Building Software Systems at Google and Lessons Learned
Table of Contents
- 1. Outlines
- 2. Google Web Search: 1999 vs. 2010
- 3. System Software Evolution
- 4. System Building Experiences and Patterns
- 4.1. Many Internal Services
- 4.2. Designing Efficient Systems
- 4.3. Designing & Building Infrastructure
- 4.4. Design for Growth
- 4.5. Pattern: Single Master, 1000s of Workers
- 4.6. Pattern: Tree Distribution of Requests
- 4.7. Pattern: Backup Requests to Minimize Latency
- 4.8. Pattern: Multiple Smaller Units per Machine
- 4.9. Pattern: Elastic Systems
- 4.10. Pattern: Combine Multiple Implementations
- 5. Final Thoughts
Jeff Dean @ 2010
1. Outlines
- Evolution of various systems at Google
- computing hardware
- core search systems
- infrastructure software
- Techniques for building large-scale systems
- decomposition into services
- design patterns for performance & reliability
2. Google Web Search: 1999 vs. 2010
- # docs: tens of millions to tens of billions ~1000X
- queries processed/day: ~1000X
- per doc info in index: ~3X
- update latency: months to tens of secs ~50000X 这个似乎加快了不少,搜索实时性是一个很重要的问题
- avg. query latency: <1s to <0.2s ~5X
- More machines * faster machines: ~1000X
- Continuous evolution:
- 7 significant revisions in last 11 years
- often rolled out without users realizing we’ve made major changes
2.1. Caching in Web Search
- Cache servers:
- cache both index results and doc snippets
- hit rates typically 30-60%
- depends on frequency of index updates, mix of query traffic, level of personalization, etc
- Main benefits:
- performance! a few machines do work of 100s or 1000s
- much lower query latency on hits
- queries that hit in cache tend to be both popular and expensive (common words, lots of documents to score, etc.)
- Beware: big latency spike/capacity drop when index updated or cache flushed 使用cache系统就必须注意cache挂掉时候带来的latency spike
