A Typical Data Processing System
@2014-12-04
根据过去的工作经验,一个典型的数据处理系统应该是下面这个样子的
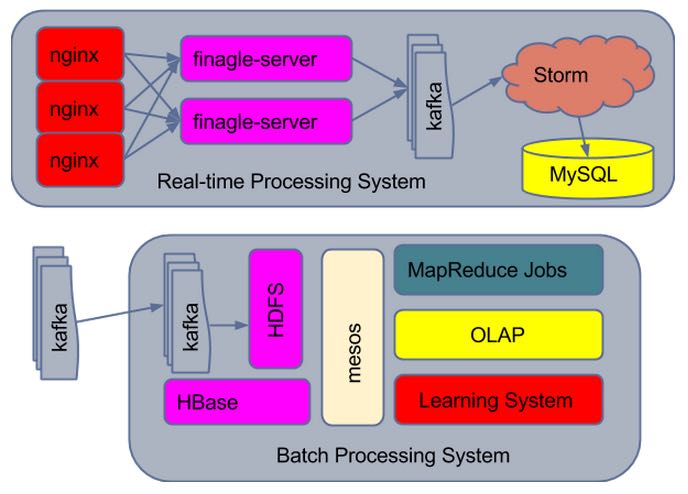
分为两个子系统realtime和batch. 两个子系统之间通过message system来互联. 如果realtime和batch不在同一个机房的话可以通过message system提供的mirror能力来做镜像. 展示给前端的计算结果需要同时merge两个子系统的databases(MySQL and HBase), 返回结果之前增加一个缓存层来减少对database的压力.
realtime system数据流是这样的:
- LVS/nginx # 请求通过LVS做负载均衡给http-server
- http-server/finagle-server # LVS通过反向连接将数据发送给http-server. http-server有两个工作 a)数据清洗 b)写入message system
- processor/storm # processor通过从message system里面读取数据进行计算然后写入database.
- database/MySQL # database存储processor计算结果. 可选方案分布式SSDB
重点关注: 系统稳定性和数据清洗正确性应该重点关注. 只要代码不是太烂, 系统配置正确的话, 延迟方面应该不会有太大问题.
batch system数据流是这样的:
- DFS/HDFS # 分布式文件系统, 存储各种数据
- DTS/HBase # 分布式表格系统. 存储一些加工数据, 或者是作为OLAP底层存储. 可选方案Cassandra.
- RM/mesos # 资源管理系统. 可选方案YARN.
- MapReduceJobs/Hadoop # mapreduce任务应该着重完成数据ETL工作比如为OLAP建立索引
- OLAP/(Impala, Presto, Hive, SparkSQL etc) # 数据查询工作比如select, join等, 数据报表. 注意这里的input dataset已经在raw dataset做了一些聚合丢失了部分信息, 不能用来做learning.
- LearningSystem/(Spark, MLlib etc) # 输入是raw dataset. 有迭代计算能力的系统.
重点关注: 系统扩展性, 吞吐率和利用率