BigLake BigQuery’s Evolution toward a Multi-Cloud Lakehouse
如何将bigquery做到支持multi-cloud以及lakehouse. multi-cloud这个依赖于文章里面提到的omni架构,主要是解决multi-cloud适配问题:部署,安全,数据增量传输等等。而lakehouse则是文章里面提到的biglake架构,包括具体两个技术分别是biglake managed tables(for open-source table format)和biglake object tables(for AI/ML). 因为我对multi-cloud也不是很了解,所以主要是看怎么支持lakehouse的,但是multi-cloud看上去细节也是蛮多的。
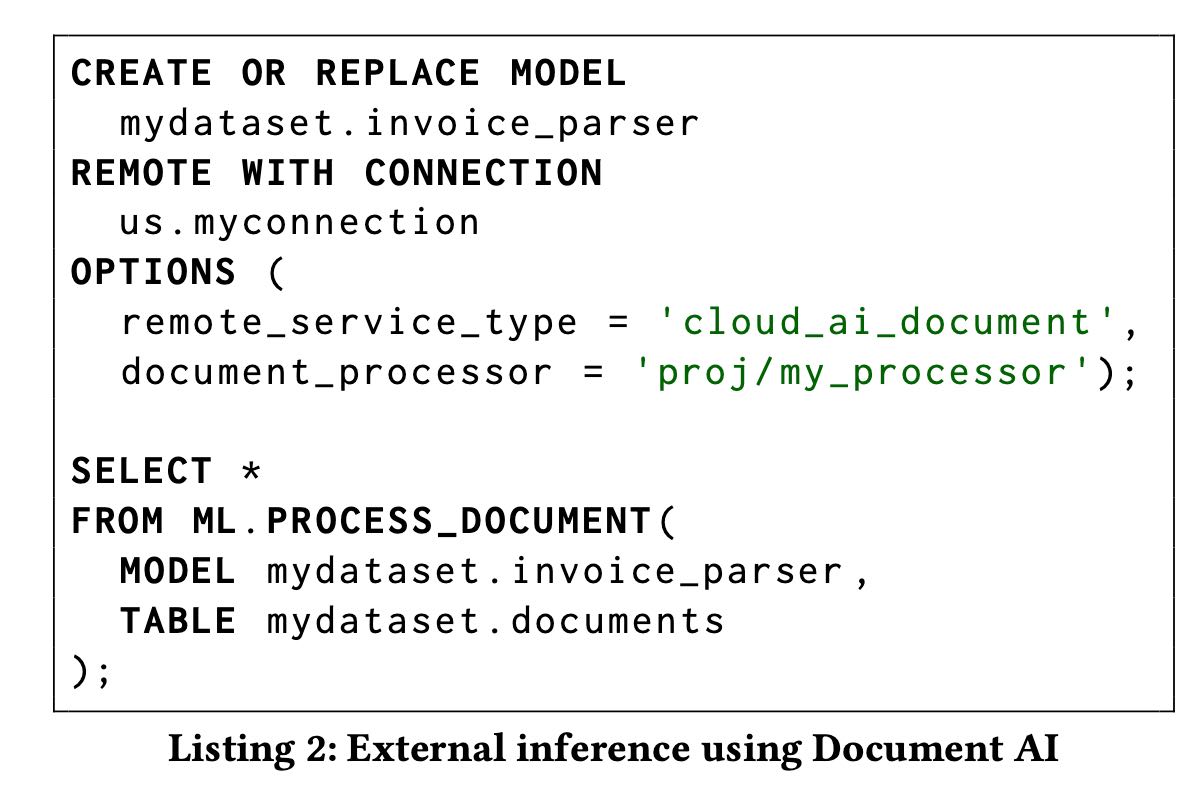
下图就是biglake arch.可以看到包含两个lakehouse: managed & open lakehouse. 另外可以看到可以对接多种分析引擎来查询上面的数据,所以还需要提供storage api用于读写
storage API中read API首先需要调用 `CreateReadSession` 传入各种参数然后返回一系列 stream objects, 这些stream objects上面可以并行发起读取,为了性能使用apache arrow来作为列式传输格式。write API也是类似,先调用 `CreateWriteSession` 产生stream objects,然后再这些stream objects进行写入。论文在这节没有详细说明支持什么格式,但是根据后面内容看似乎只支持parquet格式。parquet格式目前可以对接iceberg/deltalake. 相比orc算是更加“标准”了。 比如spark就支持使用bigquery connector(storage api)来访问biglake tables.
