Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
Aurora本质上还是一个类MySQL的数据库,读写压力都在单机上,而不是一个真正意义上的分布式数据库。对于有副本(replica)的单机数据库而言,瓶颈通常可能不是CPU或者是内存,而是因为同步需要网络IO而造成的延迟。Aurora做的事情,就是将这个同步延迟降低到最低,同时保证可用性。另外Aurora采用了计算和存储分离的架构,这个架构首先是在Snowflake上看到的,我挺喜欢这个架构的。它比较符合云趋势,因为通常来说很难保证CPU/Memory/Storage能够最好地匹配起来。对于云厂商来说,这种架构也比较像他们内部开发分工,计算资源归计算部分,存储资源归存储部门。
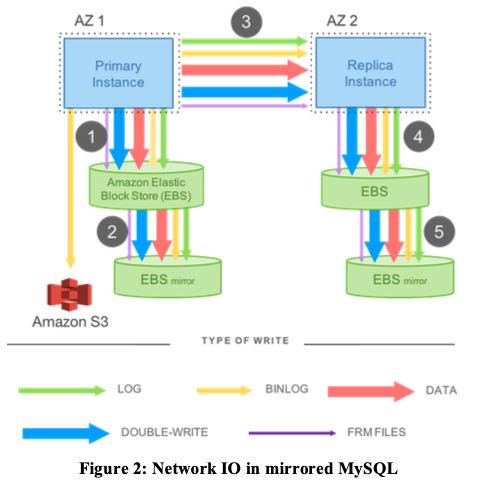
下图就是再有replication功能MySQL集群的架构图,可以看到数据其实是被写了5次的,写在了4个存储设备上。至于这个availability的话,那么就要看是同步还是异步写了。异步写可以保证性能,但是可用性就会受到损害。如果都是同步写的话,那么可以看到延迟是1 + 3 + 4 + 5(其中2可以被隐藏起来). 而且写的内容也比较多,其实比较大的是binlog, data 以及 double write(dirty page).
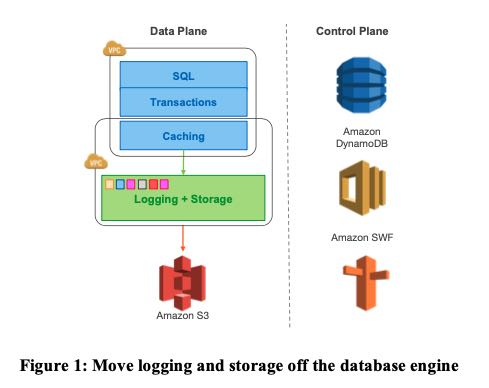
下图则是Aurora的结构图以及write path. 从结构上,将compute/storage进行拆分,计算层管理sql/tx, 而存储层则管理caching, logging 和 durable storage. 在写入路径上,由primary instance发起async write, 然后使用NRW quorum来保证一致性和可用性。并且这个async write的内容,只包括redo log. 相比MySQL同步的内容大小,就要小多了。
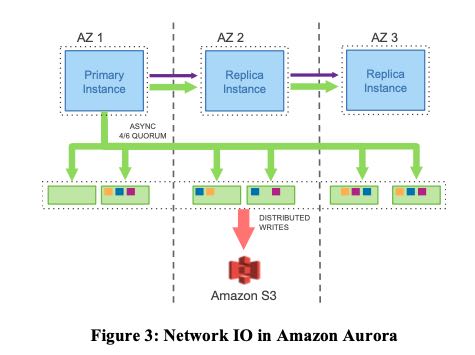
数据库卷(database volume)被拆分成为了多个segment, 每个segment是10GB,之所以这样拆分是为了方便出现数据损坏需要进行修复。如果没有被拆分成为segment的话,那么只要数据出现了一点问题,那么整个volume都需要进行修复,这个速度是比较慢的。但是拆分成为多个segment之后,一个segment出现问题,那么从protection group(PG)下面其他volume拷贝一个segment过来就行。在10Gbps网络环境下,通常这个时间就在10s左右。一个database volume上限就是EBS的上限64TB。一个PG就是3个AZs下面的6个EBS实例。
NRW的配置是(N=6, W=4,R=3). 其实这个R没有太大关系,因为如果从replica instance上去读的话,那么就是assume你可能会读到stalled数据,如果你想读到最新数据那么就要从primary instance读。这个R仅仅出现在crash recovery阶段,如果primary instance挂了的话,切换replica instance,如果要从replica instance对应的storage读的话,那么就需要确保这个storage上数据是最新的,这个时候才需要R读(针对每个segment进行R读)。W因为是async write, 所以延迟其实是可以躲避的。
既然计算和存储完全分离了,那么crash recovery也就非常迅速了。如果检测到primary instance挂掉之后,replica instance只要确保自己对应的storage是最新的,那么就可以立刻起来进行服务,而且因为caching也挪到了storage层面,大部分的内容也都在memory上面,所以也不会受到缓存的影响。事实上,replica storage在接收到redo log之后,就在不断地apply redo log到page上,为了确保为replica storage相比primary storage不会落下太多,primary instance会不断监控自己的log进度以及durabel log的进度(满足NRW要求的log的进度)。这篇paper在这块引入了相当多的名词:LSN(log sequence number), VCL(volume complete LSN,相当于连续日志的最高编号), CPL(Consistency Point LSN,满足一致性的编号), VDL(Volume Durable LSN,最高的CPL,也就是在这个点上确保数据是durable的).