Project Tungsten: Bringing Spark Closer to Bare Metal
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
Project Tungsten will be the largest change to Spark’s execution engine since the project’s inception. It focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware. This effort includes three initiatives:(主要是改进CPU和内存使用效率)
- Memory Management and Binary Processing: leveraging application semantics to manage memory explicitly and eliminate the overhead of JVM object model and garbage collection(内存管理和二进制数据处理)
- Cache-aware computation: algorithms and data structures to exploit memory hierarchy(充分利用内存层次性来加快计算)
- Code generation: using code generation to exploit modern compilers and CPUs(动态代码生成)
The focus on CPU efficiency is motivated by the fact that Spark workloads are increasingly bottlenecked by CPU and memory use rather than IO and network communication. This trend is shown by recent research on the performance of big data workloads (Ousterhout et al) and we’ve arrived at similar findings as part of our ongoing tuning and optimization efforts for Databricks Cloud customers.(最近研究表明Spark使用场景下性能更加受限于CPU和内存,而非磁盘和网络)
Why is CPU the new bottleneck? There are many reasons for this. One is that hardware configurations offer increasingly large aggregate IO bandwidth, such as 10Gbps links in networks and high bandwidth SSD’s or striped HDD arrays for storage. From a software perspective, Spark’s optimizer now allows many workloads to avoid significant disk IO by pruning input data that is not needed in a given job. In Spark’s shuffle subsystem, serialization and hashing (which are CPU bound) have been shown to be key bottlenecks, rather than raw network throughput of underlying hardware. All these trends mean that Spark today is often constrained by CPU efficiency and memory pressure rather than IO.(CPU成为瓶颈原因有:1. 使用更高IO带宽硬件,比如万兆网卡,高带宽SSD或者是带状HDD阵列 2. spark优化器裁剪了很多不必要的数据和计算过程 3. shuffle子系统中序列化和hash逐渐成为瓶颈)
Memory Management and Binary Processing
Applications on the JVM typically rely on the JVM’s garbage collector to manage memory. The JVM is an impressive engineering feat, designed as a general runtime for many workloads. However, as Spark applications push the boundary of performance, the overhead of JVM objects and GC becomes non-negligible.(JVM对象和GC的overhead不可忽视)
Java objects have a large inherent memory overhead. Consider a simple string “abcd” that would take 4 bytes to store using UTF-8 encoding. JVM’s native String implementation, however, stores this differently to facilitate more common workloads. It encodes each character using 2 bytes with UTF-16 encoding, and each String object also contains a 12 byte header and 8 byte hash code, as illustrated by the following output from the the Java Object Layout tool.(每个字符使用2字节UTF-16编码 + 12字节head + 8字节hashcode)
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) ...
4 4 (object header) ...
8 4 (object header) ...
12 4 char[] String.value []
16 4 int String.hash 0
20 4 int String.hash32 0
Instance size: 24 bytes (reported by Instrumentation API)
A simple 4 byte string becomes over 48 bytes in total in the JVM object model!( 所以如果是4个字符的串的话,占用2 * 4 + 12 + 8 = 28字节)
The other problem with the JVM object model is the overhead of garbage collection. At a high level, generational garbage collection divides objects into two categories: ones that have a high rate of allocation/deallocation (the young generation) ones that are kept around (the old generation). Garbage collectors exploit the transient nature of young generation objects to manage them efficiently. This works well when GC can reliably estimate the life cycle of objects, but falls short if the estimation is off (i.e. some transient objects spill into the old generation). Since this approach is ultimately based on heuristics and estimation, seeking out performance can require the “black magic” of GC tuning, with dozens of parameters to give the JVM more information about the life cycle of objects.(分代GC会把所有objects分为young和old两类,认为young objects操作会比较频繁而odl objects则相对稳定,以此来做优化。但是如果这个假设不成立或者是对对象生命时间判断不准确的话,那么分为GC性能就会下降。分代GC也是使用启发式算法来区分young/old objects, 我们可以通过调参和告诉GC对象生命周期的更多信息来进行优化,可是GC调优本身就比较复杂)
Spark, however, is not just a general-purpose application. Spark understands how data flows through various stages of computation and the scope of jobs and tasks. As a result, Spark knows much more information than the JVM garbage collector about the life cycle of memory blocks, and thus should be able to manage memory more efficiently than the JVM.(索性的是Spark本身不是一个general-purpose应用,它知道各个阶段的数据流以及计算,所以可以显式地管理内存。这种显式地管理内存效果会比JVM GC要更好)
To tackle both object overhead and GC’s inefficiency, we are introducing an explicit memory manager to convert most Spark operations to operate directly against binary data rather than Java objects. This builds on sun.misc.Unsafe, an advanced functionality provided by the JVM that exposes C-style memory access (e.g. explicit allocation, deallocation, pointer arithmetics). Furthermore, Unsafe methods are intrinsic, meaning each method call is compiled by JIT into a single machine instruction.(使用sun.misc.Unsafe来自己管理内存。这些unsafe方法都是intrinsic的,每次调用仅仅对应一条机器指令,开销很小)