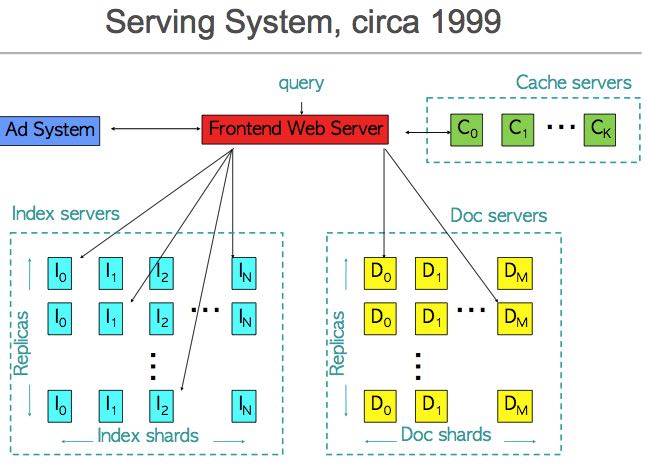
2.2. Indexing (circa 1998-1999)
- Simple batch indexing system
- No real checkpointing, so machine failures painful 在做索引的时候没有checkpoint,所以机器故障会非常麻烦
- No checksumming of raw data, so hardware bit errors caused problems 对于大规模数据来说,checksum还是非常必须的。
- Exacerbated by early machines having no ECC, no parity
- Sort 1 TB of data without parity: ends up "mostly sorted"
- Sort it again: "mostly sorted" another way
- “Programming with adversarial memory”
- Developed file abstraction that stores checksums of small records and can skip and resynchronize after corrupted records
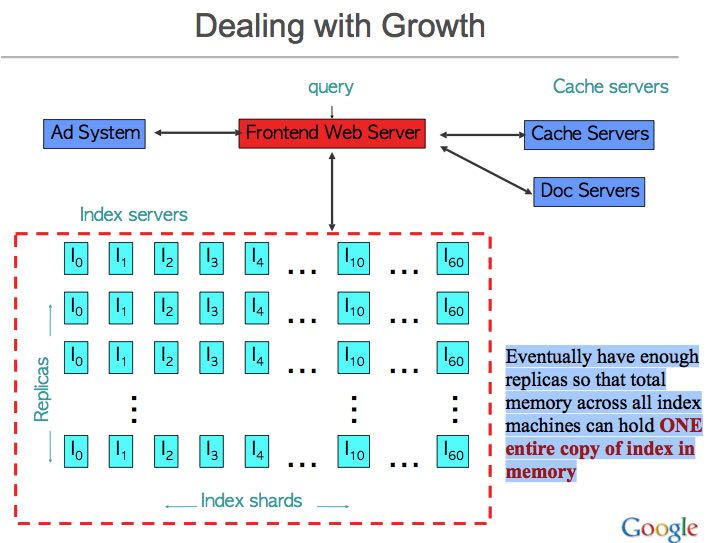
2.3. Early 2001: In-Memory Index
- 解决index server压力的办法是通过添加更多的index replicas,但是突然有一天发现 Eventually have enough replicas so that total memory across all index machines can hold ONE entire copy of index in memory replicas机器已经足够多,在内存完全可以存放下index. 然后变成如下结构
- Many positives:
- big increase in throughput
- big decrease in query latency
- Some issues:
- Variance: query touches 1000s of machines, not dozens
- 因为需要查询更多的机器,因此查询的变化也会非常大,不太容易控制差异
- e.g. randomized cron jobs caused us trouble for a while
- Availability: 1 or few replicas of each doc’s index data
- Availability of index data when machine failed (esp for important docs): replicate important docs
- Queries of death that kill all the backends at once: very bad
- 存在一个问题就是,一个query可能会因为system bug造成crash. 如何解决这个问题,就是下面的canary request
- Variance: query touches 1000s of machines, not dozens
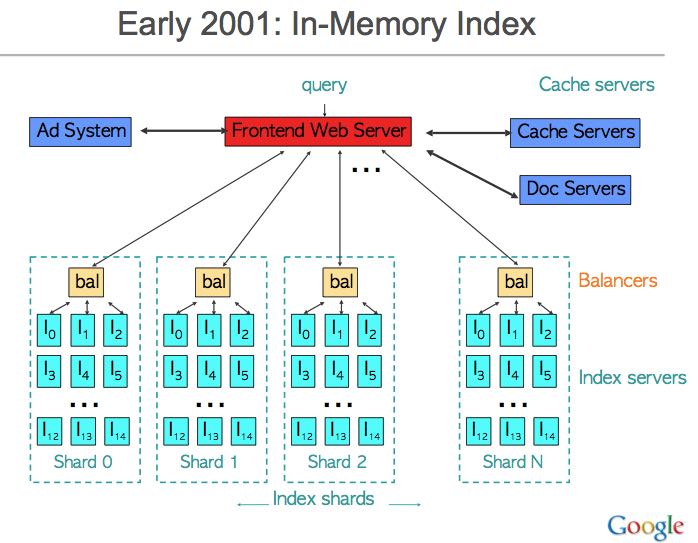
2.4. Canary Requests
- 主要就是针对特定query会造成system crash.但是我们不希望所有的nodes都crash.
- Problem: requests sometimes cause server process to crash
- testing can help reduce probability, but can’t eliminate
- If sending same or similar request to 1000s of machines:
- they all might crash!
