Firecracker: Lightweight Virtualization for Serverless Applications
Table of Contents
Firecracker: Lightweight Virtualization for Serverless Applications | USENIX
1. abstract
传统观点认为虚拟化和容器化之间各有好处,容器化性能好,虚拟化安全性好。但是现在虚拟化也可以做到比较高的性能,前提是有内核支持比如KVM.
The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker se- curity and minimal overhead.
目前这个firecracker用在了lambda和fargate(k8s)上
We have deployed Firecracker in two publically-available serverless compute services at Ama- zon Web Services (Lambda and Fargate), where it supports millions of production workloads, and trillions of requests per month.
2. introduction
云上需要实现多租户的功能,资源共享和隔离是是最关键的功能,目前大部分云厂商使用qemu/kvm或者是kvm这样的hypervisor-based虚拟化方案。
Multitenancy, despite its economic opportunities, presents significant challenges in isolating workloads from one another. Workloads must be isolated both for security (so one workload cannot access, or infer, data belonging to another workload), and for operational concerns (so the noisy neighbor effect of one workload cannot cause other workloads to run more slowly). Cloud instance providers (such as AWS EC2) face similar challenges, and have solved them using hypervisor- based virtualization (such as with QEMU/KVM [7, 29] or Xen [5]), or by avoiding multi-tenancy and offering bare- metal instances. Serverless and container models allow many more workloads to be run on a single machine than traditional instance models, which amplifies the economic advantages of multi-tenancy, but also multiplies any overhead required for isolation.
另外一些实现则是使用container: linux使用cgroup将各种名字空间做了隔离,使用seccomp-bpf来控制syscall. 如果我们要保证安全的话,那么就要限制某些syscall, 这个对于运行客户代码并不友好。所以实现高性能的vm还是挺关键的。
Typical container deployments on Linux, such as those using Docker and LXC, address this density challenge by relying on isolation mechanisms built into the Linux kernel. These mechanisms include control groups (cgroups), which provide process grouping, resource throttling and accounting; namespaces, which separate Linux kernel resources such as process IDs (PIDs) into namespaces; and seccomp-bpf, which controls access to syscalls. Together, these tools provide a powerful toolkit for isolating containers, but their reliance on a single operating system kernel means that there is a fun- damental tradeoff between security and code compatibility.
目前VM实现主要就是两类,qemu/kvm和xen. 其中qemu/kvm特性支持很好,但是启动速度很慢。
ther projects, such as Kata Containers [14], Intel’s Clear Containers, and NEC’s LightVM [38] have started from a similar place, recognizing the need for improved isolation, and choosing hypervisor-based virtualization as the way to achieve that. QEMU/KVM has been the base for the majority of these projects (such as Kata Containers), but others (such as LightVM) have been based on slimming down Xen. While QEMU has been a successful base for these projects, it is a large project (> 1.4 million LOC as of QEMU 4.2), and has focused on flexibility and feature completeness rather than overhead, security, or fast startup.
firecracker就是在这个基础上进行简化的,基于kvm但是没有使用qemu的代码,后面说到了用的是google实现的一个vm. 性能很好:启动时间在125ms以内(这个估计比程序初始化时间还少),每个实例5MB额外内存,能在一个物理机上创建150个micro vm. 这个项目github地址就是 Firecracker
With Firecracker, we chose to keep KVM, but entirely re- place QEMU to build a new Virtual Machine Monitor (VMM), device model, and API for managing and configuring Mi- croVMs. Firecracker, along with KVM, provides a new foun- dation for implementing isolation between containers and functions. With the provided minimal Linux guest kernel con- figuration, it offers memory overhead of less than 5MB per container, boots to application code in less than 125ms, and allows creation of up to 150 MicroVMs per second per host. We released Firecracker as open source software in December 20181, under the Apache 2 license. Firecracker has been used in production in Lambda since 2018, where it powers millions of workloads and trillions of requests per month.
