Large-scale cluster management at Google with Borg
Table of Contents
http://research.google.com/pubs/pub43438.html @ 2015
1. Abstract
Google’s Borg system is a cluster manager that runs hun-dreds of thousands of jobs, from many thousands of differ-ent applications, across a number of clusters each with up to tens of thousands of machines. # 管理多个机群,单个机群可以扩展到数万台机器,调度上千种不同类型应用以及数十万个作业
It achieves high utilization by combining admission con-trol, efficient task-packing, over-commitment, and machine sharing with process-level performance isolation. # 权限管理,有效的任务拼搭,资源过量使用, 机器资源共享但是保证进程资源隔离
It supports high-availability applications with runtime features that min-imize fault-recovery time, and scheduling policies that re-duce the probability of correlated failures. # 调度会尽可能减少应用错误恢复时间,以及减少相互关联失败的概率
Borg simplifies life for its users by offering a declarative job specification language, name service integration, real-time job monitor-ing, and tools to analyze and simulate system behavior. # 提供作业描述语言,集成名字服务,作业监控以及可以用来分析和模拟系统行为的工具
2. Introduction
Borg provides three main benefits:
- (1) hides the details of resource management and failure handling so its users can focus on application development instead;
- (2) operates with very high reliability and availability, and supports applica-tions that do the same; and
- (3) lets us run workloads across tens of thousands of machines effectively.
This paper is organized around these topics, con-cluding with a set of qualitative observations we have made from operating Borg in production for more than a decade. # Borg在生产环境中已经使用了十多年
3. The user perspective
Borg’s users are Google developers and system administra-tors (site reliability engineers or SREs) that run Google’s applications and services. Users submit their work to Borg in the form of jobs, each of which consists of one or more tasks that all run the same program (binary). Each job runs in one Borg cell, a set of machines that are managed as a unit. The remainder of this section describes the main fea-tures exposed in the user view of Borg. # 用户提交作业,作业包含任务。每个作业只能跑在一个borg cell。borg cell是集群管理单元,包含一批机器。
3.1. The workload
Borg cells run a heterogenous workload with two main parts. # 两类workload
- The first is long-running services that should “never” go down, and handle short-lived latency-sensitive requests (a few μs to a few hundred ms). Such services are used for end-user-facing products such as Gmail, Google Docs, and web search, and for internal infrastructure services (e.g., BigTable). # 长时间运行的服务,处理响应时间较短延迟敏感的请求
- The second is batch jobs that take from a few seconds to a few days to complete; these are much less sen-sitive to short-term performance fluctuations. # batch作业通常会花费几秒到几天,对于短期性能波动变化不太敏感
The workload mix varies across cells, which run different mixes of applica-tions depending on their major tenants (e.g., some cells are quite batch-intensive), and also varies over time: batch jobs come and go, and many end-user-facing service jobs see a diurnal usage pattern. Borg is required to handle all these cases equally well. # 每个cell都会混合这两种workload,很难说某个一cell专门为一种workload服务
For this paper, we classify higher-priority Borg jobs as “production” (prod) ones, and the rest as “non-production” (non-prod). Most long-running server jobs are prod; most batch jobs are non-prod. In a representative cell, prod jobs are allocated about 70% of the total CPU resources and rep-resent about 60% of the total CPU usage; they are allocated about 55% of the total memory and represent about 85% of the total memory usage. The discrepancies between alloca-tion and usage will prove important in §5.5. # 作业分为生产作业(prod)以及非生产作业(non-prod). 通常来说workload A是prod, 而workload B是non-prod. 在一个典型的cell上,prod作业要求60%的CPU使用量但是实际会使用70%,而non-prod作业要求85%的内存使用但是却使用55%. 这种差异比较重要会在后面分析。
3.2. Clusters and cells
The machines in a cell belong to a single cluster, defined by the high-performance datacenter-scale network fabric that connects them. A cluster lives inside a single datacenter building, and a collection of buildings makes up a site. A cluster usually hosts one large cell and may have a few smaller-scale test or special-purpose cells. We assiduously avoid any single point of failure. # 一个cluster由许多机器组成,之间使用高性能datacenter-scale的网络光纤连接。一个cluster就是在一个datacenter building里面,多个buildings组成一个site(比如CA site). 一个cluster通常会包含一个大cell, 和一些其他测试和特殊用途的多个小cell.