可以想象,如果要有效地给spark提供信息的话,read session就不能仅仅是返回stream objects, 还需要返回table/column statistics, 这样spark才能生成好的计划。所以目前biglake架构不仅仅需要管理好数据,还需要管理好metadata. 所以后台还是会不断收集这些统计信息:stats, partitions, files等等,存储在big metadata(spanner里面) 但是这些统计信息的同步是个问题。
[!NOTE] Open source tables that are not backed by modern managed table formats (e.g. Apache Iceberg [2], Apache Hudi [1], Delta Lake [10]) employ limited physical metadata: typically, only the file system prefix of a table or a partition is stored in the metadata. As a result, query engines need to perform listing operations on object storage buckets to obtain the list of data files to operate on. Listing of large cloud object store buckets with millions of files is inherently slow. On partitions that query engines cannot prune, the engine needs to peek at data file-level metadata, such as headers or footers, to determine if it can skip data blocks, requiring several additional object reads. These aspects can impose a significant overhead in query planning and execution.
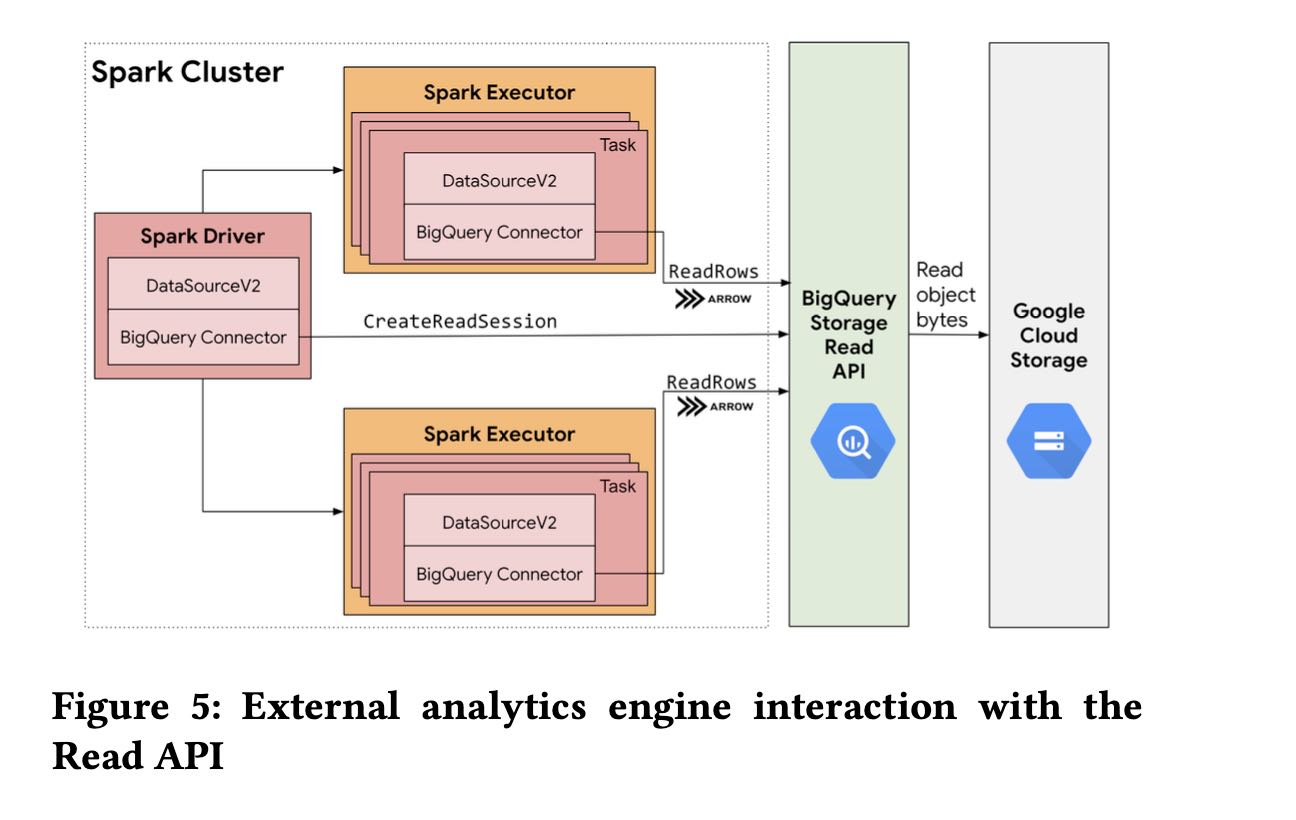
To accelerate query performance, BigLake tables support a fea- ture called metadata caching. Figure 3 shows how BigLake automat- ically collects and maintains physical metadata about files in object storage. BigLake tables use the same scalable physical metadata management system employed for BigQuery native tables, known as Big Metadata [22]. The use of Big Metadata allows using the same distributed query processing and data management techniques that we employ for managing data to handle metadata.