这个项目主要还是为cloud service提供的micro vm. 没有了bios, 只跑linux, 没有pci等等,我记得里面可以提供一些控制接口方便外面调度来使用。
Firecracker is probably most notable for what it does not of- fer, especially compared to QEMU. It does not offer a BIOS, cannot boot arbitrary kernels, does not emulate legacy de- vices nor PCI, and does not support VM migration. Fire- cracker could not boot Microsoft Windows without significant changes to Firecracker. Firecracker’s process-per-VM model also means that it doesn’t offer VM orchestration, packaging, management or other features — it replaces QEMU, rather than Docker or Kubernetes, in the container stack. Simplic- ity and minimalism were explicit goals in our development process. Higher-level features like orchestration and metadata management are provided by existing open source solutions like Kubernetes, Docker and containerd, or by our propri- etary implementations inside AWS services. Lower-level fea- tures, such as additional devices (USB, PCI, sound, video, etc), BIOS, and CPU instruction emulation are simply not im- plemented because they are not needed by typical serverless container and function workloads.
3. isolation
这节谈到了一些隔离要求和实现方案,lxc, language vm(jvm), 以及virtualization. 这个是隔离要求以及性能要求:
- 安全隔离
- overhead小,可以在一个机器上提供多的vm.
- 性能可以
- 兼容性好,代码不要做修改
- 快速切换函数(我理解这个function是lambda?)
- 软分配,可以做overcommit. 我理解就是可以动态调节可以使用的资源
[!NOTE] Isolation: It must be safe for multiple functions to run on the same hardware, protected against privilege escalation, information disclosure, covert channels, and other risks.
Overhead and Density: It must be possible to run thou- sands of functions on a single machine, with minimal waste.
Performance: Functions must perform similarly to running natively. Performance must also be consistent, and iso- lated from the behavior of neighbors on the same hard- ware.
Compatibility: Lambda allows functions to contain arbi- trary Linux binaries and libraries. These must be sup- ported without code changes or recompilation.
Fast Switching: It must be possible to start new functions and clean up old functions quickly.
Soft Allocation: It must be possible to over commit CPU, memory and other resources, with each function consum- ing only the resources it needs, not the resources it is entitled to.