Our median cell size is about 10 k machines after exclud-ing test cells; some are much larger. The machines in a cell are heterogeneous in many dimensions: sizes (CPU, RAM, disk, network), processor type, performance, and capabili-ties such as an external IP address or flash storage. Borg iso-lates users from most of these differences by determining where in a cell to run tasks, allocating their resources, in-stalling their programs and other dependencies, monitoring their health, and restarting them if they fail. # 中等规模cell大小在10k,这些机器在许多维度CPU内存磁盘网络上都是异构的
3.3. Jobs and tasks
A Borg job’s properties include its name, owner, and the number of tasks it has. Jobs can have constraints to force its tasks to run on machines with particular attributes such as processor architecture, OS version, or an external IP address. Constraints can be hard or soft; the latter act like preferences rather than requirements. The start of a job can be deferred until a prior one finishes. A job runs in just one cell. # 一个job只能在一个cell上运行,作业属性包括名字,owner以及任务。可以对任务运行环境做约束 [软约束(preferences而非强制)] 包括处理器架构,操作系统版本以及外部IP地址等。作业还可以指定运行顺序,等待前面一个作业完成之后再启动。
Each task maps to a set of Linux processes running in a container on a machine. The vast majority of the Borg workload does not run inside virtual machines (VMs), because we don’t want to pay the cost of virtualization. Also, the system was designed at a time when we had a considerable investment in processors with no virtualization support in hardware. # 使用容器而非虚拟机做隔离,一方面是因为虚拟机开销大,另外一方面是系统设计之初对一些支持虚拟化的处理器有过很深入的研究
A task has properties too, such as its resource require-ments and the task’s index within the job. Most task proper-ties are the same across all tasks in a job, but can be over-ridden – e.g., to provide task-specific command-line flags. Each resource dimension (CPU cores, RAM, disk space, disk access rate, TCP ports, 2 etc.) is specified independently at fine granularity; we don’t impose fixed-sized buckets or slots (§5.4). Borg programs are statically linked to reduce dependencies on their runtime environment, and structured as packages of binaries and data files, whose installation is orchestrated by Borg. # 每个任务可以覆盖作业指定的资源约束和描述等。每个任务都有自己在这个作业中的唯一编号。所有任务都静态链接了Borg库这样可以和Borg交互以及使用Borg提供的服务。
Users operate on jobs by issuing remote procedure calls (RPCs) to Borg, most commonly from a command-line tool, other Borg jobs, or our monitoring systems (§2.6). Most job descriptions are written in the declarative configuration lan-guage BCL. This is a variant of GCL, which gener-ates protobuf files, extended with some Borg-specific keywords. GCL provides lambda functions to allow calcula-tions, and these are used by applications to adjust their con-figurations to their environment; tens of thousands of BCL files are over 1 k lines long, and we have accumulated tens of millions of lines of BCL. Borg job configurations have similarities to Aurora configuration files. # 用户可以使用命令行,或者是其他Borg作业,或者是监控系统来操作作业,底层都是使用RPC。使用BCL来描述作业,最终生成一系列protobuf文件
A user can change the properties of some or all of the tasks in a running job by pushing a new job configuration to Borg, and then instructing Borg to update the tasks to the new specification. This acts as a lightweight, non-atomic transaction that can easily be undone until it is closed (com-mitted). Updates are generally done in a rolling fashion, and a limit can be imposed on the number of task disruptions (reschedules or preemptions) an update causes; any changes that would cause more disruptions are skipped. # 用户可以通过推送新的作业描述来更新作业或者是其中部分任务,Borg允许用户指定每次中断更新任务的数量上限来平滑升级
Some task updates (e.g., pushing a new binary) will al-ways require the task to be restarted; some (e.g., increasing resource requirements or changing constraints) might make the task no longer fit on the machine, and cause it to be stopped and rescheduled; and some (e.g., changing priority) can always be done without restarting or moving the task. # 更新任务可能需要重启,重新分配机器资源或者是迁移到其他机器上,当然也可能不用重启
Tasks can ask to be notified via a Unix SIGTERM sig-nal before they are preempted by a SIGKILL, so they have time to clean up, save state, finish any currently-executing requests, and decline new ones. The actual notice may be less if the preemptor sets a delay bound. In practice, a notice is delivered about 80% of the time. # 任务在被取代之前会先用SIGTERM通知然后再SIGKILL,这样可以可以做些清理工作。
3.4. Allocs
A Borg alloc (short for allocation) is a reserved set of re-sources on a machine in which one or more tasks can be run; the resources remain assigned whether or not they are used. Allocs can be used to set resources aside for future tasks, to retain resources between stopping a task and start-ing it again, and to gather tasks from different jobs onto the same machine – e.g., a web server instance and an associ-ated logsaver task that copies the server’s URL logs from the local disk to a distributed file system. The resources of an alloc are treated in a similar way to the resources of a ma-chine; multiple tasks running inside one share its resources. If an alloc must be relocated to another machine, its tasks are rescheduled with it. # alloc是指在一台机器上的分配资源集合,alloc可以被预留来为不同的task服务。alloc-set则是指alloc集合,可以认为是作业运行所使用的资源。
An alloc set is like a job: it is a group of allocs that reserve resources on multiple machines. Once an alloc set has been created, one or more jobs can be submitted to run in it. For brevity, we will generally use “task” to refer to an alloc or a top-level task (one outside an alloc) and “job” to refer to a job or alloc set. # 所以可以简单地认为,对用户提交的作业,Borg需要分配alloc-set来为作业提供资源,每个task会对应到一个alloc.