In certain areas, Spark has already started using explicitly managed memory. Last year, Databricks contributed a new Netty-based network transport that explicitly manages all network buffers using a jemalloc like memory manager. That was critical in scaling up Spark’s shuffle operation and winning the Sort Benchmark.(显式地管理内存在特定地方已经使用。去年通过修改基于netty的网络传输层,使用jemalloc来显式地管理网络数据,对于提升shuffle性能非常有帮助)
Cache-aware Computation
Before we explain cache-aware computation, let’s revisit “in-memory” computation. Spark is widely known as an in-memory computation engine. What that term really means is that Spark can leverage the memory resources on a cluster efficiently, processing data at a rate much higher than disk-based solutions. However, Spark can also process data orders magnitude larger than the available memory, transparently spill to disk and perform external operations such as sorting and hashing.(Spark并不要求数据一定要完全地存放在内存中,而是通过尽可能地将数据放在内存中来加快计算)
Similarly, cache-aware computation improves the speed of data processing through more effective use of L1/ L2/L3 CPU caches, as they are orders of magnitude faster than main memory. When profiling Spark user applications, we’ve found that a large fraction of the CPU time is spent waiting for data to be fetched from main memory. As part of Project Tungsten, we are designing cache-friendly algorithms and data structures so Spark applications will spend less time waiting to fetch data from memory and more time doing useful work.(同理充分利用L1/L2/L3 CPU cache, 可以进一步加快计算速度。通过profile发现有很大一部分CPU时间在等待从内存中取数据,所以在project tungsten中通过设计cache友好的算法和数据结构来解决这个问题)
Consider sorting of records as an example. A standard sorting procedure would store an array of pointers to records and use quicksort to swap pointers until all records are sorted. Sorting in general has good cache hit rate due to the sequential scan access pattern. Sorting a list of pointers, however, has a poor cache hit rate because each comparison operation requires dereferencing two pointers that point to randomly located records in memory.(下面是一个例子,如果record是按照native layout组织的话,那么在排序的时候需要做一次内存间接访问,会存在locality问题)
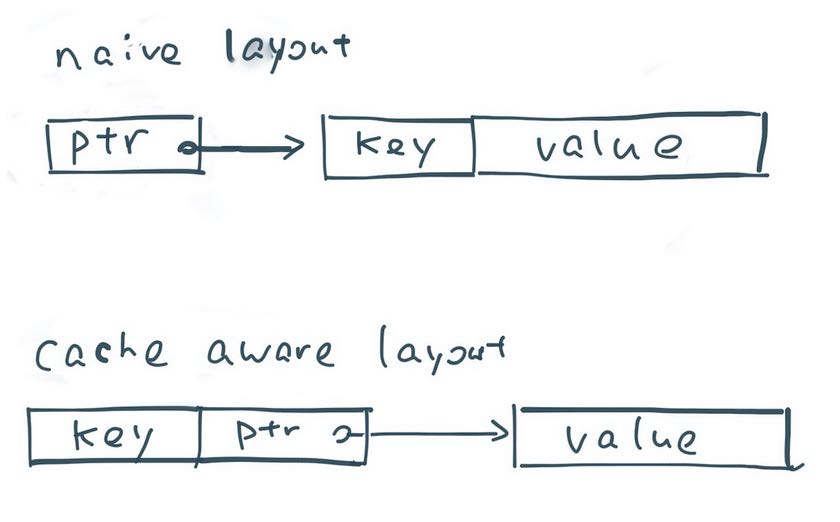
So how do we improve the cache locality of sorting? A very simple approach is to store the sort key of each record side by side with the pointer. For example, if the sort key is a 64-bit integer, then we use 128-bit (64-bit pointer and 64-bit key) to store each record in the pointers array. This way, each quicksort comparison operation only looks up the pointer-key pairs in a linear fashion and requires no random memory lookup. Hopefully the above illustration gives you some idea about how we can redesign basic operations to achieve higher cache locality(把key放在ptr附近,这样所有record的key都是连续存放的,所以data-locality比较好,也可以充分利用CPU Cache)
Code Generation
About a year ago Spark introduced code generation for expression evaluation in SQL and DataFrames. Expression evaluation is the process of computing the value of an expression (say “age > 35 && age < 40”) on a particular record. At runtime, Spark dynamically generates bytecode for evaluating these expressions, rather than stepping through a slower interpreter for each row. Compared with interpretation, code generation reduces the boxing of primitive data types and, more importantly, avoids expensive polymorphic function dispatches.(在处理SQL和DataFrames就引入了code generation,效率远高于interpretation,不用再对原始类型做boxing, 也避免了开销巨大的method dispatches)
In an earlier blog post, we demonstrated that code generation could speed up many TPC-DS queries by almost an order of magnitude. We are now broadening the code generation coverage to most built-in expressions. In addition, we plan to increase the level of code generation from record-at-a-time expression evaluation to vectorized expression evaluation, leveraging JIT’s capabilities to exploit better instruction pipelining in modern CPUs so we can process multiple records at once.(表达式计算矢量化,同时处理多条记录)
We’re also applying code generation in areas beyond expression evaluations to optimize the CPU efficiency of internal components. One area that we are very excited about applying code generation is to speed up the conversion of data from in-memory binary format to wire-protocol for shuffle. As mentioned earlier, shuffle is often bottlenecked by data serialization rather than the underlying network. With code generation, we can increase the throughput of serialization, and in turn increase shuffle network throughput.(除了优化表达式计算外,还可以用来优化对象的序列化和反序列化,从而提高shuffle效率)
Tungsten and Beyond
There are also a handful of longer term possibilities for Tungsten. In particular, we plan to investigate compilation to LLVM or OpenCL, so Spark applications can leverage SSE/SIMD instructions out of modern CPUs and the wide parallelism in GPUs to speed up operations in machine learning and graph computation.(将计算过程编译成为LLVM/OpenCL, 从而充分利用CPU SIMD以及GPU并行特性)