lxc和kvm之间架构区别如下,lxc最大的难点在于做好沙箱管理. Ubuntu 15.04有224 syscalls, 52 ioctl calls, /proc和/sys文件系统需要考虑,在这个层面上做安全控制很容易出问题,但是lxc最大的好处就是性能有保证,这个是直接去调用host kernel的。
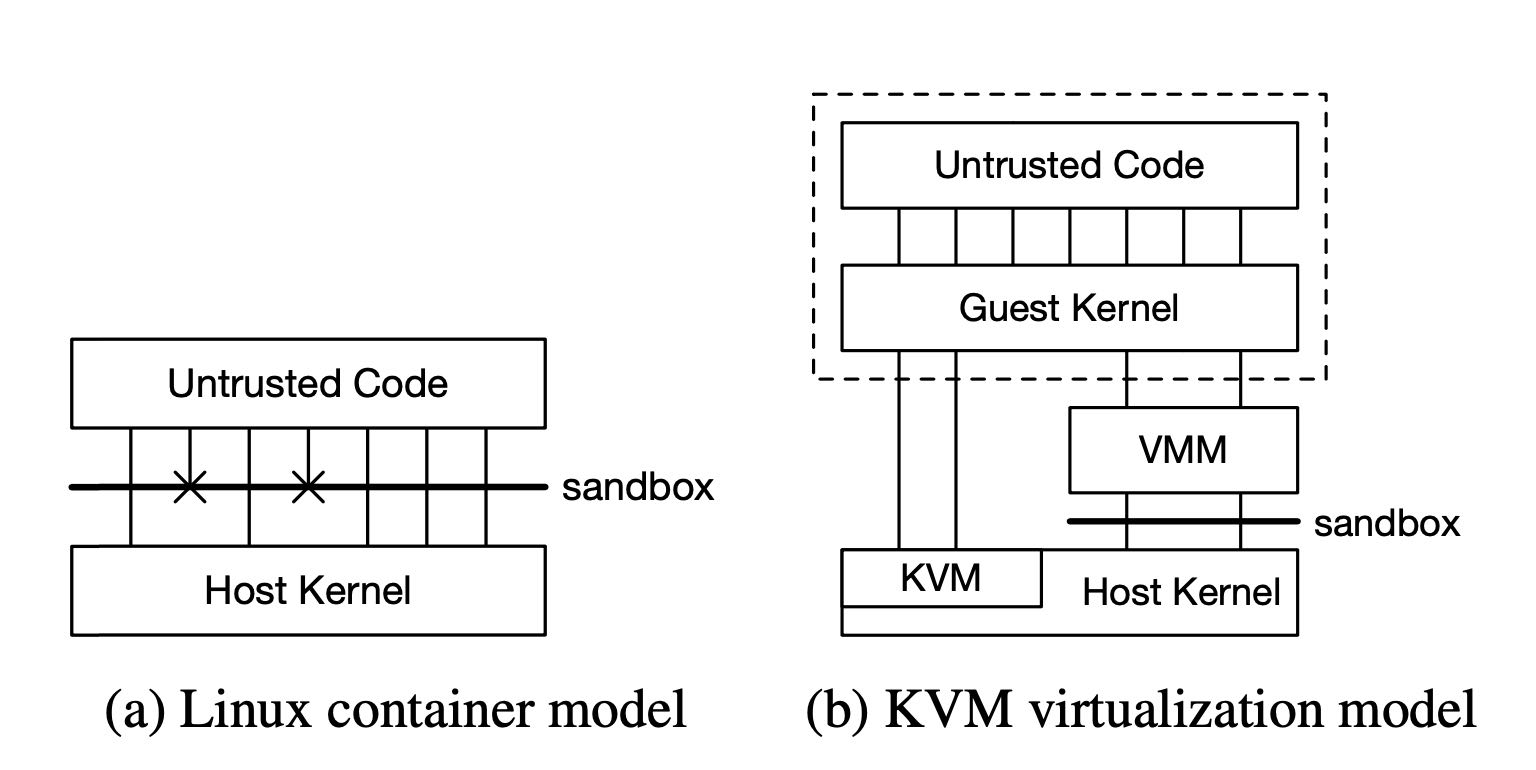
language vm的问题就是要改代码,这个代码兼容性太差,比如jvm要用java/scala这样的,而chrome则要用js或者是wasm这样的。这里的设计firecracker目标是要兼容所有的二进制文件。
虚拟化目前有两种实现方式,1类和2类虚拟机。1类是完全实现OS的功能,2类则是使用host os的功能。1类功能比2类要强大,但是实现难度也更大。好处就是可以在任意操作系统上模拟出任意的操作系统出来。
The third challenge in virtualization is the implementation itself: hypervisors and virtual machine monitors (VMMs), and therefore the required trusted computing base (TCB), can be large and complex, with a significant attack surface. This complexity comes from the fact that VMMs still need to ei- ther provide some OS functionality themselves (type 1) or depend on the host operating system (type 2) for function- ality. In the type 2 model, The VMM depends on the host kernel to provide IO, scheduling, and other low-level function- ality, potentially exposing the host kernel and side-channels through shared data structures.
我理解这里说的qemu就是实现1类虚拟机,可以看到工作量巨大(1,400,000代码),但是KVM在linux上只有(120,000)代码, x10.
To illustrate this complexity, the popular combination of Linux Kernel Virtual Machine [29] (KVM) and QEMU clearly illustrates the complexity. QEMU contains > 1.4 million lines of code, and can require up to 270 unique syscalls [57] (more than any other package on Ubuntu Linux 15.04). The KVM code in Linux adds another 120,000 lines. The NEMU [24] project aims to cut down QEMU by remov- ing unused features, but appears to be inactive.
firecracker同时保留了kvm和vmm, 但是重写了vmm这个部分(为啥要保留vmm这个部分呢?需要模拟出设备出来?). 我理解有点类似qemu/kvm的结构,但是没有用qemu这个部分的代码。保留了vmm的部分功能(可能这个部分的功能很关键)。
Firecracker’s approach to these problems is to use KVM (for reasons we discuss in section 3), but replace the VMM with a minimal implementation written in a safe language. Minimizing the feature set of the VMM helps reduce surface area, and controls the size of the TCB. Firecracker contains approximately 50k lines of Rust code (96% fewer lines than QEMU), including multiple levels of automated tests, and auto-generated bindings. Intel Cloud Hypervisor [25] takes a similar approach, (and indeed shares much code with Fire- cracker), while NEMU [24] aims to address these problems by cutting down QEMU.