3.5. Priority, quota, and admission control
What happens when more work shows up than can be ac-commodated? Our solutions for this are priority and quota. # 使用优先级和配额来做资源分配。配额是指这个作业使用的资源上限,注意和task使用资源区分开。
Every job has a priority, a small positive integer. A high-priority task can obtain resources at the expense of a lower-priority one, even if that involves preempting (killing) the latter. Borg defines non-overlapping priority bands for dif-ferent uses, including (in decreasing-priority order): moni-toring, production, batch, and best effort (also known as testing or free). For this paper, prod jobs are the ones in the monitoring and production bands. # 作业分配优先级,高优先级作业可以杀死低优先级作业。优先级分为5个bands, 其中prod作业处于monitoring和production bands中优先级别很高。
Although a preempted task will often be rescheduled elsewhere in the cell, preemption cascades could occur if a high-priority task bumped out a slightly lower-priority one, which bumped out another slightly-lower priority task, and so on. To eliminate most of this, we disallow tasks in the production priority band to preempt one another. Fine-grained priorities are still useful in other circumstances –e.g., MapReduce master tasks run at a slightly higher priority than the workers they control, to improve their reliability. # 之所以引入band是因为想减少级联kill,这样因为级联kill最多造成3个task受到影响(monitoring task -> production task -> batch task -> best effort task)
Priority expresses relative importance for jobs that are running or waiting to run in a cell. Quota is used to decide which jobs to admit for scheduling. Quota is expressed as a vector of resource quantities (CPU, RAM, disk, etc.) at a given priority, for a period of time (typically months). The quantities specify the maximum amount of resources that a user’s job requests can ask for at a time (e.g., “20 TiB of RAM at prod priority from now until the end of July in cell xx”). Quota-checking is part of admission control, not scheduling: jobs with insufficient quota are immediately rejected upon submission. # 配额是一组向量,包括各种资源使用量,使用优先级别,以及使用时长。配额检测只参与准入而并不参与调度。
Higher-priority quota costs more than quota at lower-priority. Production-priority quota is limited to the actual resources available in the cell, so that a user who submits a production-priority job that fits in their quota can expect it to run, modulo fragmentation and constraints. Even though we encourage users to purchase no more quota than they need, many users overbuy because it insulates them against future shortages when their application’s user base grows. We respond to this by over-selling quota at lower-priority levels: every user has infinite quota at priority zero, although this is frequently hard to exercise because resources are over-subscribed. A low-priority job may be admitted but remain pending (unscheduled) due to insufficient resources. # 许多作业会对要求比实际使用高的资源配额,以防止应用不断发展未来资源短缺的情况。
Quota allocation is handled outside of Borg, and is inti-mately tied to our physical capacity planning, whose results are reflected in the price and availability of quota in differ-ent datacenters. User jobs are admitted only if they have suf-ficient quota at the required priority. The use of quota re-duces the need for policies like Dominant Resource Fairness (DRF). # 配额计算是在Borg外部完成的。使用配额就可以避免使用DRF这样的策略。
Borg has a capability system that gives special privileges to some users; for example, allowing administrators to delete or modify any job in the cell, or allowing a user to access restricted kernel features or Borg behaviors such as disabling resource estimation (§5.5) on their jobs. # 管理员权限
3.6. Naming and monitoring
It’s not enough to create and place tasks: a service’s clients and other systems need to be able to find them, even after they are relocated to a new machine. To enable this, Borg creates a stable “Borg name service” (BNS) name for each task that includes the cell name, job name, and task number. Borg writes the task’s hostname and port into a consistent, highly-available file in Chubby with this name, which is used by our RPC system to find the task endpoint. The BNS name also forms the basis of the task’s DNS name, so the fiftieth task in job jfoo owned by user ubar in cell cc would be reachable via 50.jfoo.ubar.cc.borg.google.com. Borg also writes job size and task health information into Chubby whenever it changes, so load balancers can see where to route requests to. # BNS是名字服务,所有启动task都会在BNS上注册自己的monitoring IP端口。BNS使用Chubby来实现。同时对于这些注册IP端口的task来说,chubby会为task生成一个DNS name,使用<cell-name, job-id, task-id>来唯一命名。Borg还会将作业大小以及task健康信息写入Chubby里面,这样LB就可以利用Chubby来做更好的负载均衡
Almost every task run under Borg contains a built-in HTTP server that publishes information about the health of the task and thousands of performance metrics (e.g., RPC latencies). Borg monitors the health-check URL and restarts tasks that do not respond promptly or return an HTTP er-ror code. Other data is tracked by monitoring tools for dash-boards and alerts on service level objective (SLO) violations. # 每个任务都会通过一个内置HTTP服务器来暴露自己的健康信息,性能指标与应用指标等。Borg会监控健康信息来决定是否需要重启,而其他监控工具则会监控其他数据来进行展示或者是报警