- recovery time for 1000s of processes pretty slow
- Solution: send canary request first to one machine 可以首先将request发送到一个节点上,如果正常的话那么发送到其他节点,否则重试几次失败就放弃。
- if RPC finishes successfully, go ahead and send to all the rest
- if RPC fails unexpectedly, try another machine (might have just been coincidence)
- if fails K times, reject request
- Crash only a few servers, not 1000s
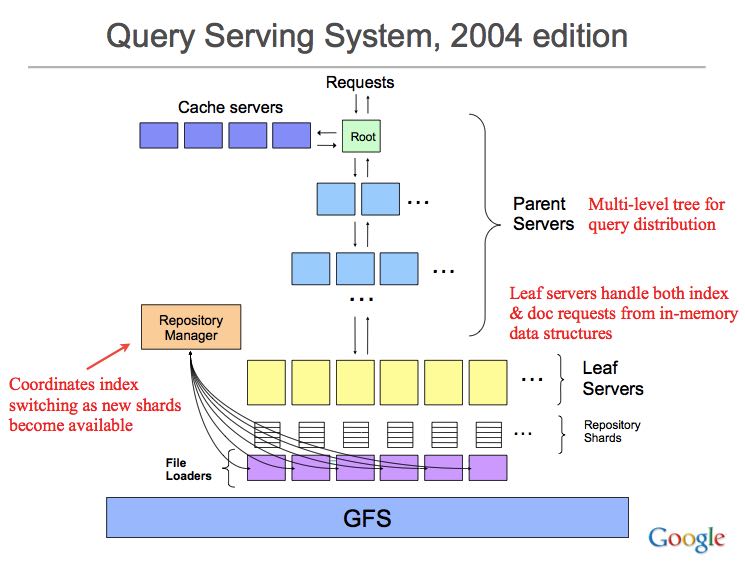
2.5. Query Serving System, 2004 edition
我觉得这个应该是google query serving system的最终模型了。leaf所有的数据都是全内存的,但是在GFS上面有on-disk数据做持久化,或者说leaf是一个简单的query system + bigtable吧。之所有使用这种multi-level tree结构在这篇文章后面的pattern部分会说到。
2.6. Encodings
- Byte-Aligned Variable-length Encodings
- 7 bits per byte with continuation bit
- Con: Decoding requires lots of branches/shifts/masks
- Encode byte length using 2 bits
- Better: fewer branches, shifts, and masks
- Con: Limited to 30-bit values, still some shifting to decode
- 7 bits per byte with continuation bit
- Group Varint Encoding
- encode groups of 4 32-bit values in 5-17 bytes
- Pull out 4 2-bit binary lengths into single byte prefix
- Much faster than alternatives:
- 7-bit-per-byte varint: decode ~180M numbers/second
- 30-bit Varint w/ 2-bit length: decode ~240M numbers/second
- Group varint: decode ~400M numbers/second
2.7. 2007: Universal Search
从多个产品整合搜索结果,但是有下面这些问题:
- Performance: most of the corpora weren’t designed to deal with high QPS level of web search 性能匹配
- Mixing: Which corpora are relevant to query? 相关性
- UI: How to organize results from different corpora? UI布局
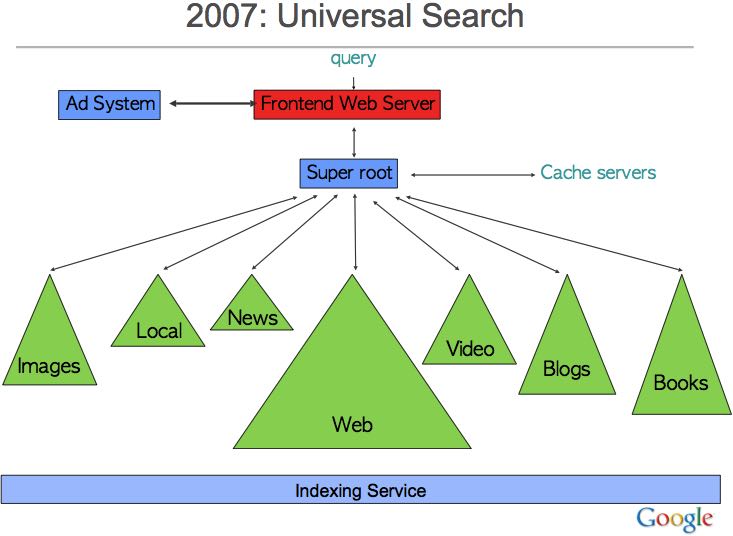
3. System Software Evolution
- The Joys of Real Hardware (Typical first year for a new cluster):
- ~1 network rewiring (rolling ~5% of machines down over 2-day span)
- ~20 rack failures (40-80 machines instantly disappear, 1-6 hours to get back)
- ~5 racks go wonky (40-80 machines see 50% packetloss)
- ~8 network maintenances (4 might cause ~30-minute random connectivity losses)
- ~12 router reloads (takes out DNS and external vips for a couple minutes)
- ~3 router failures (have to immediately pull traffic for an hour)
- ~dozens of minor 30-second blips for dns
- ~1000 individual machine failures
- ~thousands of hard drive failures
- slow disks, bad memory, misconfigured machines, flaky machines, etc.
