Anaconda High Performance Solution
下了他们一本白皮书看,名字叫做 "HIGH PERFORMANCE PYTHON FOR OPEN DATA SCIENCE". 主要是看Anaconda做Scale up和Scale out的方案.
Scale Up Approaches:
- Use multithreaded analytic libraries
- Compile Python into machine code
- Parallelize analytics
- Use multiprocessing
- Use multithreading
- Employ multi-core CPUs
- Leverage GPUs
The Anaconda platform easily delivers high performance analysis to Data Science teams by leveraging investments in all types of infrastructure to both Scale Up and Scale Out workloads. The Anaconda Python distribution is a high performance distribution of Python that has been compiled with the Intel® Math Kernel Library (MKL) that delivers faster throughput on numerically intensive calculations. Additionally, there are a multitude of Scale Up options available in Anaconda that allow Data Science workloads to maximize the investment in single-machine infrastructure.
Anaconda allows Data Science teams to turn high level Python scripts into high performance machine code that achieves comparable performance to C/C++ code. Scripts can be pre- compiled so that the machine executable code executes as a process that can be run standalone or embedded into an existing operational process. Alternatively, Python scripts can be compiled on-the-fly into machine code to achieve maximum throughput, even for ad hoc analysis. In either approach, Python scripts can also take advantage of precompiled libraries that have been optimized for the fastest throughput. These boost linear algebra and Fast Fourier Transformation (FFT) operations underpin the most popular Python numerical analysis libraries, including: NumPy, SciPy, scikit-learn and numexpr, by linking with the Intel® MKL. Additionally, powerful and flexible NumPy universal functions created with Anaconda can be automatically parallelized to take advantage of multi-core CPUs and GPUs.
Using Anaconda, Python scripts that leverage mathematically intensive calculations, such as in deep learning algorithms or image processing analytics, can be compiled for fast execution on GPUs, which perform large scale calculations quickly. Plus, Anaconda includes bindings that use the CUDA optimized version for basic linear algebra, FFT, sparse matrices, random number generator and sorting algorithms. For Intel-based CPUs, there is a special version of Anaconda available that has been compiled with the Intel® C++ Compiler (ICC) that boosts performance further.
Scale Out Approaches
- Use cluster
- Distribute workload across cluster
With Anaconda, Data Science teams can pushdown processing of analytic pipelines into heterogeneous data stores—CSV, SQL, NoSQL, Hadoop and KDB—moving analytic computations to the data, eliminating data movement to prevent I/O bottlenecks. Pushdown processing can be executed on both single machines and clusters.
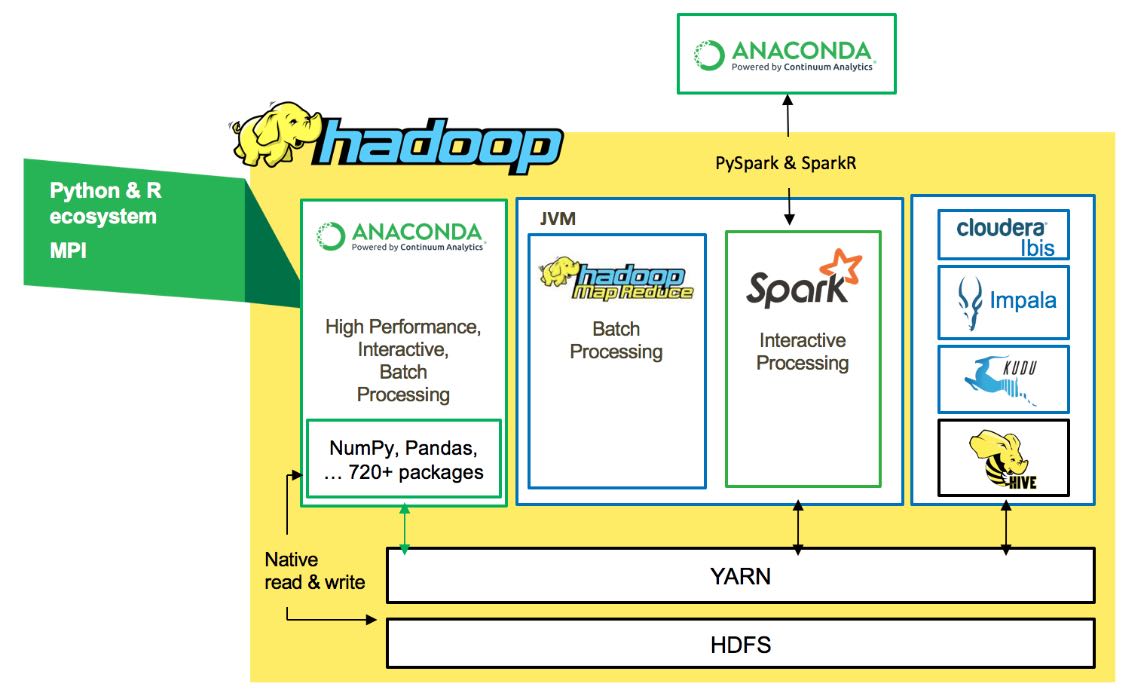
For Hadoop environments, Anaconda can leverage the Spark computing framework to perform either Python or R advanced analytics on a Hadoop cluster. Anaconda also includes a robust high performance parallel computing framework that operates with low overhead, latency and minimal serialization for fast numerical analysis.