A service called Sigma provides a web-based user inter-face (UI) through which a user can examine the state of all their jobs, a particular cell, or drill down to individual jobs and tasks to examine their resource behavior, detailed logs, execution history, and eventual fate. Our applications gener-ate voluminous logs; these are automatically rotated to avoid running out of disk space, and preserved for a while after the task’s exit to assist with debugging. If a job is not running Borg provides a “why pending?” annotation, together with guidance on how to modify the job’s resource requests to better fit the cell. We publish guidelines for “conforming” resource shapes that are likely to schedule easily. # Sigma提供Web-Based UI来方便用户查看每个作业的状态以及任务日志
Borg records all job submissions and task events, as well as detailed per-task resource usage information in Infrastore, a scalable read-only data store with an interactive SQL-like interface via Dremel. This data is used for usage-based charging, debugging job and system failures, and long-term capacity planning. It also provided the data for the Google cluster workload trace。 # Borg还会记录所有的作业提交以及任务事件,然后将这些数据导入Dremel,日后可以使用这些数据做费用分析,系统调试,以及容量规划,还有分析整个机群负载情况
All of these features help users to understand and debug the behavior of Borg and their jobs, and help our SREs manage a few tens of thousands of machines per person. # SRE可以每个人管理上万台机器
4. Borg architecture
A Borg cell consists of a set of machines, a logically central-ized controller called the Borgmaster, and an agent process called the Borglet that runs on each machine in a cell (see Figure 1). All components of Borg are written in C++. # master-slave结构,使用C++编写
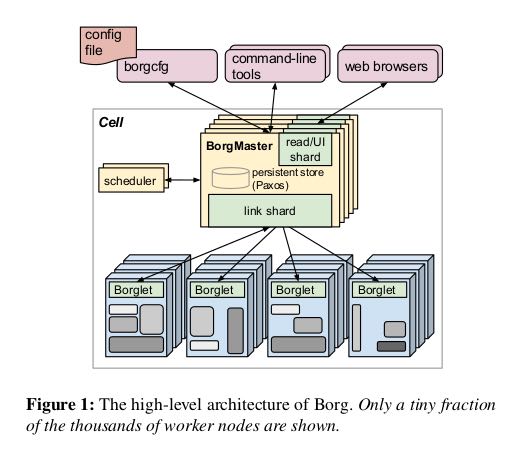
4.1. Borgmaster
Each cell’s Borgmaster consists of two processes: the main Borgmaster process and a separate scheduler (§3.2). The main Borgmaster process handles client RPCs that either mutate state (e.g., create job) or provide read-only access to data (e.g., lookup job). It also manages state machines for all of the objects in the system (machines, tasks, allocs, etc.), communicates with the Borglets, and offers a web UI as a backup to Sigma. # Borgmaster有两个进程,一个是主进程一个是调度进程。主进程处理客户RPC并且提供数据只读服务,和所有的Borglet通信维护当前所有cell的资源情况,然后提供WebUI作为Sigma后备.
The Borgmaster is logically a single process but is ac-tually replicated five times. Each replica maintains an in-memory copy of most of the state of the cell, and this state is also recorded in a highly-available, distributed, Paxos-based store on the replicas’ local disks. A single elected mas-ter per cell serves both as the Paxos leader and the state mutator, handling all operations that change the cell’s state, such as submitting a job or terminating a task on a ma-chine. A master is elected (using Paxos) when the cell is brought up and whenever the elected master fails; it acquires a Chubby lock so other systems can find it. Electing a master and failing-over to the new one typically takes about 10 s, but can take up to a minute in a big cell because some in-memory state has to be reconstructed. When a replica recovers from an outage, it dynamically re-synchronizes its state from other Paxos replicas that are up-to-date. # 使用Paxos来把资源以及调度信息做replication. 使用Chubby选主master,然后这个master响应客户请求并且发起replication evennts. 如果master失效的话,选出下一个master然后响应大约需要10s,大cell的话这个时间可能会到1分钟因为有部分in-memory状态需要重建。
The Borgmaster’s state at a point in time is called a checkpoint, and takes the form of a periodic snapshot plus a change log kept in the Paxos store. Checkpoints have many uses, including restoring a Borgmaster’s state to an arbitrary point in the past (e.g., just before accepting a request that triggered a software defect in Borg so it can be debugged); fixing it by hand in extremis; building a persistent log of events for future queries; and offline simulations. # borgmaster定期会将状态信息做checkpoint,然后paxos store里面只保存changelog. checkpoint都很多作用,包括恢复到历史状态,自己创建某个状态,以及做线下模拟。
A high-fidelity Borgmaster simulator called Fauxmaster can be used to read checkpoint files, and contains a complete copy of the production Borgmaster code, with stubbed-out interfaces to the Borglets. It accepts RPCs to make state ma-chine changes and perform operations, such as “schedule all pending tasks”, and we use it to debug failures, by interact-ing with it as if it were a live Borgmaster, with simulated Borglets replaying real interactions from the checkpoint file. A user can step through and observe the changes to the sys-tem state that actually occurred in the past. Fauxmaster is also useful for capacity planning (“how many new jobs of this type would fit?”), as well as sanity checks before mak-ing a change to a cell’s configuration (“will this change evict any important jobs?”). # 高度忠于Borgmaster行为的模拟器Fauxmaster可以读取checkpoint文件,然后模拟master行为然后来让开发者做一些事情比较容量规划等。
4.2. Scheduling
When a job is submitted, the Borgmaster records it persis-tently in the Paxos store and adds the job’s tasks to the pend-ing queue. This is scanned asynchronously by the scheduler, which assigns tasks to machines if there are sufficient avail-able resources that meet the job’s constraints. (The sched-uler primarily operates on tasks, not jobs.) The scan pro-ceeds from high to low priority, modulated by a round-robin scheme within a priority to ensure fairness across users and avoid head-of-line blocking behind a large job. The schedul-ing algorithm has two parts: feasibility checking, to find ma-chines on which the task could run, and scoring, which picks one of the feasible machines. # 一旦作业提交,borgmaster会将作业记录到paxos-store并且插入到queue中,而另外一个进程scheduler就不断地扫描这个queue,按照优先级顺序以及round-robin方式取出job分配资源运行。调度算法有两个部分 1. 可行性检查,找到任务可以运行的机器 2. 评分,从这些机器中选出一个。