- Long distance links: wild dogs, sharks, dead horses, drunken hunters, etc.
- Reliability/availability must come from software!
4. System Building Experiences and Patterns
4.1. Many Internal Services
- Break large complex systems down into many services!
- Simpler from a software engineering standpoint
- few dependencies, clearly specified
- easy to test and deploy new versions of individual services
- ability to run lots of experiments
- easy to reimplement service without affecting clients
- Development cycles largely decoupled
- lots of benefits: small teams can work independently
- easier to have many engineering offices around the world
- e.g. google.com search touches 200+ services
- ads, web search, books, news, spelling correction, …
4.2. Designing Efficient Systems
- Given a basic problem definition, how do you choose "best" solution?
- Best might be simplest, highest performance, easiest to extend, etc.
- Back of the Envelope Calculations
- Know Your Basic Building Blocks
- Core language libraries, basic data structures, protocol buffers, GFS, BigTable, indexing systems, MapReduce, …
- Not just their interfaces, but understand their implementations (at least at a high level)
- If you don’t know what’s going on, you can’t do decent back-of-the-envelope calculations!
4.3. Designing & Building Infrastructure
- Identify common problems, and build software systems to address them in a general way 尝试从general角度解决问题,这样才能够做出infrastructure
- Important to not try to be all things to all people 但是对不同需求需要不同对待,不一定需要将解决方案放在一个实现里面
- Clients might be demanding 8 different things
- Doing 6 of them is easy
- …handling 7 of them requires real thought
- …dealing with all 8 usually results in a worse system
- more complex, compromises other clients in trying to satisfy everyone
- Don't build infrastructure just for its own sake: 设计通用组件的话,还需要去排除那些潜在的不需要的需求,抑制复杂性
- Identify common needs and address them
- Don't imagine unlikely potential needs that aren't really there
- Best approach: use your own infrastructure (especially at first!)
- (much more rapid feedback about what works, what doesn't)
4.4. Design for Growth
- Try to anticipate how requirements will evolve keep likely features in mind as you design base system
- Don’t design to scale infinitely: 扩展性只需要考虑5x-50x左右的扩展即可
- ~5X - 50X growth good to consider
- >100X probably requires rethink and rewrite
4.5. Pattern: Single Master, 1000s of Workers
master主要完成全局性质的工作,其余工作交给worker完成。通常存在hot standby来做failover. 优点是可以很容易地进行全局控制,但是实现上必须小心,而缺点非常明显就是支撑worker不会很多,在1k级别上。如果涉及到更大规模集群的话,那么worker需要和master有更加频繁的交互,这对于master压力会非常大。
- Master orchestrates global operation of system
- load balancing, assignment of work, reassignment when machines fail, etc.