Using Big Metadata, BigLake tables cache file names, partitioning information, and physical metadata from data files, such as physical size, row counts and per-file column-level statistics in a columnar cache. The cache tracks metadata at a finer granularity than systems like the Hive Metastore [35, 36], allowing BigQuery and storage APIs to avoid listing files from object stores and achieve high- performance partition and file pruning.
The statistics collected in the physical metadata management layer enable both BigQuery and Apache Spark query engines to build optimized high-performance query plans. To measure the performance gains, we performed a power run of the TPC-DS 10T benchmark where each query is executed sequentially, on a Big- Query reservation with 2000 slots. Figure 4 shows the TPC-DS query speedup for a subset of the queries and how the BigQuery query execution time improved for queries through the statistics collected by the BigLake metadata layer. Overall, the wall clock execution time decreased by a factor of four with metadata caching.
如果没有办法做到统计信息的实时同步,那么就需要做好catalog/table的管理入口,这个就是biglake managed tables. 大致思想就是:全部按照parquet文件格式写入,写入的时候可以做好metadata管理,只不过在完成之后可以异步地更新到iceberg上。这样实现的话相当于元数据信息被自己管理起来了。其实某种程度上这个就可以认为是iceberg catalog了,并且在此基础上还支持multi-table txn.
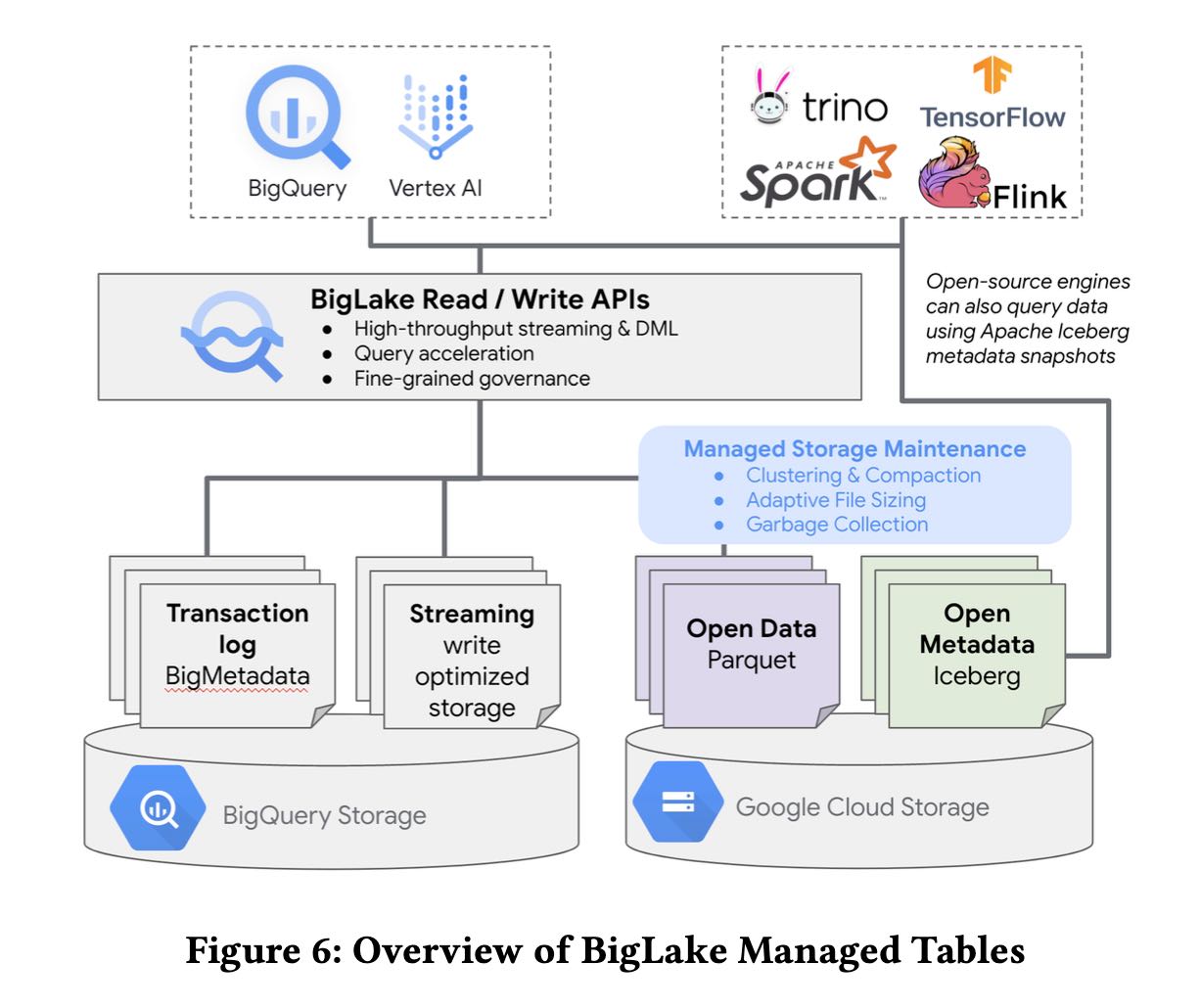
[!NOTE]
BigLake managed tables (BLMTs) offer the fully managed experi- ence of BigQuery managed tables while storing data in customer- owned cloud storage buckets using open file formats. BLMTs sup- port DML, high-throughput streaming through the Write API, and background storage optimizations (adaptive file sizing, file reclus- tering and coalescing, and garbage collection). Data is stored in Parquet, while metadata is stored and managed using Big Metadata. Users can export an Iceberg snapshot of the metadata into cloud storage, allowing any engine capable of understanding Iceberg to query the data directly. Iceberg snapshots are currently triggered using a SQL statement. In the future, the Iceberg snapshots will be automatically generated asynchronously as part of table commits.