In feasibility checking, the scheduler finds a set of ma-chines that meet the task’s constraints and also have enough “available” resources – which includes resources assigned to lower-priority tasks that can be evicted. In scoring, the scheduler determines the “goodness” of each feasible ma-chine. The score takes into account user-specified prefer-ences, but is mostly driven by built-in criteria such as mini-mizing the number and priority of preempted tasks, picking machines that already have a copy of the task’s packages, spreading tasks across power and failure domains, and pack-ing quality including putting a mix of high and low priority tasks onto a single machine to allow the high-priority ones to expand in a load spike. # 评分考虑到了用户偏好情况,但是主要考虑的还是内置标准,比如减少因为优先级抢占任务数量,选择一些已经有任务package的机器,让任务尽可能地分散开,将一些高低优先级任务混合部署在一台机器上等.
Borg originally used a variant of E-PVM for scoring, which generates a single cost value across heterogeneous resources and minimizes the change in cost when placing a task. In practice, E-PVM ends up spreading load across all the machines, leaving headroom for load spikes – but at the expense of increased fragmentation, especially for large tasks that need most of the machine; we sometimes call this“worst fit”.
The opposite end of the spectrum is “best fit”, which tries to fill machines as tightly as possible. This leaves some ma-chines empty of user jobs (they still run storage servers), so placing large tasks is straightforward, but the tight packing penalizes any mis-estimations in resource requirements by users or Borg. This hurts applications with bursty loads, and is particularly bad for batch jobs which specify low CPU needs so they can schedule easily and try to run opportunis-tically in unused resources: 20% of non-prod tasks request less than 0.1 CPU cores. # best fit对于批量作业不太友好,是因为批量作业指定较少资源但是寄希望于可以有机会利用到空闲资源。
Our current scoring model is a hybrid one that tries to reduce the amount of stranded resources – ones that cannot be used because another resource on the machine is fully allocated. It provides about 3–5% better packing efficiency than best fit for our workloads.
If the machine selected by the scoring phase doesn’t have enough available resources to fit the new task, Borg preempts (kills) lower-priority tasks, from lowest to highest priority, until it does. We add the preempted tasks to the scheduler’s pending queue, rather than migrate or hibernate them. # 任务被抢占后并不是立刻挂起或者是迁移,而是重新加入调度器队列进行调度。
Task startup latency (the time from job submission to a task running) is an area that has received and continues to receive significant attention. It is highly variable, with the median typically about 25 s. Package installation takes about 80% of the total: one of the known bottlenecks is contention for the local disk where packages are written to. To reduce task startup time, the scheduler prefers to assign tasks to machines that already have the necessary packages (programs and data) installed: most packages are immutable and so can be shared and cached. (This is the only form of data locality supported by the Borg scheduler.) In addition, Borg distributes packages to machines in parallel using tree-and torrent-like protocols. # 任务启动时间受到非常关注,中位数大约在25s,其中80%时间在package安装上,而安装中瓶颈则是在本地磁盘写入上。所以为了减少任务启动时间调度器倾向于调度在已经有package的机器上,另外borg还使用tree和torrent类似的协议来加快package分发。
Additionally, the scheduler uses several techniques to let it scale up to cells with tens of thousands of machines (§3.4). # 调度器扩展到上万台
4.3. Borglet
The Borglet is a local Borg agent that is present on every machine in a cell. It starts and stops tasks; restarts them if they fail; manages local resources by manipulating OS ker-nel settings; rolls over debug logs; and reports the state of the machine to the Borgmaster and other monitoring systems. # 启动和停止任务,管理本地资源,滚动日志,汇报资源情况
The Borgmaster polls each Borglet every few seconds to retrieve the machine’s current state and send it any outstand-ing requests. This gives Borgmaster control over the rate of communication, avoids the need for an explicit flow control mechanism, and prevents recovery storms. # master主动去拉取slave的状态
The elected master is responsible for preparing messages to send to the Borglets and for updating the cell’s state with their responses. For performance scalability, each Borgmas-ter replica runs a stateless link shard to handle the communi-cation with some of the Borglets; the partitioning is recalcu-lated whenever a Borgmaster election occurs. For resiliency, the Borglet always reports its full state, but the link shards aggregate and compress this information by reporting only differences to the state machines, to reduce the update load at the elected master. # 为了减少borglet给master造成的压力,每个master replica会收集一部分borglet的状态然后进行聚合,最后将差量汇报给elected master.