- … but client interaction with master is fairly minimal
- Often: hot standby of master waiting to take over
- Always: bulk of data transfer directly between clients and workers
- Examples:
- GFS, BigTable, MapReduce, file transfer service, cluster scheduling system, …
- Pro:
- simpler to reason about state of system with centralized master
- Caveats:
- careful design required to keep master out of common case ops
- scales to 1000s of workers, but not 100,000s of workers
4.6. Pattern: Tree Distribution of Requests
这个模型本质上是从single master模型发展过来的,是multi master实现。随着master管理worker数目增加,CPU以及network IO都会bounded. 以single master为例,如果每个master最多管理1k worker的话,那么1k master可以由另外一个master管理,这样就可以支持1k * 1k worker级别了。
- Problem: Single machine sending 1000s of RPCs overloads NIC on machine when handling replies
- wide fan in causes TCP drops/retransmits, significant latency
- CPU becomes bottleneck on single machine
- Solution: Use tree distribution of requests/responses
- fan in at root is smaller
- cost of processing leaf responses spread across many parents
- Most effective when parent processing can trim/combine leaf data
- can also co-locate parents on same rack as leaves
4.7. Pattern: Backup Requests to Minimize Latency
通过backup request来降低延迟,因为部分请求可能会成为straggler,这点在mapreduce里面的speculative非常经典。 #note: jeff dean在另外一篇文章tail at scale里面也提到即便如何也存在一些bad case
- Problem: variance high when requests go to 1000s of machines
- last few machines to respond stretch out latency tail substantially
- Often, multiple replicas can handle same kind of request
- When few tasks remaining, send backup requests to other replicas
- Whichever duplicate request finishes first wins
- useful when variance is unrelated to specifics of request
- increases overall load by a tiny percentage
- decreases latency tail significantly
- Examples:
- MapReduce backup tasks (granularity: many seconds)
- various query serving systems (granularity: milliseconds)
4.8. Pattern: Multiple Smaller Units per Machine
每个机器上部署更小的单元,可以使得调度更加容易,集群资源利用率更高。
- Problems:
- want to minimize recovery time when machine crashes
- want to do fine-grained load balancing
- Having each machine manage 1 unit of work is inflexible
- slow recovery: new replica must recover data that is O(machine state) in size
- load balancing much harder
- Have each machine manage many smaller units of work/data
- typical: ~10-100 units/machine
- allows fine grained load balancing (shed or add one unit)
- fast recovery from failure (N machines each pick up 1 unit)
- Examples:
- map and reduce tasks, GFS chunks, Bigtable tablets, query serving system index shards
4.9. Pattern: Elastic Systems
可伸缩的系统,自动调节整个集群资源利用率。这个东西可以打个比方,如果整个集群资源空闲的话,那么可以减少线程数目,释放一些内存让其他程序可以有效运行。而当压力比较大的时候,可以保持在一个水平不至于崩溃。
- Problem: Planning for exact peak load is hard
- overcapacity: wasted resources
- undercapacity: meltdown
- Design system to adapt:
- automatically shrink capacity during idle period
- automatically grow capacity as load grows
- Make system resilient to overload:
- do something reasonable even up to 2X planned capacity
- e.g. shrink size of index searched, back off to less CPU intensive algorithms, drop spelling correction tips, etc.
- more aggressive load balancing when imbalance more severe
- do something reasonable even up to 2X planned capacity
4.10. Pattern: Combine Multiple Implementations
多种实现的结合,这点以realtime + batch说明非常直观。
- Example: Google web search system wants all of these:
- freshness (update documents in ~1 second)
- massive capacity (10000s of requests per second)
- high quality retrieval (lots of information about each document)
- massive size (billions of documents)
- Very difficult to accomplish in single implementation
- Partition problem into several subproblems with different engineering tradeoffs. E.g.
- realtime system: few docs, ok to pay lots of $$$/doc
- base system: high # of docs, optimized for low $/doc
- realtime+base: high # of docs, fresh, low $/doc
5. Final Thoughts
- Today: exciting collection of trends: 未来趋势的一些思考
- large-scale datacenters + 大规模数据中心建设
- increasing scale and diversity of available data sets + 大量数据需要分析和挖掘
- proliferation of more powerful client devices 各种设备接入
- Many interesting opportunities: 值得去做的事情
- planetary scale distributed systems 宇宙级别分布式系统
- development of new CPU and data intensive services 新的CPU和数据密集服务
- new tools and techniques for constructing such systems 以及构建这些服务的工具