
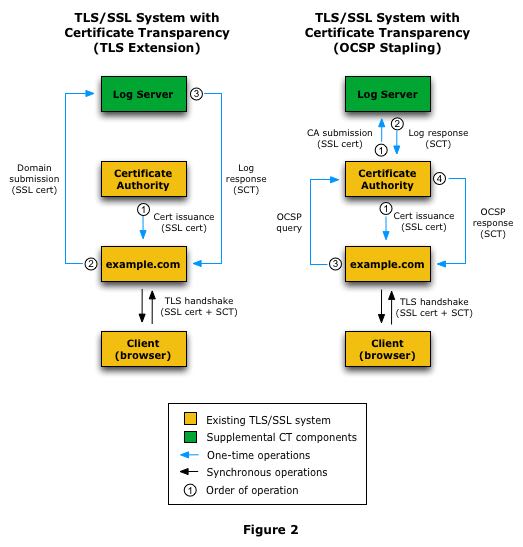
- TLS ext. 将log写入由domain owner来完成。CA不会知道这个SCT. 这个是在握手阶段进行扩展。
- OCSP Stapling. 和第二个有点像,但是是CA异步地去申请SCT. LogServer接收到请求可能并不会立刻就写入到Log, 估计会攒一些记录。
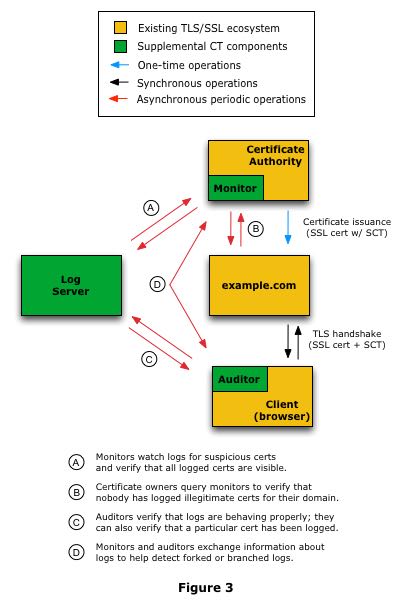
下面图是一张CT的部署方式:
- CA需要不断地与Log Servers进行沟通,并且上面运行这monitor,检查自己拿到的Logs copy是否有问题。
- Client上面运行Auditor. 它要检查自己从CA上申请拿到的公钥和SCT是否合法,同时会校验CA的合法性。这个合法性是和其他log server通信知道的。
了解了CT的工作原理,就看LogServer是如何实现了。这个就要看论文了,关键的数据结构是Merkel Tree,论文里面有详细说明。所有的Log都被当做了叶子节点,然后这些叶子节点组成一个二叉树。可以通过SCT找到这些Log的下标,如果在知道这个树的大小,就可以做许多操作了。我觉得先看看这个Log Server提供了那些关键的API:
- Latest() returns the current log size and top-level hash, cryptographically signed by the server for non-repudiation.
- RecordProof(R, N) returns the proof that record R is contained in the tree of size N.
- TreeProof(N, N′) returns the proof that the tree of size N is a prefix of the tree of size N′.
- Lookup(K) returns the record index R matching lookup key K, if any. [SCT -> Log Index]
- Data(R) returns the data associated with record R. [从Log中提取数据]
4,5比较好理解,关键就是1,2,3了。
操作1就是返回root节点的hash以及tree size. 知道这个就可以去和log server同步最新的状态了。但是在同步之前,我们先要确认,我们通信的log server是否被攻击了,或者我们的数据是否有问题。这个是否就需要操作3了,验证某个tree是否是另外一个tree的前缀。我们拿我们自己本地的root信息(hash, size)去询问log server,如果我们的root是log server上root的前缀,那么说明我们的数据是完好的。如果出现问题,要是是我们的root有问题,要么是log server有问题。为了解决这个问题,就需要和多个log server通信。操作2是验证record是否出现在size=N的tee中. 这个auditor需要使用到,即拿一个SCT(除了可以知道对应的log index之外,应该还有这个log hash)去log server上询问有没有对应的record,以及校验hash是否一致。
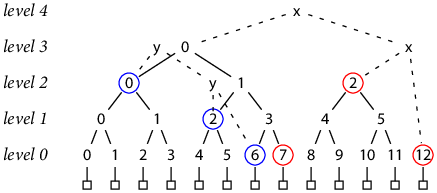
如何操作这个Merkel Tree,论文里面有说明。简单地说就是按照level进行存储,并且仅仅存completed-size tree的hash value. 至于那些non completed的,则是需要计算得到,但是这个时间复杂度是O(lgN). 以下图为例的话,增加12节点,我们需要[3,0], [2,2], [0,12],其中[3,0],[2,2]已经是completed-size tree.
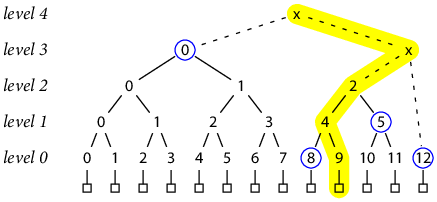
然后如果要验证某个tree是否为另外一个tree的前缀的话,下图为例假设我们要验证y是否为x的前缀,y的大小是7, 我们使用x上[2,0], [1,2], [0,6] 这三个节点可以得到y的root hash value. 注意这三个节点也都是completed-size的。
下面是Python伪代码其中:
- append(N) 表示将要加入编号为N的节点(起始是0),返回从下到上需要合并计算hash的节点
- prefix = append,prefix表示为了计算tree大小为N的root hash, 需要使用哪些节点。这个问题等同于加入编号为N的节点。
- update(N) 表示将要加入编号为N的节点,计算出来hash之后,需要更新哪些level.
#!/usr/bin/env python3
# coding:utf-8
# Copyright (C) dirlt
print('---------- test append ----------')
def append(N):
L = 0
n = N
while n:
L += 1
n = n // 2
n = N
L = L - 1
ans = []
while n:
size = 1 << L
if n >= size:
i = N // size
ans.append((L, i-1))
n -= size
L -= 1
ans = ans[::-1]
return ans
def prefix(N): return append(N)
assert append(8) == [(3, 0)]
assert append(12) == [(2,2), (3, 0)]
assert append(9) == [(0, 8), (3, 0)]
print('---------- test update ----------')
def update(N):
orders = append(N)
ans = []
h = hash(N)
for level, index in orders:
h = hash(h + hash((level, index)))
l = level + 1
i = index // 2
size = 1 << l
if (i + 1) * size == (N+1):
ans.append((l, i))
print('add level', ans)
return h, ans
update(8)
update(9)
update(11)