If a Borglet does not respond to several poll messages its machine is marked as down and any tasks it was running are rescheduled on other machines. If communication is restored the Borgmaster tells the Borglet to kill those tasks that have been rescheduled, to avoid duplicates. A Borglet continues normal operation even if it loses contact with the Borgmaster, so currently-running tasks and services stay up even if all Borgmaster replicas fail. # 如果borglet机器挂掉的话,那么master会重新将上面的tasks rescheduled. 如果borgmaster挂掉的话,borglet上面运行的tasks不会收到任何影响。
4.4. Scalability
We are not sure where the ultimate scalability limit to Borg’s centralized architecture will come from; so far, every time we have approached a limit, we’ve managed to eliminate it. A single Borgmaster can manage many thousands of ma-chines in a cell, and several cells have arrival rates above 10 000 tasks per minute. A busy Borgmaster uses 10–14 CPU cores and up to 50 GiB RAM. We use several tech-niques to achieve this scale. # 现在扩展性是每个cell可以到上千台机器,每个cell处理任务速度在每分钟10k,borgmaster采用的配置10-14核50GB内存属于中型服务器配置。
Early versions of Borgmaster had a simple, synchronous loop that accepted requests, scheduled tasks, and commu-nicated with Borglets. To handle larger cells, we split the scheduler into a separate process so it could operate in paral-lel with the other Borgmaster functions that are replicated for failure tolerance. A scheduler replica operates on a cached copy of the cell state. It repeatedly: retrieves state changes from the elected master (including both assigned and pend-ing work); updates its local copy; does a scheduling pass to assign tasks; and informs the elected master of those as-signments. The master will accept and apply these assign-ments unless they are inappropriate (e.g., based on out of date state), which will cause them to be reconsidered in the scheduler’s next pass. This is quite similar in spirit to the optimistic concurrency control used in Omega, and in-deed we recently added the ability for Borg to use different schedulers for different workload types. # 使用Omega MVCC scheduler来可以提高扩展性,每个scheduler都维护一个cached copy of cell state然后独立进行调度,调度完成之后在告诉master由master决定调度是否可行。对于大cell来说可能冲突没有想象的那么严重,那么这种办法可以提高扩展性
To improve response times, we added separate threads to talk to the Borglets and respond to read-only RPCs. For greater performance, we sharded (partitioned) these func-tions across the five Borgmaster replicas §3.3. Together, these keep the 99%ile response time of the UI below 1 s and the 95%ile of the Borglet polling interval below 10 s. # UI响应时间99%低于1s,Borglet轮询时间95%低于10s
Several things make the Borg scheduler more scalable:
- Score caching: Evaluating feasibility and scoring a ma-chine is expensive, so Borg caches the scores until the prop-erties of the machine or task change – e.g., a task on the ma-chine terminates, an attribute is altered, or a task’s require-ments change. Ignoring small changes in resource quantities reduces cache invalidations. # 如果task属性以及机器属性都没有变化的话,那么这个task在这个machine上的评分是不会变化的,所以我们可以cache起来。评分开销非常大
- Equivalence classes: Tasks in a Borg job usually have identical requirements and constraints, so rather than deter-mining feasibility for every pending task on every machine, and scoring all the feasible machines, Borg only does fea-sibility and scoring for one task per equivalence class – a group of tasks with identical requirements. # 通常一个作业会启动很多task,而这些task属性基本上都相同,所以可以利用这点来减少选择机器以及评分开销
- Relaxed randomization: It is wasteful to calculate fea-sibility and scores for all the machines in a large cell, so the scheduler examines machines in a random order until it has found “enough” feasible machines to score, and then selects the best within that set. This reduces the amount of scoring and cache invalidations needed when tasks enter and leave the system, and speeds up assignment of tasks to machines. Relaxed randomization is somewhat akin to the batch sam-pling of Sparrow while also handling priorities, preemp-tions, heterogeneity and the costs of package installation. # 通过随机化来选择部分机器集合而非全部机器来作为选择集合
In our experiments (§5), scheduling a cell’s entire work-load from scratch typically took a few hundred seconds, but did not finish after more than 3 days when the above tech-niques were disabled. Normally, though, an online schedul-ing pass over the pending queue completes in less than half a second. # 通常调度延迟在半秒以内
5. Availability
Failures are the norm in large scale systems. Figure 3 provides a breakdown of task eviction causes in 15 sample cells. Applications that run on Borg are expected to handle such events, using techniques such as replication, storing persistent state in a distributed file system, and (if appropriate) taking occasional checkpoints. Even so, we try to mitigate the impact of these events. For example, Borg: # 为了减少task eviction而造成的影响
- automatically reschedules evicted tasks, on a new ma-chine if necessary; # 重新调度被驱逐的任务
- reduces correlated failures by spreading tasks of a job across failure domains such as machines, racks, and power domains; # 将任务调度到其他机器上减少失败概率
- limits the allowed rate of task disruptions and the number of tasks from a job that can be simultaneously down during maintenance activities such as OS or machine upgrades; # 限制任务中断速度以及同时挂掉任务个数(升级维护时会使用)
- uses declarative desired-state representations and idem-potent mutating operations, so that a failed client can harmlessly resubmit any forgotten requests;
- rate-limits finding new places for tasks from machines that become unreachable, because it cannot distinguish between large-scale machine failure and a network parti-tion; # 因为机器unreachable而重新将task调度到其他机器上时需要考虑,是否可能是因为网络故障而非机器故障导致unreachable
- avoids repeating task::machine pairings that cause task or machine crashes; and # 避免哪些容易出故障的task::machine pair
- recovers critical intermediate data written to local disk by repeatedly re-running a logsaver task (§2.4), even if the alloc it was attached to is terminated or moved to another machine. Users can set how long the system keeps trying; a few days is common. # 恢复critical的中间状态
A key design feature in Borg is that already-running tasks continue to run even if the Borgmaster or a task’s Borglet goes down. But keeping the master up is still important because when it is down new jobs cannot be submitted or existing ones updated, and tasks from failed machines cannot be rescheduled.