4. firecracker vm
总体结构就是 fvm + kvm. fvm里面模拟出来了各种设备,还提供rest api进行控制
Firecracker is a Virtual Machine Monitor (VMM), which uses the Linux Kernel’s KVM virtualization infrastructure to pro- vide minimal virtual machines (MicroVMs), supporting mod- ern Linux hosts, and Linux and OSv guests. Firecracker pro- vides a REST based configuration API; device emulation for disk, networking and serial console; and configurable rate lim- iting for network and disk throughput and request rate. One Firecracker process runs per MicroVM, providing a simple model for security isolation.
Our other philosophy in implementing Firecracker was to rely on components built into Linux rather than re-im- plementing our own, where the Linux components offer the right features, performance, and design. For example we pass block IO through to the Linux kernel, depend on Linux’s pro- cess scheduler and memory manager for handling contention between VMs in CPU and memory, and we use TUN/TAP virtual network interfaces. We chose this path for two reasons. One was implementation cost: high-quality operating system components, such as schedulers, can take decades to get right, especially when they need to deal with multi-tenant work- loads on multi-processor machines. The implementations in Linux, while not beyond criticism [36], are well-proven in high-scale deployments.
实现上用的是google的crosvm. 里面去掉了USB和GPU的支持,只是9p文件系统协议,不知道这个9p文件系统是什么东西
In implementing Firecracker, we started with Google’s Chrome OS Virtual Machine Monitor crosvm, re-using some of its components. Consistent with the Firecracker philoso- phy, the main focus of our adoption of crosvm was removing code: Firecracker has fewer than half as many lines of code as crosvm. We removed device drivers including USB and GPU, and support for the 9p filesystem protocol. Firecracker and crosvm have now diverged substantially. Since diverging from crosvm and deleting the unneeded drivers, Firecracker has added over 20k lines of new code, and changed 30k lines. The rust-vmm project3 maintains a common set of open-source Rust crates (packages) to be shared by Firecracker and crosvm and used as a base by future VMM implementers.
在设备模型上,相比qemu, fvm只实现了几种必要的设备模型。在网络和块设备上,用的是virtio这个库,没有直接模拟文件系统是因为codebase比较大和复杂(这里不太明白模拟这些设备需要做哪些工作??)
Reflecting its specialization for container and function work- loads, Firecracker provides a limited number of emulated devices: network and block devices, serial ports, and partial i8042 (PS/2 keyboard controller) support. For comparison, QEMU is significantly more flexible and more complex, with support for more than 40 emulated devices, including USB, video and audio devices. The serial and i8042 emulation im- plementations are straightforward: the i8042 driver is less than 50 lines of Rust, and the serial driver around 250. The network and block implementations are more complex, reflecting both higher performance requirements and more inherent complex- ity. We use virtio [40, 48] for network and block devices, an open API for exposing emulated devices from hypervisors. virtio is simple, scalable, and offers sufficiently good over- head and performance for our needs. The entire virtio block implementation in Firecracker (including MMIO and data structures) is around 1400 lines of Rust.
We chose to support block devices for storage, rather than filesystem passthrough, as a security consideration. Filesys- tems are large and complex code bases, and providing only block IO to the guest protects a substantial part of the host kernel surface area.
cpuid可以进行配置,这样vm相当于可以运行在一个同构集群中。network/block device上配置rate limiter(in-memory token bucket). 允许在启动的时候有个one-time burst. 相比linux cgroup少了许多高级功能,但是这些对于firecracker其实都不太需要。
The machine configuration API allows hosts to configure the amount of memory and number of cores exposed to a MicroVM, and set up the cpuid bits that the MicroVM sees. While Firecracker offers no emulation of missing CPU func- tionality, controlling cpuid allows hosts to hide some of their capabilities from MicroVMs, such as to make a heterogeneous compute fleet appear homogeneous.