BLMT is different from open table formats such as Iceberg and Delta Lake in a couple of aspects: • BLMTs are not constrained by the need to atomically commit metadata to an object store. Object stores can update/replace an object only a handful of times per second, thus placing a limit on the number of mutations per second that can be performed with pure object store tables. • Open table formats store the transaction log along with the data. A malicious writer can potentially tamper with the transaction log and rewrite table history.
Using Big Metadata as the metadata source-of-truth provide the following benefits:
• Write throughput. Big Metadata is backed by a stateful ser- vice that caches the tail of the transaction log in memory. Big Metadata periodically converts the transaction log to colum- nar baselines for read efficiency. During queries, Dremel reads the columnar baselines and reconciles it with the tail. The combination of in-memory state and columnar baselines allows table mutations at a rate much higher than what is possible with open table formats without sacrificing read performance. • Multi-table transactions. Reusing Big Metadata enables BLMT to support features such as multi-table transactions that are currently unsupported in open table formats. • Strong security model. Since writers cannot directly mutate the transaction log, the table metadata is tamper-proof with reliable audit history. Writers do not need to be trusted for security nor for correctness and integrity.
BigLake Object Tables允许将所有的Objects管理起来组织成为tables. 字段可以比如path, creation_time, attributes, 另外就是可以提供 `data` 这个关键属性表示文件内容。这些columns metadata都被管理在了big metadata下面,那么这样筛选某些条件文件的成本就可以很低,可以比较好地将这些训练/推理数据组织起来。
Object tables are system-maintained tables where each row repre- sents an object, and columns contain object attributes such as URI, object size, MIME type, creation time. The output of SELECT * on an object table is equivalent to ls or dir on a filesystem.
然后再这个基础上支持两种推理模型:内部推理(internal inference)模型和外部推理(external inference)模型。内部推理模型是biglake内部维护的模型,在推理的时候可以直接在worker上执行,但是模型大小因为dremel worker内存限制所以也有所限制,好处就是不需要data movement就可以完成推理。而外部推理模型则是读取数据之后就调用model REST API.