Borgmaster uses a combination of techniques that enable it to achieve 99.99% availability in practice: replication for machine failures; admission control to avoid overload; and deploying instances using simple, low-level tools to mini-mize external dependencies. Each cell is independent of the others to minimize the chance of correlated operator errors and failure propagation. These goals, not scalability limita-tions, are the primary argument against larger cells. # borgmaster可用性在99.99%. 但是偏向选择中等规模cell而非大规模cell原因,是希望尽可能降低相互关联错误而非扩展性所限制。
6. Utilization
6.1. Resource reclamation
A job can specify a resource limit – an upper bound on the resources that each task should be granted. The limit is used by Borg to determine if the user has enough quota to admit the job, and to determine if a particular machine has enough free resources to schedule the task. Just as there are users who buy more quota than they need, there are users who request more resources than their tasks will use, because Borg will normally kill a task that tries to use more RAM or disk space than it requested, or throttle CPU to what it asked for. In addition, some tasks occasionally need to use all their resources (e.g., at peak times of day or while coping with a denial-of-service attack), but most of the time do not. # 虽然task有时候可以使用全部指定资源比如在高峰期间,但是大部分时候却没有。
Rather than waste allocated resources that are not cur-rently being consumed, we estimate how many resources a task will use and reclaim the rest for work that can tolerate lower-quality resources, such as batch jobs. This whole pro-cess is called resource reclamation. The estimate is called the task’s reservation, and is computed by the Borgmas-ter every few seconds, using fine-grained usage (resource-consumption) information captured by the Borglet. The ini-tial reservation is set equal to the resource request (the limit); after 300 s, to allow for startup transients, it decays slowly towards the actual usage plus a safety margin. The reserva-tion is rapidly increased if the usage exceeds it. # 为了避免浪费资源,borgmaster每隔几秒钟会通过borglet汇报信息来估算task预留资源,初始预留资源和task limit相同,启动300s之后(考虑到启动时候过渡时间资源使用)会逐渐减少预留资源(实际使用+margin). 如果一旦使用率上来资源预留又会增加。
The Borg scheduler uses limits to calculate feasibility (§3.2) for prod tasks, so they never rely on reclaimed re-sources and aren’t exposed to resource oversubscription; for non-prod tasks, it uses the reservations of existing tasks so the new tasks can be scheduled into reclaimed resources. A machine may run out of resources at runtime if the reservations (predictions) are wrong – even if all tasks use less than their limits. If this happens, we kill or throttle non-prod tasks, never prod ones. # prod tasks在选择机器时,使用上面有tasks limit来计算空闲资源,然后确定这台机器是否资源足够,所以不会存在资源回收导致的资源不够问题。对于non-prod tasks来说,使用上面tasks实际使用资源总和来计算空闲资源,所以一旦某几个task res usage上来的话,会出现资源不够的情况
7. Isolation
50% of our machines run 9 or more tasks; a 90%ile machine has about 25 tasks and will be running about 4500 threads. Although sharing machines between applications in-creases utilization, it also requires good mechanisms to pre-vent tasks from interfering with one another. This applies to both security and performance.
7.1. Security isolation
We use a Linux chroot jail as the primary security isolation mechanism between multiple tasks on the same machine. To allow remote debugging, we used to distribute (and rescind) ssh keys automatically to give a user access to a machine only while it was running tasks for the user. For most users, this has been replaced by the borgssh command, which col-laborates with the Borglet to construct an ssh connection to a shell that runs in the same chroot and cgroup as the task, locking down access even more tightly.