Firecracker’s block device and network devices offer built- in rate limiters, also configured via the API. These rate lim- iters allow limits to be set on operations per second (IOPS for disk, packets per second for network) and on bandwidth for each device attached to each MicroVM. For the network, separate limits can be set on receive and transmit traffic. Lim- iters are implemented using a simple in-memory token bucket, optionally allowing short-term bursts above the base rate, and a one-time burst to accelerate booting. Having rate limiters be configurable via the API allows us to vary limits based on configured resources (like the memory configured for a Lambda function), or dynamically based on demand. Rate limiters play two roles in our systems: ensuring that our stor- age devices and networks have sufficient bandwidth available for control plane operations, and preventing a small number of busy MicroVMs on a server from affecting the performance of other MicroVMs.
While Firecracker’s rate limiters and machine configuration provide the flexibility that we need, they are significantly less flexible and powerful than Linux cgroups which offer additional features including CPU credit scheduling, core affinity, scheduler control, traffic prioritization, performance events and accounting. This is consistent with our philosophy. We implemented performance limits in Firecracker where there was a compelling reason: enforcing rate limits in device emulation allows us to strongly control the amount of VMM and host kernel CPU time that a guest can consume, and we do not trust the guest to implement its own limits. Where we did not have a compelling reason to add the functionality to Firecracker, we use the capabilities of the host OS.
5. inside lambda
这节主要说如何在lambda里面使用fk. 都是一些lambda vm启动相关的细节问题,lambda worker结构体现了fk如何和lambda结合的。
fk启动micro vm之后,在kernerl image里面还提供了一个lambda shim的组件,这个东西是一个tcp服务,反过来可以用于控制fk.
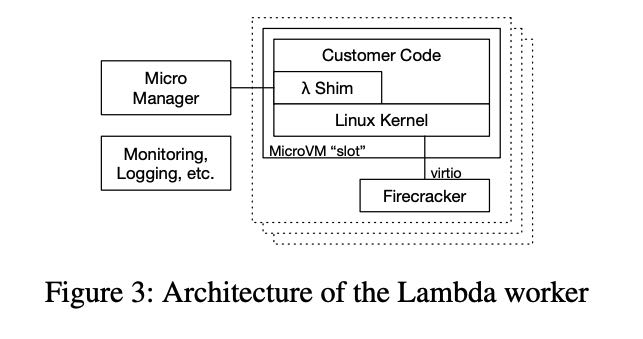
The shim process in each MicroVM communicates through the MicroVM boundary via a TCP/IP socket with the Micro- Manager, a per-worker process which is responsible for man- aging the Firecracker processes. MicroManager provides slot management and locking APIs to placement, and an event invoke API to the Frontend. Once the Frontend has been allocated a slot by the WorkerManager, it calls the MicroMan- ager with the details of the slot and request payload, which the MicroManager passes on to the Lambda shim running inside the MicroVM for that slot. On completion, the Mi- croManager receives the response payload (or error details in case of a failure), and passes these onto the Frontend for response to the customer.
lambda主要按照memory使用比例来计算价格,对于idle状态的lambda function只收取memory相关的费用,大约占40%左右。
Slots use different amounts of resources in each state. When they are idle they consume memory, keeping the function state available. When they are initializing and busy, they use memory but also resources like CPU time, caches, network and memory bandwidth and any other resources in the system. Memory makes up roughly 40% of the capital cost of typical modern server designs, so idle slots should cost 40% of the cost of busy slots. Achieving this requires that resources (like CPU) are both soft-allocated and oversubscribed, so can be sold to other slots while one is idle.
这里还说了一些oversubscription方面的理论,之前我在一个S3 talk上也看到过,但是有点不太明白具体意思。大致意思是,N个不相关的workload, 可以将X th/mean的ration(可以解释为multi-tenancy的经济系数)降低sqrt(N). 总之结果就是,越多不相关的workload放在一起,那么aws就能用越低的成本来满足Xth的延迟。