VMs and security sandboxing techniques are used to run external software by Google’s AppEngine (GAE) and Google Compute Engine (GCE). We run each hosted VM in a KVM process that runs as a Borg task.
7.2. Performance isolation
Early versions of Borglet had relatively primitive resource isolation enforcement: post-hoc usage checking of memory, disk space and CPU cycles, combined with termination of tasks that used too much memory or disk and aggressive ap-plication of Linux’s CPU priorities to rein in tasks that used too much CPU. But it was still too easy for rogue tasks to af-fect the performance of other tasks on the machine, so some users inflated their resource requests to reduce the number of tasks that Borg could co-schedule with theirs, thus decreas-ing utilization. Resource reclamation could claw back some of the surplus, but not all, because of the safety margins in-volved. In the most extreme cases, users petitioned to use dedicated machines or cells. # 早期隔离措施不是特别有效
Now, all Borg tasks run inside a Linux cgroup-based re-source container and the Borglet manipulates the container settings, giving much improved control because the OS kernel is in the loop. Even so, occasional low-level resource interference (e.g., memory bandwidth or L3 cache pollution) still happens. # 现在隔离是基于LXC来做的,borglet来控制容器各种设置,但是依然存在底层资源相互干扰比如内存带宽和L3 Cache污染
To help with overload and overcommitment, Borg tasks have an application class or appclass. The most important distinction is between the latency-sensitive (LS) appclasses and the rest, which we call batch in this paper. LS tasks are used for user-facing applications and shared infrastructure services that require fast response to requests. High-priority LS tasks receive the best treatment, and are capable of tem-porarily starving batch tasks for several seconds at a time. # 延迟敏感应用类别
A second split is between compressible resources (e.g., CPU cycles, disk I/O bandwidth) that are rate-based and can be reclaimed from a task by decreasing its quality of service without killing it; and non-compressible resources (e.g., memory, disk space) which generally cannot be re-claimed without killing the task. If a machine runs out of non-compressible resources, the Borglet immediately termi-nates tasks, from lowest to highest priority, until the remain-ing reservations can be met. If the machine runs out of com-pressible resources, the Borglet throttles usage (favoring LS tasks) so that short load spikes can be handled without killing any tasks. If things do not improve, Borgmaster will remove one or more tasks from the machine. # 对于可压缩资源的限制,可以通过调整rate来达到,比如CPU cycles以及IO带宽。对于不可压缩资源比如内存以及磁盘空间,只能是通过终止任务来做限制。
A user-space control loop in the Borglet assigns mem-ory to containers based on predicted future usage (for prod tasks) or on memory pressure (for non-prod ones); handles Out-of-Memory (OOM) events from the kernel; and kills tasks when they try to allocate beyond their memory lim-its, or when an over-committed machine actually runs out of memory. Linux’s eager file-caching significantly compli-cates the implementation because of the need for accurate memory-accounting.
To improve performance isolation, LS tasks can reserve entire physical CPU cores, which stops other LS tasks from using them. Batch tasks are permitted to run on any core, but they are given tiny scheduler shares relative to the LS tasks. The Borglet dynamically adjusts the resource caps of greedy LS tasks in order to ensure that they do not starve batch tasks for multiple minutes, selectively applying CFS bandwidth control when needed ; shares are insufficient because we have multiple priority levels.
Like Leverich, we found that the standard Linux CPU scheduler (CFS) required substantial tuning to support both low latency and high utilization. To reduce schedul-ing delays, our version of CFS uses extended per-cgroup load history , allows preemption of batch tasks by LS tasks, and reduces the scheduling quantum when multiple LS tasks are runnable on a CPU. Fortunately, many of our ap- plications use a thread-per-request model, which mitigates the effects of persistent load imbalances. We sparingly use cpusets to allocate CPU cores to applications with particu-larly tight latency requirements. Some results of these efforts are shown in Figure 13. Work continues in this area, adding thread placement and CPU management that is NUMA-, hyperthreading-, and power-aware, and improv- ing the control fidelity of the Borglet.
Tasks are permitted to consume resources up to their limit. Most of them are allowed to go beyond that for com-pressible resources like CPU, to take advantage of unused (slack) resources. Only 5% of LS tasks disable this, presum-ably to get better predictability; fewer than 1% of batch tasks do. Using slack memory is disabled by default, because it in-creases the chance of a task being killed, but even so, 10% of LS tasks override this, and 79% of batch tasks do so be-cause it’s a default setting of the MapReduce framework. This complements the results for reclaimed resources (§5.5). Batch tasks are willing to exploit unused as well as reclaimed memory opportunistically: most of the time this works, al-though the occasional batch task is sacrificed when an LS task needs resources in a hurry. # 大部分任务还允许对可压缩资源比如CPU超限使用, 只有5% LS应用没有这么做希望得到更好的可预测性,低于1% batch应用没有这么做。超限使用内存默认是关闭的,因为会增加OOM的几率,即便如此10% LS应用以及79% batch应用会这么做。超限使用和资源回收(resource reclamation)可以相互补充